
The way most agent frameworks handle memory is, frankly, embarrassing. Store everything in a vector database. Retrieve top-K by cosine similarity. Hope the right chunks show up at the right time. This approach treats memory as a passive lookup system when what agents actually need is active, intelligent memory management — knowing not just what to store, but when to store it, when to update it, when to discard it, and when to consolidate it.
The January 2026 paper introducing AgeMem takes this seriously. It's not a perfect solution, but it's a meaningful step toward memory as a first-class capability in agent systems.
Paper: Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents Authors: Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, Libing Wu Published: arXiv:2601.01885, January 2026
The Problem With Memory Today
Before getting into AgeMem, it's worth diagnosing why current agent memory systems are inadequate.
The dominant paradigm is Retrieval-Augmented Generation (RAG): you store information as embeddings, and when the agent needs context, you retrieve the most semantically similar chunks. This works for a narrow class of use cases — answering questions about a fixed corpus of documents, for example. It fails for agents for several reasons:
Static retrieval vs. dynamic need. Agents don't know what they'll need in advance. The information relevant to step 47 of a 100-step task depends on decisions made in steps 1-46. Similarity-based retrieval can't anticipate this.
No consolidation. Raw storage accumulates everything, including redundant, superseded, and irrelevant information. Agents slowly drown in their own context.
No forgetting. Human working memory has a forgetting curve for good reasons. Agents that remember everything equally weight a fact from three months ago the same as an observation from five minutes ago.
No metacognition about memory. Current agents can't reason about what they know, what they've forgotten, or whether their memory is reliable. They just retrieve and hope.
flowchart LR
subgraph Traditional RAG Memory
T1[New Information] --> S[Embedding Store]
Q[Query] --> R[Cosine Similarity Retrieval]
S --> R
R --> A[Agent]
end
subgraph AgeMem Approach
T2[New Information] --> AG[Agent decides:\nStore? Update?\nSummarize? Discard?]
AG --> LTM[Long-term Memory]
AG --> STM[Short-term Memory]
LTM --> AG
STM --> AG
AG --> A2[Agent]
end
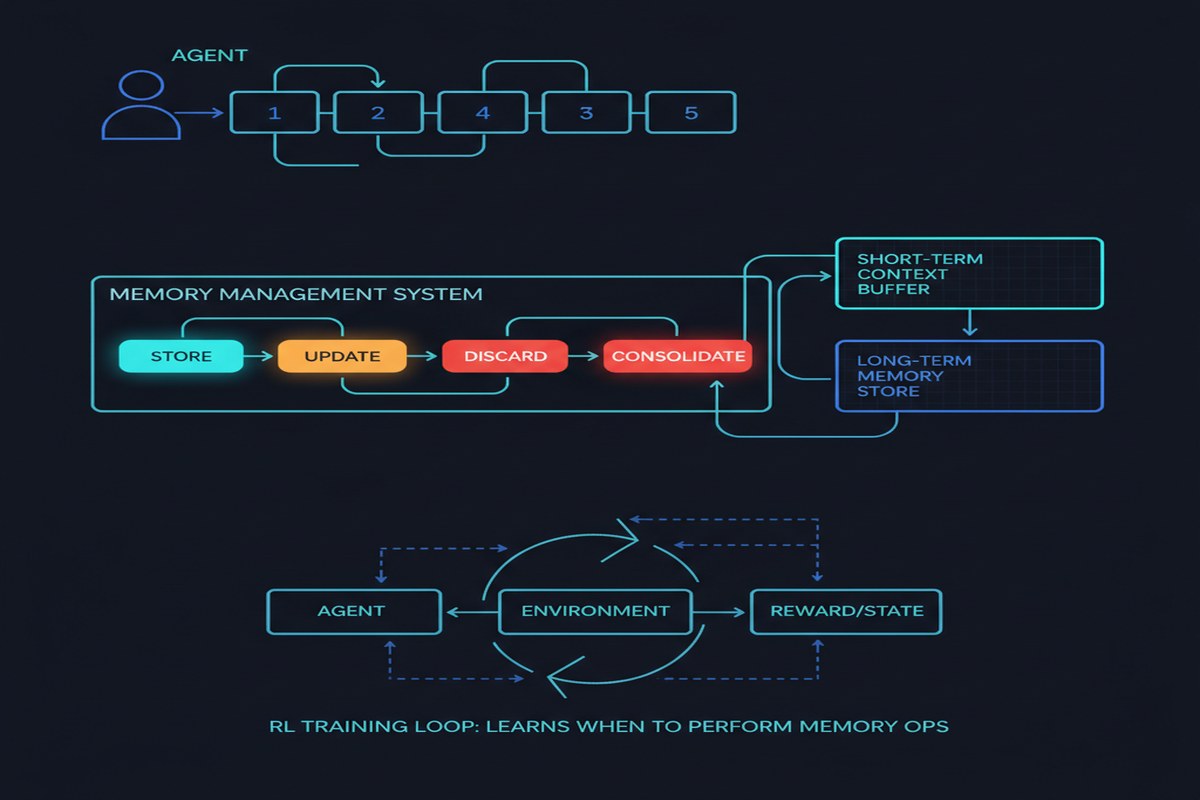
What AgeMem Does Differently
AgeMem treats memory operations as learnable agent actions. Instead of memory being infrastructure the agent passively uses, memory management becomes part of the agent's learned policy.
