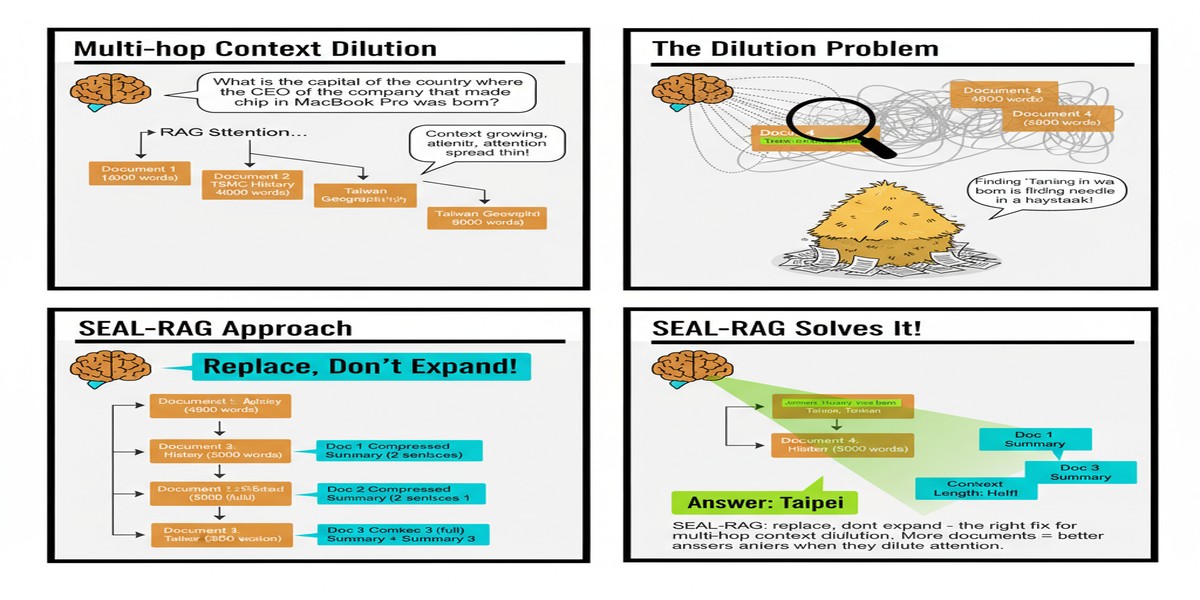
Here's a failure mode that multi-hop RAG practitioners recognize immediately but that the research community has been slow to address properly: context dilution.
The scenario: you're answering a complex question that requires 3-4 retrieval steps. At each step, you retrieve the top-k most relevant passages and add them to your context window. By step 3, you have 15-20 passages in context. Most of them are from earlier retrieval steps that were topically related to some aspect of the question but don't actually help answer the current sub-question. The relevant evidence for step 3 is in there somewhere, but it's buried in noise.
The LLM's attention is distributed across all 15-20 passages. Its accuracy on step 3 degrades. Errors propagate to step 4. The final answer is wrong.
The intuitive fix is to retrieve more carefully. But careful retrieval requires knowing what you need, which is exactly what you don't know in early retrieval steps. The less obvious fix — the one that Moshe Lahmy and Roi Yozevitch propose in their December 2025 paper — is to replace unhelpful passages instead of accumulating them.
The Context Dilution Problem, Formally

The paper formalizes context dilution as a constrained optimization problem: given a fixed evidence budget (maximum context length), and a sequence of retrieval steps, what's the optimal policy for assembling evidence at each step?
The naive policy: add retrieved passages at each step, up to the budget. Once the budget is reached, discard new retrievals.
The SEAL-RAG policy: at each step, assess whether existing passages are still relevant to the current retrieval need. If a passage is no longer helping, replace it with a more relevant new passage.
This is the "Replace, Don't Expand" framing. The insight: early retrieval steps often serve as stepping stones — they provide intermediate evidence needed to formulate later retrieval queries. Once that intermediate step is complete, the passage that enabled it may no longer contribute to the final answer.
stateDiagram-v2
[*] --> Retrieve1: Initial Retrieval\nQ → Top-5 passages
Retrieve1 --> Assess1: Assess Relevance\nWhich passages are still useful?
Assess1 --> KeepAll1: All relevant\nNo replacement
Assess1 --> Replace1: Some irrelevant\nReplace with new retrieval
KeepAll1 --> Retrieve2: Step 2 Retrieval\n[Q + existing context]
Replace1 --> Retrieve2: Step 2 Retrieval\n[Q + pruned context]
Retrieve2 --> Assess2: Assess + Replace
Assess2 --> Retrieve3: Step 3 Retrieval
Retrieve3 --> Generate: Generate Answer\nClean, focused context
The SEAL-RAG Pipeline
SEAL-RAG operates in cycles:
Search: Retrieve top-k passages for the current sub-query. Use both the original question and the entities identified so far to compose the retrieval query.
