The Harvard study showing AI outperformed two emergency room doctors on diagnostic accuracy. Meta's acquisition of a robotics startup. Anthropic reportedly raising at a $900B+ valuation. The OpenAI and Anthropic enterprise joint ventures.
The AI agent market is accelerating — and the pressure to ship is real. But the gap between "works in demo" and "works in production" is where most agentic projects stall. Not because the AI isn't capable enough, but because the engineering isn't ready.
This post is about the engineering practices that close that gap.
The Production Gap: Why Demos Lie
A demo agent works because the environment is controlled. Fixed prompts. Curated examples. Clean inputs. Predictable user behavior. The agent never encounters the chaos that real users create.
Production lies in wait:
User input chaos: users don't format their requests the way the demo assumed. They send images, voice transcripts, code snippets, entire documents, nothing at all. They ask follow-up questions that don't make sense. They contradict themselves across messages.
Context contamination: long-running sessions accumulate noise. Previous task context bleeds into new tasks. The agent's behavior drifts as the session grows.
Error cascades: a tool timeout triggers a retry, the retry fails, the agent makes a bad decision based on incomplete information, the user gets confused, the session degrades further.
Behavioral surprises: users discover agent behaviors the demo never revealed. "Wait, the agent can do that?" Edge cases cluster in production in ways that demos can't anticipate.
Practice 1: Stateless Session Initialization
Every session starts clean. Don't carry over state from previous sessions — not even "warm up" context from similar tasks.
Session start:
1. Load system prompt (stable, versioned)
2. Load user profile + preferences (if authenticated)
3. Load task-specific instructions (from routing)
4. Initialize session state (empty working memory)
5. Start fresh trace ID
Why this matters: session state from previous interactions can contaminate new tasks. A customer service agent that handled a billing dispute should not carry any of that context into a new product inquiry.
The exception: semantic memory (accumulated knowledge) persists across sessions by design. But episodic memory (session history) should be isolated per session.
Practice 2: Input Sanitization at the Boundary
The agent's input boundary is the first line of defense. Sanitize before the agent ever sees the input.
Format normalization: convert everything to a consistent format before processing. Rich text → plain text. Voice → transcription. Images → description + extracted text. PDF → text extraction.
Length constraints: enforce hard limits on input length. A 100,000-character user message is not a valid use case — it's a user testing your system or a potential injection vector.
Type validation: verify that inputs match expected types and structures. If the agent expects a JSON object, validate the structure before passing it in.
Injection detection: scan for adversarial patterns before the input reaches the agent. This is covered in depth in the security hardening post, but the boundary check is a prerequisite.
Practice 3: Task Scope Enforcement
Agents have scope creep. A customer service agent that can look up orders and issue refunds will eventually be asked to diagnose technical issues, process bulk returns, and escalate to legal. Each new capability adds complexity and risk.
Scope enforcement: explicitly define what the agent can and cannot do. Enforce these boundaries programmatically, not just through prompts.
Task: order_status_lookup
Allowed actions: [search_order, get_tracking, check_status]
Forbidden actions: [issue_refund, modify_order, cancel_subscription]
If requested: "I can help you track your order. For other requests, please contact our support team."
Capability routing: when a user request falls outside the agent's scope, route to a human or a different system. Don't let the agent attempt tasks it wasn't designed for.
Practice 4: Graceful Degradation
Production systems fail. The question isn't whether the agent will encounter a degraded state, but how gracefully it handles it.
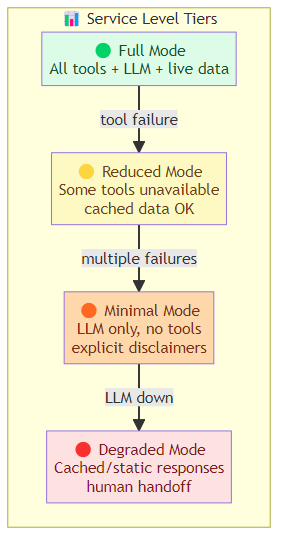
Define service levels: map your agent's degradation behavior to system states.
Full Mode: All tools available, full LLM capabilities, live data
→ Condition: Normal operation
Reduced Mode: Some tools unavailable, core LLM functional, cached data acceptable
→ Condition: Tool API degraded, downstream service partial outage
Minimal Mode: LLM only, no tools, explicit disclaimers
→ Condition: Multiple tool failures, cache exhausted
Degraded Mode: Cached/static responses, human handoff
→ Condition: LLM API degraded, core system failure
Always produce a response: the agent should never return an error to the user. If it can't complete the task, it should explain what it tried, what went wrong, and what the user should do next. Or escalate to a human.
Practice 5: Observability From Day One
Don't add observability after the fact. Instrument from the first line of code.
Minimum viable observability:
- Every LLM call: input tokens, output tokens, latency, model version
- Every tool call: tool name, arguments, result, latency, error
- Every session: start time, end time, outcome, task type
- Every failure: error type, error message, retry count, escalation
Session replay: store complete session state (not just the final output) for post-mortem analysis. When a user reports a problem, you need to reconstruct exactly what happened.
Behavioral baselines: establish what "normal" looks like for your agent. Success rate by task type, latency distribution, tool call patterns. Deviations from normal are your early warning signals.
Practice 6: A/B Testing Infrastructure
Don't ship new agent versions without the ability to roll back. Build A/B testing infrastructure before you need it.
Version 1 (control): 80% of traffic
Version 2 (treatment): 20% of traffic
→ Monitor for 24h
→ If treatment performs better (quality + cost + safety):
→ Roll to 100%
→ If treatment performs worse:
→ Roll back to 100% control
What to measure in A/B tests:
- Task success rate (primary)
- Cost per task (secondary)
- Escalation rate (safety)
- User satisfaction (if available)
- Error classification distribution (failure analysis)
Practice 7: Feedback Loop Architecture
Production agents improve over time — but only if you build the feedback loop. User feedback, task outcomes, error analysis — all of it should feed back into agent improvement.
Implicit feedback: task completion (did the user ask a follow-up? did they abandon the session?), time to resolution, escalation rate.
Explicit feedback: thumbs up/down, ratings, free-text feedback.
Failure analysis: every failed or degraded session gets reviewed. Root cause analysis. Test case creation. Prompt or tool updates.
Continuous improvement cycle: measure → analyze → improve → deploy → measure.
The Bottom Line
The gap between a demo agent and a production agent is engineering, not AI capability. The practices that close it:
- Stateless session initialization
- Input sanitization at the boundary
- Task scope enforcement
- Graceful degradation (always produce a response)
- Observability from day one
- A/B testing infrastructure before you need it
- Feedback loop architecture
Build these practices into the agent from the beginning, not as patches after deployment. The teams that ship reliable production agents aren't the ones with the best models — they're the ones with the best engineering discipline.
Related posts: AI Agent Harness Engineering — the four-layer harness architecture. Observability for AI Agents — the monitoring stack for production agents. Agentic AI Threat Models — security considerations for production deployment. Legal AI Agents — legal AI agents as an enterprise deployment case study. Forward-Deployed AI Engineering — the role that's winning enterprise AI.