The framework defines five memory operations as explicit actions the agent can take:
- Store — add new information to long-term memory
- Retrieve — pull relevant information into working context
- Update — modify an existing memory in light of new information
- Summarize — compress a cluster of related memories into a more efficient representation
- Remove — discard information that is no longer relevant or has been superseded
The agent learns through a three-stage progressive RL strategy:
Stage 1: Individual operations. The agent is trained to perform each memory operation correctly in isolation. Get the store/update/remove/summarize primitives right before composing them.
Stage 2: Operation sequences. The agent learns to chain memory operations correctly — when updating should follow storage, when summarization should precede removal.
Stage 3: Full task integration. Memory management is trained end-to-end as part of task completion. The reward signal is task success, not memory quality per se, which means the agent learns memory patterns that actually help it accomplish goals.
The paper also introduces a specialized RL technique for handling the sparse and discontinuous rewards that memory management creates. Memory operations often don't have immediate payoffs — you store something in step 3 that becomes critical in step 47. Standard RL struggles with this temporal gap. Their step-wise GRPO approach addresses this by propagating reward signals backward through memory operation sequences.
The Results
AgeMem is evaluated across five benchmarks covering conversational agents, task completion, and long-horizon reasoning. The improvements are real and meaningful:
- Task success rates improve across all benchmarks
- Memory quality (measured by a separate evaluator) improves significantly
- Context efficiency improves — agents maintain better performance with smaller effective context windows
- Generalization holds across different base LLMs, suggesting the approach isn't model-specific
I don't want to quote specific numbers here because the benchmarks vary significantly in what they measure, and headline numbers can be misleading. The consistent pattern across benchmarks is more meaningful than any single figure.
Why This Matters
The long-context window race has been the dominant answer to the memory problem: "just make the context window bigger." Gemini 1.5's million-token context, Claude's 200K, GPT-4 Turbo's 128K — the implicit assumption is that if you can fit everything in context, you don't need sophisticated memory management.
This is wrong, and AgeMem helps explain why.
Even with massive context windows, agents still need to reason about what to attend to. A million-token context is useless if the agent can't discriminate between the 100 tokens that are actually relevant and the 999,900 that aren't. Memory management is partially about storage, but it's mostly about attention and relevance discrimination.
The RL approach also points toward a broader principle: memory management is a skill that should be trained, not engineered. Handcrafted rules for when to store, update, or delete information will always be outperformed by a system that learns these patterns from task outcomes. AgeMem shows this is tractable.
What's Missing
The paper is honest about limitations. The RL training is expensive — the three-stage progressive strategy requires significant compute. For teams building production agents on tight budgets, this is a real constraint.
The evaluation is also limited to relatively structured benchmarks. The messiest, most real-world aspect of long-horizon tasks — where the agent doesn't know what it'll need and the task scope shifts mid-execution — isn't fully captured.
And there's a bootstrapping problem: you need good tasks to train good memory management, but good tasks require good memory management to execute. The paper addresses this with the staged approach but doesn't fully solve the cold-start problem for new domains.
My Take
AgeMem is exactly the kind of paper I've been waiting for. Not because it solves the memory problem, but because it frames it correctly.
The field has been treating agent memory as an infrastructure problem (better databases, better retrieval algorithms, bigger context windows) when it's actually a behavioral problem. How does an agent reason about what it knows? When should it consolidate, update, or discard information? These are questions about agent behavior, and RL is the right tool for learning behavior.
The five-operation taxonomy (store, retrieve, update, summarize, remove) is a good starting point but probably incomplete. Real human memory has subtler operations — things like "flag this as uncertain," "cross-reference with that other thing," "elevate this from implicit to explicit." Future work will expand this vocabulary.
What I find most exciting is the direction this points: toward agents that have metacognition about their own knowledge state. An agent that knows what it knows, knows what it doesn't know, and knows how to maintain its knowledge over time is qualitatively different from an agent with access to a vector database. AgeMem is an early but serious step in that direction.
If you're building production agentic systems with any horizon longer than a single conversation, this paper is essential reading.
Further Reading
- arXiv: 2601.01885
- Related: Memory in the Age of AI Agents survey (2512.13564) for the broader landscape
- Related: MemR3: Memory Retrieval via Reflective Reasoning (2512.20237)


