Every AI engineering team has a version of the same story: the prototype demoed perfectly. The agent aced the carefully selected test cases. The investors were impressed. Then the agent hit production, and everything fell apart.
A customer support agent started looping. A code review agent started approving code with critical security vulnerabilities. A research agent started hallucinating citations that didn't exist. A data extraction agent started making up fields.
This isn't a model failure. It's a harness failure.
What Is an AI Agent Harness?
An AI agent harness is the infrastructure, scaffolding, and governance layer that surrounds an LLM and transforms it from a capable-but-unreliable text predictor into a reliable, measurable, controllable agentic system.
Think of it like this: a Formula 1 engine can produce 1,000 horsepower. But without the car around it — the transmission, suspension, aerodynamics, safety systems, telemetry — it's just a loud machine that destroys itself. The car is the harness. The same is true for AI agents.
The harness includes:
- State management — how the agent maintains context across turns, sessions, and failures
- Tool definition and execution — how tools are defined, called, sandboxed, and results returned
- Error handling and recovery — what happens when a tool call fails, the model hallucinates, or the agent loops
- Budgeting and circuit breakers — how you prevent infinite loops, runaway token consumption, and cascading failures
- Evaluation infrastructure — how you measure whether the agent is doing what you actually want
- Observability — how you understand what the agent is doing and why
- Security boundaries — how you prevent prompt injection, tool misuse, and data exfiltration
Why Harness Engineering Is the Hard Part
Here's the uncomfortable truth: building a capable agent is easy. Building a reliable one is extremely hard.
The gap between "can do it sometimes" and "can do it reliably at scale" is where most AI agent projects either succeed or quietly die. And that gap is almost entirely harness engineering.
The Reliability Problem
LLMs are stochastic. The same input can produce different outputs. An agent that works 80% of the time fails in production because:
- Edge cases weren't anticipated
- Error modes weren't handled
- Success criteria weren't defined precisely enough to measure
The harness is what closes the gap from 80% to 99.9%. It adds:
- Retry logic with exponential backoff for transient failures
- Fallback strategies when the primary approach fails
- Validation layers that check outputs before acting on them
- Human-in-the-loop checkpoints for high-stakes decisions
- Graceful degradation that provides useful output even when the agent struggles
The Evaluation Problem
You can't improve what you can't measure. And measuring agent quality is an order of magnitude harder than measuring model quality.
A model's output can be evaluated in isolation. An agent's quality depends on:
- How it handles the full task lifecycle (start to finish)
- How it responds to errors and recovers
- How it manages multi-step reasoning chains
- How it uses tools correctly and safely
- How it handles edge cases it wasn't explicitly trained on
Traditional ML evaluation metrics (loss, accuracy, F1) don't apply. You need harness-level evaluation infrastructure: replay buffers, scenario databases, golden outputs, automated pass/fail checks, and human preference feedback loops.
