A human customer service agent, halfway through a complex dispute, can look back at what the customer said five minutes ago. An AI agent needs the same capability — but implemented very differently.
The agent's memory isn't a transcript. It's a dynamic, queryable store of accumulated knowledge that needs to surface the right information at the right time, without overwhelming the context window or degrading over long conversations.
This is the agent memory architecture problem. And it's one of the most underappreciated engineering challenges in agentic AI.
Why Agent Memory Is Different from Chat History
Traditional chatbots store conversation history as a simple list of messages. This works for short interactions but collapses for agentic systems that run for hours, days, or weeks.
Agent memory has different requirements:
Query-based retrieval: agents need to recall specific facts, not just replay the last N messages. "What did the customer mention about their previous order?" requires semantic search, not sequential replay.
Variable retention periods: some information should persist for the session (current task state), some for weeks (customer preferences), and some indefinitely (learned domain knowledge). Different memory types have different retention policies.
Capacity management: a long-running agent accumulates thousands of facts. The agent can't retrieve everything — it needs to surface only the relevant subset.
Semantic evolution: knowledge that was true yesterday may be obsolete. Memory systems need to handle knowledge updates, corrections, and decay.
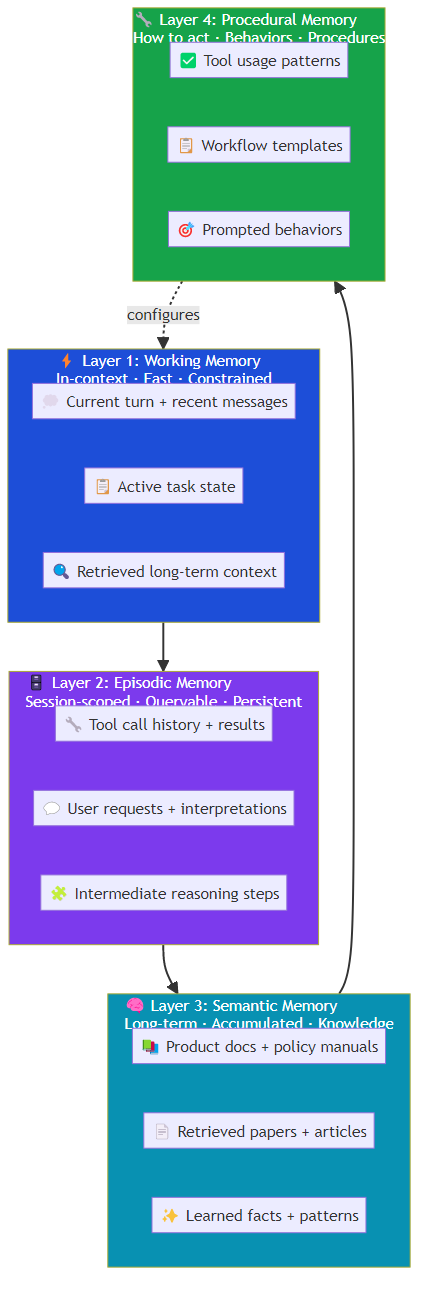
The Four-Layer Memory Architecture
Production agentic systems implement memory as a layered architecture, with each layer optimized for different access patterns:
Layer 1: Working Memory (In-Context)
The context window — what's actively accessible to the LLM during inference. This is the fastest layer but also the most constrained.
Working memory typically contains:
- Recent conversation turns (last 5-20 messages)
- Active task state (what the agent is currently working on)
- Retrieved context from long-term memory
- Tool call results from the current session
The challenge: determining which information in the context window is actually useful vs. noise. Too much context degrades reasoning quality; too little causes the agent to lose critical context.
Effective working memory management requires:
- Prioritization: surface the most relevant recent context first
- Summarization: compress long conversations into distilled summaries
- Filtering: remove low-relevance content before it consumes context budget
Layer 2: Episodic Memory (Session-Scoped)
Memory of specific events or interactions within a session. Unlike working memory, episodic memory persists across the session and can be queried retrospectively.
Episodic memory stores:
- Tool call results and their implications
- User requests and how they were interpreted
- Intermediate reasoning steps
- Decisions made and their rationale
The key architectural decision: should episodic memory be stored in the context (and thus consume token budget) or as external state (queried on demand)? The tradeoff is retrieval latency vs. context consumption.
For practical implementations: episodic memory lives in a fast external store (Redis), with recent episodes loaded into context on demand.
Layer 3: Semantic Memory (Long-Term Knowledge)
The agent's accumulated knowledge base — facts, patterns, and learned relationships that persist across sessions.
