You built a prototype. It worked beautifully — five users, clean data, predictable queries. You showed it to the team. They loved it. You opened it to more users.
At 100 users, things started getting slow. At 1,000, some sessions started failing. At 10,000, the system was unstable. At 100,000 — assuming you made it that far — you discovered problems that only emerge at scale.
This is the AI agent scaling problem. And it's fundamentally different from scaling traditional software.
Why Agentic Systems Scale Differently
Traditional web services scale by adding more servers and distributing stateless workloads. The architecture is well-understood: horizontal scaling, database read replicas, caching layers, message queues.
Agentic systems add layers that don't fit the stateless model:
Stateful by design: agents maintain conversation history, accumulated context, tool call results, and intermediate artifacts. You can't just spin up another instance — you need to distribute or replicate this state.
Context-dependent: the same agentic request can produce different results depending on what's in the context window. Scaling means managing not just throughput but context distribution.
Heterogeneous compute: serving a single agentic request may involve LLM inference (GPU-bound), tool execution (CPU-bound), and state management (memory-bound) on different infrastructure.
Token economics: every request has a token cost. Scaling linearly increases cost linearly. Unlike traditional services where marginal cost approaches zero, agentic scaling is expensive at every step.
The Scaling Challenges
Challenge 1: State Management at Scale
Every agent session needs state: conversation history, retrieved memories, tool call logs, intermediate results. For 100,000 concurrent users, you might have 100,000 active sessions.
Options:
Per-session database: each session is a row in a database. Fast to write, easy to query, scales with database. Latency: 5-20ms per state access.
In-memory session stores (Redis, Memcached): faster than databases (1-5ms), but session size is limited by memory. Good for compact sessions, problematic for long conversations with large context.
Tiered storage: hot data (recent conversation turns) in Redis, warm data (older history) in a database, cold data (archived sessions) in object storage. Most sessions fit in the hot/warm tier. Only the longest need cold storage.
Stateless by design: don't store conversation history server-side — pass it entirely in the request context. This works for short sessions but collapses for long ones.
The practical solution for most teams: Redis for hot session state with database persistence for durability and resumability.
Challenge 2: Context Window Limits
LLMs have finite context windows — 128K tokens, 1M tokens, whatever the limit is, it's finite. And the closer you get to the limit, the harder it is for the model to reason effectively.
For a system serving thousands of concurrent users with long conversations:
- Each user's context competes for space in the model's window
- Long conversations eventually exceed what the model can effectively use
- Serving many concurrent long-context users requires proportionally more model capacity
Solutions:
Semantic compression: identify and remove low-relevance context while preserving key information. This requires a retrieval or summarization model running alongside the agent.
Hierarchical memory: recent turns in fast storage, older turns compressed into summaries, very old turns in archival storage. The agent retrieves from each tier as needed.
Context budget enforcement: set hard limits on how much context a session can use. When the limit is reached, older context is compressed or evicted. This prevents any single session from monopolizing resources.
Model choice by session length: use a model with a larger context window for sessions that need it, with appropriate cost/latency tradeoffs.
Challenge 3: Concurrent Tool Execution
When you're serving 10 users, tool execution is simple: run one after another, sequentially. At 10,000 concurrent users, you might have hundreds of tool calls executing simultaneously.
The infrastructure needs to handle:
- Tool execution isolation: each tool call runs in a sandboxed environment that can't interfere with others
- Resource quotas: prevent any single tool call from consuming excessive CPU, memory, or network bandwidth
- Queue management: tool calls that can't execute immediately need to wait in queues with fair scheduling
- Timeout enforcement: runaway tool calls (infinite loops, hanging API calls) need to be killed before they exhaust resources
This is essentially a serverless execution problem. The solutions are similar: function-as-a-service runtimes, container pools with pre-warmed instances, or Kubernetes-based execution with autoscaling.
Challenge 4: Cost Control at Scale
Token costs scale linearly with usage. At 1M requests/month, token costs might be manageable. At 100M requests/month, they're a primary engineering concern.
Cost optimization strategies:
Aggressive model routing: most requests don't need the most capable (most expensive) model. Route 70-80% of requests to smaller, faster, cheaper models.
Token budget per session: cap the maximum tokens a session can consume. When the budget is exhausted, the session ends gracefully.
Caching: cache common tool results (the same search should return the same results within a short time window). Cache LLM responses where appropriate.
Request batching: group independent requests together for batch processing rather than real-time inference. Works for non-interactive workloads.
Cost attribution: track cost per user, per session, per task type. Identify which users or use cases are driving costs and optimize or charge accordingly.