The Security Problem
Agents with tool access are attack surfaces. The harness is your first line of defense:
- Prompt injection: Malicious user inputs designed to manipulate agent behavior — the harness needs input sanitization and output validation
- Tool permission escalation: An agent that can only read files shouldn't be able to write — the harness enforces least-privilege access
- Context exhaustion: Adversarial inputs designed to overflow context windows — the harness manages context budget
- Data exfiltration: Agents accidentally or intentionally leaking sensitive data — the harness enforces data governance
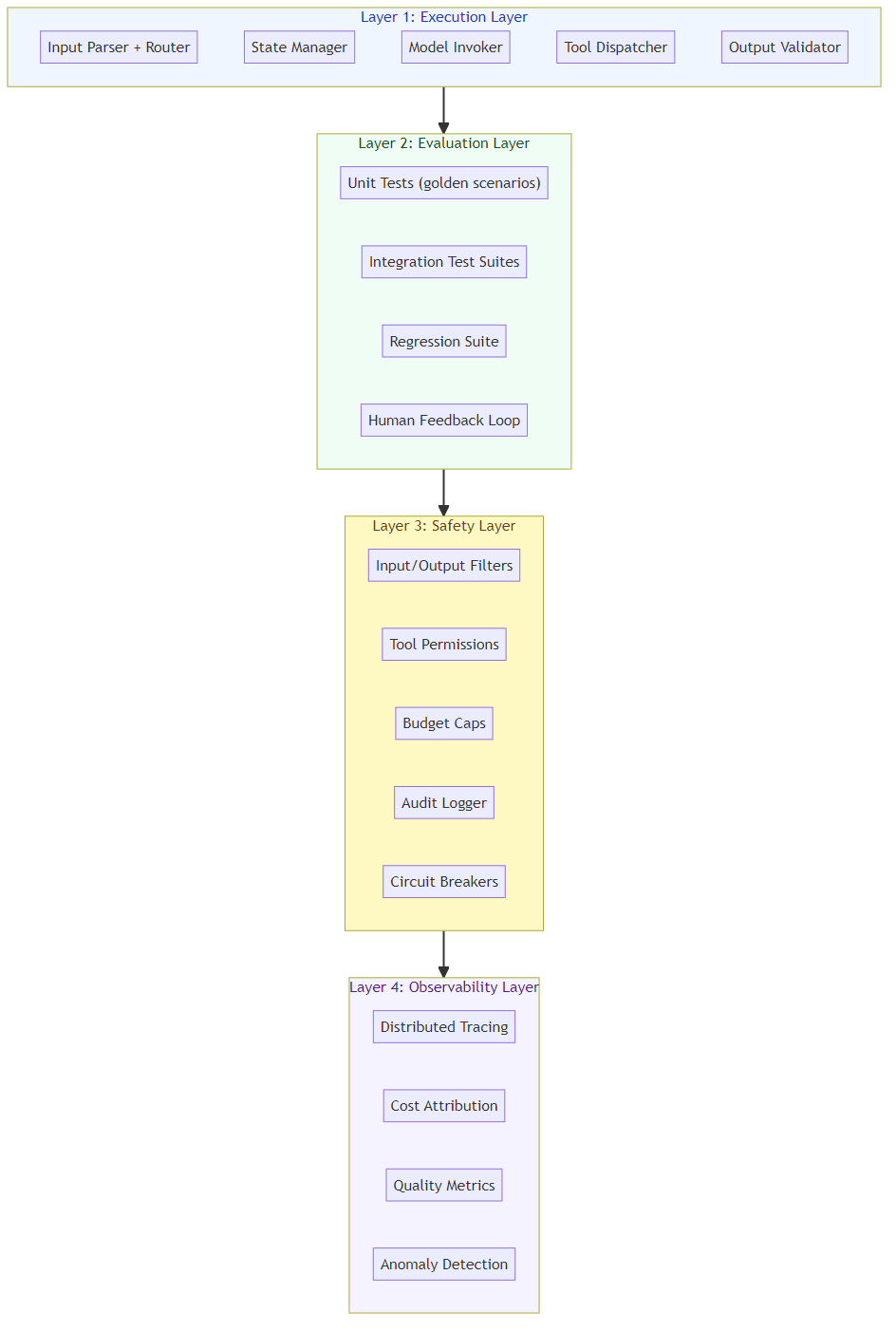
The Four Layers of a Production Harness
After studying dozens of production agentic systems, here's the framework I've found most useful for thinking about harness architecture:
Layer 1: The Execution Layer
The core loop that orchestrates the agent's operation:
- Input parsing and routing
- State management (session state, conversation history, artifacts)
- Model invocation (with caching, batching, routing)
- Tool dispatch and result aggregation
- Output validation and formatting
This is where most teams start. Frameworks like LangGraph, AutoGen, and CrewAI provide starting templates, but production systems almost always need custom execution layers.