Extract: From the retrieved passages, extract specific entities that bear on the question. This is the "stepping stone" — identifying new entities that the retrieval surfaced.
Assess: For each existing passage in the context window, assess whether it remains relevant to the current state of reasoning. The assessment uses the latest set of identified entities and the remaining unknown sub-questions.
Load: Remove passages that fail the relevance assessment. Add new passages from the current retrieval step. Maintain the fixed budget constraint.
The assessment step is the key mechanism. Rather than using a simple relevance score (is this passage related to the query?), SEAL-RAG uses a conditional relevance score: "given what we've already established and what we still need to find, does this passage help?"
Why This Works: The Missing Information Tracker
SEAL-RAG explicitly tracks what information is missing at each step. This isn't a side feature — it's the engine that drives the replace decision.
At any point in the multi-hop chain, the system maintains:
- Known entities: What has been retrieved and confirmed
- Unknown entities: What still needs to be found to answer the question
- Evidence for each entity: Which passages support each known entity
When a passage's known entities are all subsumed by later, higher-quality evidence, and its unknown entities have already been resolved, it's a candidate for replacement. SEAL-RAG's "Largest Gap" strategy formalizes this: replace the passage that has the largest gap between its original contribution and its current contribution.
flowchart TD
P1[Passage 1:\nTop-grossing film 2019: Avengers Endgame\nStatus: Stepping stone, now subsumed]
P2[Passage 2:\nAvengers Endgame directors: Russo Brothers\nStatus: Still needed]
P3[Passage 3:\nAntony Russo biography\nStatus: Actively queried]
P4[Passage 4:\nMCU box office history\nStatus: IRRELEVANT - replace]
P1 -->|Contribution = near zero\nall info extracted| Replace[Replace P1 with new targeted retrieval]
P4 -->|Never needed\nHigh dilution effect| Replace2[Replace P4]
P2 & P3 --> Keep[Keep in context]
The Results
On HotpotQA:
- SEAL-RAG vs. iterative RAG baselines: +3-13% accuracy depending on the baseline and metric
- Evidence quality score: +12-18 points (a measure of how well the final evidence set supports the answer)
The accuracy gains are meaningful but not dramatic. What's more impressive is the evidence quality improvement — the assembled evidence is consistently more precise and directly relevant to the final answer. This has practical implications beyond raw accuracy: when you can inspect the evidence the model used, higher-quality evidence means better explainability.
Computational predictability is the other key result. Because SEAL-RAG maintains a fixed evidence budget throughout the retrieval process, the context length at generation time is bounded. Iterative RAG with naive accumulation leads to unbounded context growth in long chains. SEAL-RAG's context length is deterministic — useful for systems with latency and cost SLAs.
The Design Tradeoffs
I want to engage honestly with what SEAL-RAG trades away.
Replacement risk: When you replace a passage, you may be removing something you'll need later. SEAL-RAG's assessment step aims to avoid this, but it's imperfect. The paper reports cases where aggressive replacement hurts performance on questions where intermediate evidence needs to be retained throughout the chain.
Assessment overhead: The relevance assessment at each step is not free. It requires an LLM call to evaluate each existing passage against the current retrieval state. For short multi-hop chains (2-3 hops), this overhead may not be justified.
Budget sensitivity: SEAL-RAG's performance depends on choosing the right budget. Too small and you replace important passages; too large and you don't sufficiently prune. The paper provides guidance on budget selection but there's no one-size-fits-all setting.
My Take
Context dilution is a real problem and SEAL-RAG's diagnosis of it is correct. The replace-not-expand principle is the right intuition: in a fixed context budget, adding low-value content is actively harmful, not just wasteful.
The formalization as constrained set-optimization is elegant. Treating the evidence window as a scarce cognitive resource — rather than a computational cost to minimize — reframes the problem in a way that generates better solutions. This is the kind of conceptual clarity that I look for in research papers: not just "our method works" but "here's the right way to think about this problem."
For practitioners: if you're running multi-hop RAG and seeing accuracy degrade as chain length increases, the likely culprit is context dilution. SEAL-RAG's assessment-and-replace mechanism is worth implementing. The computational overhead is manageable for medium-length chains, and the accuracy and evidence quality improvements are real.
The paper leaves open the question of how to set budget adaptively — some queries genuinely need more evidence than others. That's the right next research question. But as a practical system for bounded-context multi-hop RAG, SEAL-RAG is a solid contribution.
arXiv: 2512.10787