Semantic memory is the closest analog to how humans store declarative knowledge. It's queryable, updatable, and can be structured (knowledge graphs) or unstructured (vector embeddings).
Sources of semantic memory:
- Structured knowledge bases: product documentation, policy manuals, FAQ databases
- Retrieved documents: papers, articles, technical documentation
- Learned from interactions: facts extracted from conversations, patterns identified over time
- Pre-trained knowledge: what the LLM already knows (with appropriate confidence calibration)
The retrieval challenge: semantic memory is only useful if the agent can retrieve the right facts at the right time. This requires sophisticated retrieval infrastructure — vector search, knowledge graphs, hybrid retrieval pipelines.
Layer 4: Procedural Memory (How to Act)
The agent's knowledge of how to do things — prompted behaviors, tool usage patterns, workflow templates, and learned procedures.
Procedural memory encodes the "how" rather than the "what":
- How to handle a refund request
- How to escalate to a human agent
- How to interpret ambiguous user requests
- How to structure a research task
This is often implicit in the agent's system prompt, but advanced systems make procedural memory explicit and updateable — learning from successful interactions which procedures work best for which task types.
The Retrieval Pipeline
Having a multi-layered memory architecture is only useful if the agent can retrieve from it effectively. The retrieval pipeline is where most memory systems struggle.
Vector-Based Retrieval
The dominant approach: embed all memory entries as vectors, retrieve based on semantic similarity.
Strengths:
- Handles natural language queries naturally
- Captures conceptual similarity even when phrasing differs
- Scales well with large memory stores
Weaknesses:
- Similarity search doesn't guarantee relevance
- Dense retrieval misses exact matches
- Requires managing embedding models and vector stores
Knowledge Graph Retrieval
For structured knowledge: maintain a knowledge graph with entities, relationships, and attributes. Retrieve via graph traversal or subgraph matching.
Strengths:
- Precise, interpretable retrieval
- Supports multi-hop reasoning (follow relationships)
- Handles structured queries (count, compare, rank) well
Weaknesses:
- Requires structured data or extraction pipeline
- Graph maintenance overhead
- Cold start problem for new domains
Hybrid Retrieval
The most effective approach combines vector search (for semantic similarity) with keyword search (for exact matches) and structured queries (for factual lookups).
The retrieval pipeline:
- Query decomposition: break complex queries into sub-queries
- Multi-retriever execution: run vector, keyword, and structured queries in parallel
- Result fusion: merge and rerank results based on combined signals
- Context loading: load top-K results into the context window with source attribution
The Knowledge Consolidation Problem
As agents accumulate knowledge over time, memory stores grow. Without management, retrieval degrades — the relevant fact gets buried under thousands of irrelevant entries.
Knowledge consolidation addresses this:
Forgetting and Decay
Not all knowledge is equally valuable. Over time, some facts become obsolete, redundant, or contradicted. Effective memory systems implement:
- Temporal decay: reduce the weight of older memories unless reinforced
- Relevance decay: demote facts that haven't been retrieved recently
- Contradiction detection: when new information conflicts with old, flag for review
Consolidation and Generalization
When the agent learns many specific facts, it can consolidate them into general principles:
- "Customer in region X prefers option Y" + "Customer in region Z prefers option Y" → "Option Y is generally preferred by customers"
- "Tool A failed with error X" + "Tool A failed with error Y" → "Tool A has reliability issues under certain conditions"
Compression
Long-term memory entries can be compressed — removing details that aren't useful for retrieval while preserving the essential information.
Memory as a First-Class Architectural Concern
Most agent development treats memory as an afterthought: start with context window, add a vector store when context gets too full. This leads to systems that work well in demos and fail in production.
The better approach: design the memory architecture upfront, with explicit decisions about:
- What each layer stores and for how long
- How retrieval is triggered and constrained
- How memory evolves and updates over time
- What the cost/performance tradeoff looks like as memory grows
Memory isn't a feature. It's the foundation of a capable agent.
The Bottom Line
Agent memory is a layered architecture — working memory for what's immediately needed, episodic memory for session history, semantic memory for accumulated knowledge, and procedural memory for how to act. The retrieval pipeline that connects these layers is where the engineering complexity lives.
The teams building reliable agentic systems invest in retrieval infrastructure as much as they invest in model capabilities. Because ultimately, an agent is only as good as what it can remember and retrieve.
Related posts: Memory Systems for AI Agents — the foundational memory patterns. Agentic RAG — extending retrieval to agentic workflows. Planning in AI Agents — how memory enables goal-directed reasoning.