Layer 2: The Evaluation Layer
Everything needed to measure and improve agent quality:
- Unit test equivalents: Small, focused scenarios with known correct outputs
- Integration test equivalents: Multi-step tasks that exercise the full agent pipeline
- Regression test suites: Collections of known-failure cases that should now pass
- Human feedback loops: Mechanisms for collecting and incorporating human preference
- Automated evaluation: LLM-as-judge pipelines, rule-based validators, behavior tests
The most effective harness teams build evaluation before capability. They define "done" first, then build toward it.
Layer 3: The Safety Layer
Governance mechanisms that prevent the agent from causing harm:
- Input/output filtering for sensitive content
- Tool permission boundaries enforced at runtime
- Rate limiting and budget caps
- Audit logging of all agent decisions and tool calls
- Human escalation pathways for uncertain or high-stakes decisions
This layer is often an afterthought. It shouldn't be. The cost of an agent that sends unauthorized emails, approves dangerous code, or leaks customer data far exceeds the cost of building safety in from day one.
Layer 4: The Observability Layer
Visibility into agent behavior that enables debugging, optimization, and improvement:
- Distributed tracing (every LLM call, every tool execution, every state transition)
- Cost attribution (per-user, per-request, per-task-type)
- Quality metrics (success rate, error rate, human override rate)
- Anomaly detection (looping, degradation, adversarial patterns)
- Behavioral analytics (what tasks is the agent handling well/poorly?)
Without observability, you're flying blind. You can't tell if the agent is improving, degrading, or simply behaving differently than expected.
The Competitive Moat
Here's what most teams miss: the harness isn't a commodity. It's a competitive moat.
Two teams can start with the same LLM. Team A spends two weeks building a basic agent. Team B spends two months building a production-grade harness with evaluation, safety, and observability built in. Six months later:
- Team A has gone through five "v2" rewrites, each breaking things the previous version fixed
- Team B has a reliable system with quantitative quality metrics, a growing test suite, and measurable improvements over time
The harness compounds. Every test case you add, every failure mode you fix, every observability improvement you make — it all accumulates into a system that's progressively harder to replicate.
Practical Steps for Harness Engineers
If you're building an agentic system and don't have a dedicated harness engineering practice, start here:
Week 1: Evaluation Infrastructure
- Define 20 "golden" test scenarios with known correct outputs
- Build a replay mechanism to run old scenarios against new versions
- Set up basic success/failure metrics
Week 2: Error Handling
- Add retry logic for tool calls (exponential backoff, 3 retries max)
- Implement graceful degradation: if tool X fails, fall back to tool Y
- Add circuit breakers: if error rate exceeds 10%, pause and alert
- Build a dead-letter queue for failed tasks
Week 3: Safety and Security
- Audit all tool permissions — does the agent need everything it has access to?
- Add input validation and output filtering
- Implement budget limits (max tokens per session, max tool calls per task)
- Add audit logging for all external actions (emails sent, data accessed, code executed)
Week 4: Observability
- Instrument every LLM call with trace IDs
- Log every tool call with input/output sizes
- Build a dashboard showing key metrics (success rate, latency, cost, error rate)
- Set up alerts for anomalous behavior (loop detection, token spike, error spike)
Ongoing: Coverage Expansion
- Add every production failure as a regression test
- Continuously expand the golden scenario set
- Run A/B tests between harness versions
- Monitor for emergent failure modes as the agent scales
The Bottom Line
The AI agent market is crowded with capable models. What's scarce is reliable agentic systems — agents that work at scale, fail gracefully, measure well, and improve over time.
That reliability doesn't come from a better LLM. It comes from better harness engineering.
For a guide to the next challenge — scaling your agentic system from POC to production at 100K+ users — see Scaling AI Agents: From Proof-of-Concept to Production.
Start treating your harness as a product, not a byproduct. Your agents — and your users — will thank you.
Related posts: AI Agents in Production — the 7 engineering practices for production deployment. Advanced Tool Use Patterns — tool orchestration and fallback strategies for production agents.


