
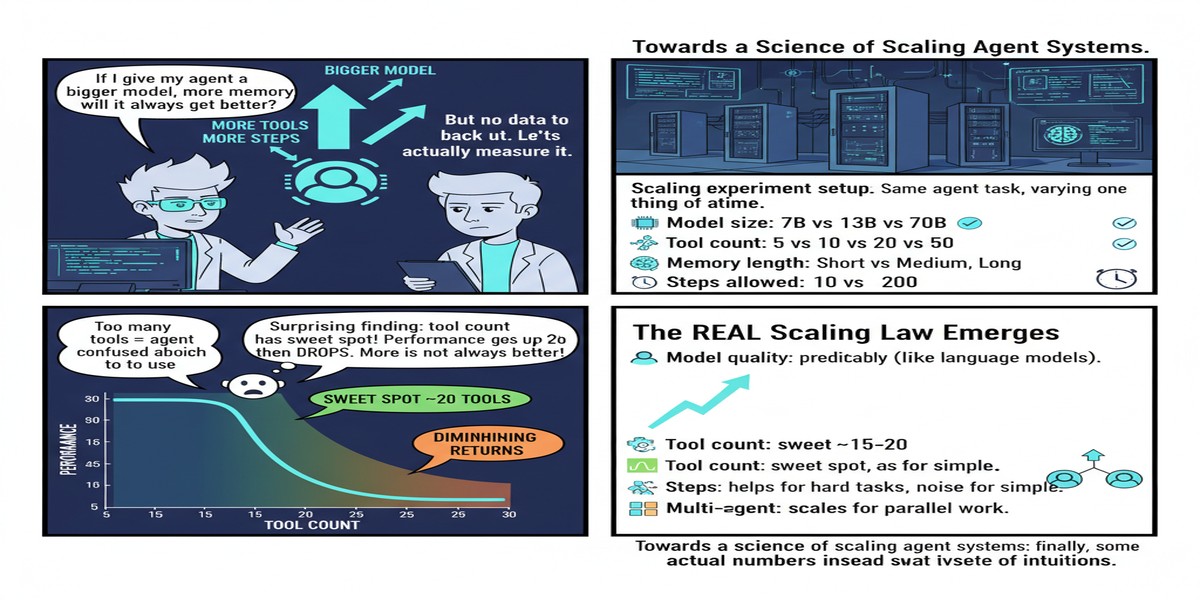
There's a frustrating pattern in the agent systems space: everyone has opinions, very few people have data. "Use a supervisor agent!" "Decentralize your agents!" "Throw more agents at the problem!" These recommendations float around with great confidence and minimal empirical grounding. The December 2025 paper Towards a Science of Scaling Agent Systems is the first serious attempt I've seen to actually measure what happens when you scale agent systems — and the results will surprise you.
Paper: Towards a Science of Scaling Agent Systems Authors: Yubin Kim, Ken Gu, Chanwoo Park, et al. (19 authors, multi-institution) Published: arXiv:2512.08296, December 2025
The Setup
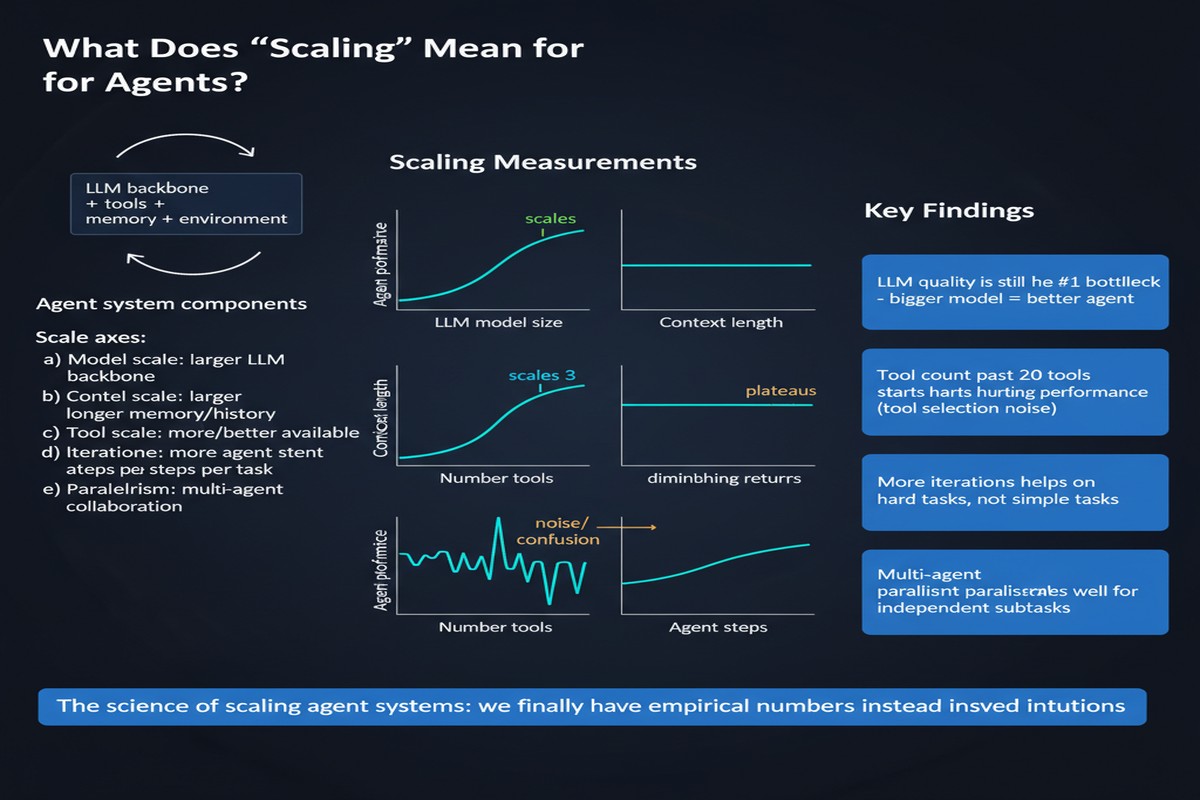
The team evaluated five architectural designs across 180 configurations using multiple benchmarks. This is not a toy study — 180 configurations is enough to actually draw statistical conclusions. They varied:
- Number of agents (1 to N)
- Coordination topology (centralized, decentralized, hierarchical, peer-to-peer, independent)
- Model capability (weaker and stronger base models)
- Task type (tool-intensive, web navigation, sequential reasoning, parallelizable)
- Budget constraints
The result is a predictive framework that can recommend optimal coordination for a given task type. They claim 87% accuracy on held-out test cases, which is good enough to be practically useful.
The Key Findings
The paper's headline findings are worth unpacking carefully because they cut against conventional wisdom:
Finding 1: Tool-intensive tasks suffer from multi-agent overhead under fixed budgets
If your task requires heavy tool use — database queries, API calls, file operations — adding more agents under a fixed compute budget actually hurts performance. The coordination overhead and token cost of managing inter-agent communication eats into the budget that would be better spent on single-agent depth.
This is the "more agents = better" assumption getting killed empirically.
Finding 2: Performance gains from coordination diminish once single-agent capability exceeds ~45%
There's a threshold effect. When your base model is weak (can solve fewer than ~45% of tasks alone), adding coordination structures helps significantly. When your base model is strong, multi-agent overhead costs more than you gain from parallelism.
This has a direct practical implication: if you're using GPT-5 or Claude Opus class models, you may be leaving performance on the table by adding a complex multi-agent architecture where a single well-orchestrated agent would do better.