Challenge 5: Geographic Distribution
Serving users globally requires the agentic system to be globally distributed. But:
- LLM inference is compute-intensive and typically runs in specific regions
- Tool execution may need to run close to the tools' infrastructure (database in EU, API in US)
- Session state needs to be accessible from multiple regions
The solution is a hybrid architecture: stateless request routing at the edge, with intelligent routing to the right inference region based on model availability, latency, and cost.
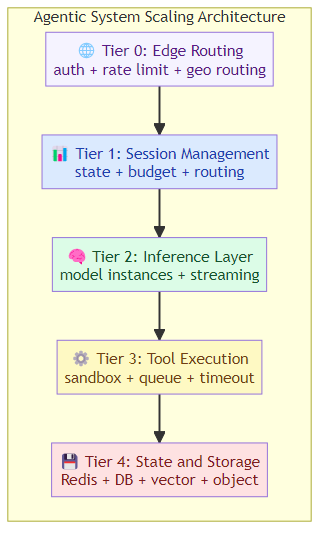
The Architecture Pattern That Works
After studying how leading teams scale agentic systems, a pattern emerges:
Tier 0: Edge Routing
Requests arrive at a global edge network. They're authenticated, rate-limited, and routed to the appropriate regional cluster based on user location, model availability, and load.
Tier 1: Session Management
Each user's session is managed by a session coordinator. The coordinator:
- Maintains session state (conversation history, memory, artifacts)
- Enforces token budgets and rate limits
- Routes requests to the right model
- Handles session resume/timeout
Tier 2: Inference Layer
LLM inference runs in the regional cluster. This layer:
- Manages model instances (GPU allocation, auto-scaling)
- Handles streaming responses
- Implements model routing and fallback
Tier 3: Tool Execution Layer
Tool calls are dispatched to an execution runtime:
- Code execution in containerized sandboxes
- API calls through a managed gateway with retries and circuit breakers
- Database queries with connection pooling and query limits
Tier 4: State and Storage
Persistent state lives in:
- Redis for hot session data
- Database for durable session records and user data
- Vector store for semantic memory
- Object storage for artifacts
Scaling Metrics That Matter
Forget vanity metrics. These are the numbers that actually tell you whether your agentic system is scaling well:
- Concurrent session capacity: how many simultaneous users can you handle?
- P99 inference latency: what's the 99th-percentile time for a complete agentic request?
- Cost per successful task: what's the average token + compute cost per completed task?
- Tool call error rate: what percentage of tool calls fail, and why?
- Session abandonment rate: how often do users abandon sessions before completion (often correlates with latency or reliability issues)?
- Context utilization: how much of available context are sessions actually using?
The Common Scaling Mistakes
Mistake 1: Starting with a monolithic design and trying to distribute it later. It's much harder to add distribution to an existing system than to design for distribution from the start.
Mistake 2: Underestimating tool execution cost. Teams budget for LLM inference and forget that tool execution (especially code execution and database queries) can be equally expensive.
Mistake 3: Not implementing per-user limits. Without fair-use limits, a small number of heavy users can destabilize the system for everyone.
Mistake 4: Ignoring cold start latency. Containerized tool execution environments have cold start times that can add seconds to first tool calls.
Mistake 5: Building for peak load. Designing for peak capacity is expensive. Design for average load with graceful degradation, and shed low-priority traffic during spikes.
The Journey: Proof-of-Concept to Production
Stage 1 (0-100 users): single-region, single-model, in-memory sessions. Focus on getting the agent working reliably. Don't optimize prematurely.
Stage 2 (100-1,000 users): add session persistence, implement rate limiting, start cost tracking. Introduce model routing for simple tasks.
Stage 3 (1,000-10,000 users): multi-region routing, tiered state management, containerized tool execution, comprehensive monitoring.
Stage 4 (10,000-100,000 users): full observability, sophisticated cost attribution, automated scaling, A/B testing of agent versions.
Stage 5 (100,000+ users): dedicated infrastructure teams, specialized model serving, continuous optimization, and — honestly — problems you didn't know you'd have until you got there.
The Bottom Line
Scaling AI agents isn't just about adding more compute. It's about managing stateful workloads with context limits, heterogeneous compute requirements, and linear cost scaling.
The teams that succeed start with the right architecture (session management, tiered storage, isolated tool execution), implement the right safeguards (rate limiting, budget enforcement, graceful degradation), and measure the right things (latency, cost per task, error rates).
Scale is a journey, not a destination. Build for where you are, design for where you're going, and measure everything.
Related posts: AI Agent Infrastructure Readiness — the foundational infrastructure components. Real-Time Inference for AI Agents — latency optimization strategies. The Missing Discipline: AI Agent Harness Engineering — evaluation and observability for production agents.