Finding 3: Independent agents amplify errors more than centralized systems
Decentralized agents making independent decisions create error amplification — each agent's mistakes compound without a correction mechanism. Centralized coordination, despite its overhead, catches errors earlier.
graph TD
subgraph Centralized Coordination
O[Orchestrator] --> A1[Agent 1]
O --> A2[Agent 2]
O --> A3[Agent 3]
A1 -- result --> O
A2 -- result --> O
A3 -- result --> O
O -- correction --> A1
O -- correction --> A2
end
subgraph Decentralized
B1[Agent 1] --> B2[Agent 2]
B2 --> B3[Agent 3]
B1 --> B3
end
Note1["Error caught, corrected\nby orchestrator"] -.-> O
Note2["Error amplified\nacross chain"] -.-> B3
Finding 4: Centralized coordination boosts parallelizable tasks by ~81%
For tasks that genuinely decompose into independent subtasks — think parallel research, parallel code generation for independent modules, parallel analysis — centralized coordination gives you a massive benefit. The 81% improvement figure is striking.
Finding 5: Decentralized approaches excel at web navigation
For web navigation tasks, decentralized coordination outperforms centralized. The hypothesis is that web navigation requires rapid local adaptation, and the latency of central coordination creates bottlenecks. This is a domain-specific exception that proves the general rule.
The Predictive Model
What makes this paper practically valuable is the predictive framework. They formalize agent system performance as a function of:
flowchart LR
A["Task Type\n(parallel/sequential/\ntool-intensive/web)"] --> P[Predictive Model]
B["Agent Count\n(N)"] --> P
C["Coordination\nTopology"] --> P
D["Base Model\nCapability"] --> P
E["Budget\nConstraints"] --> P
P --> F["Predicted\nPerformance"]
P --> G["Recommended\nArchitecture"]
The ability to predict optimal coordination topology at 87% accuracy means you can use this framework to make architecture decisions before spending on expensive experimentation. That's genuinely useful for teams building production agentic systems.
Why This Matters
I've been arguing for a while that the agentic AI space needs to move from architecture philosophy to architecture science. Too many teams are making expensive decisions based on intuition, analogy, or the persuasive demo their vendor showed them.
This paper is the first real step toward a quantitative foundation for agent architecture decisions. The fact that you can now say "for this task type, at this model capability level, under this budget, the data predicts centralized coordination will outperform decentralized by X%" is a meaningful advance.
The sequential reasoning finding is particularly important. The paper found that sequential reasoning tasks showed performance degradation across all multi-agent variants. If you're building a complex multi-step reasoning system, adding more agents is likely making it worse. This explains why a lot of sophisticated agentic reasoning pipelines underperform simpler single-agent chains of thought — the coordination costs and error amplification eat the gains.
What's Missing
The paper has limitations worth acknowledging. The 180-configuration study, while large by academic standards, doesn't cover the full diversity of production workloads. The task types they benchmark are relatively clean — real production tasks are messier and harder to categorize.
The predictive model also doesn't account for agent specialization well. In practice, multi-agent systems often benefit not just from parallelism but from having agents with genuinely different capabilities and training. That dimension isn't fully captured.
And 87% predictive accuracy is good, but 13% of the time you're getting bad architecture advice. In high-stakes production deployments, that failure rate matters.
My Take
This is one of the most practically useful papers I've read on agent systems. Not because it tells you the answer, but because it gives you a framework for finding the answer for your specific situation.
The death of "more agents = better" as a default assumption is overdue. I've watched teams build elaborate multi-agent architectures that were slower, more expensive, and less reliable than a well-designed single-agent system. This paper validates what many of us suspected from practice: the right architecture is task-dependent, budget-dependent, and model-dependent.
The finding about single-agent capability thresholds is the most important practical insight. If your base model is strong, invest in better prompting, better tools, and better scaffolding before you invest in multi-agent coordination. The marginal returns to coordination plummet above the ~45% solo-performance threshold.
My criticism: the paper stops short of a full prescriptive framework. They show you what correlates with performance; they don't fully explain the mechanistic reasons why. Understanding why centralized coordination helps parallelizable tasks but hurts sequential tasks would let us build better theory and make better predictions in novel domains.
Still, this is foundational work. Every engineering team building agent systems should read it before finalizing their architecture.
Further Reading
- arXiv: 2512.08296
- Related: ARE: Scaling Up Agent Environments (2509.17158) for a complementary evaluation framework
- Related: Multi-Agent Collaboration Mechanisms survey (2501.06322) for broader coordination taxonomy


