Multi-hop question answering is where RAG systems get humbled.
Single-hop: "What is the capital of France?" Retrieve Paris, done.
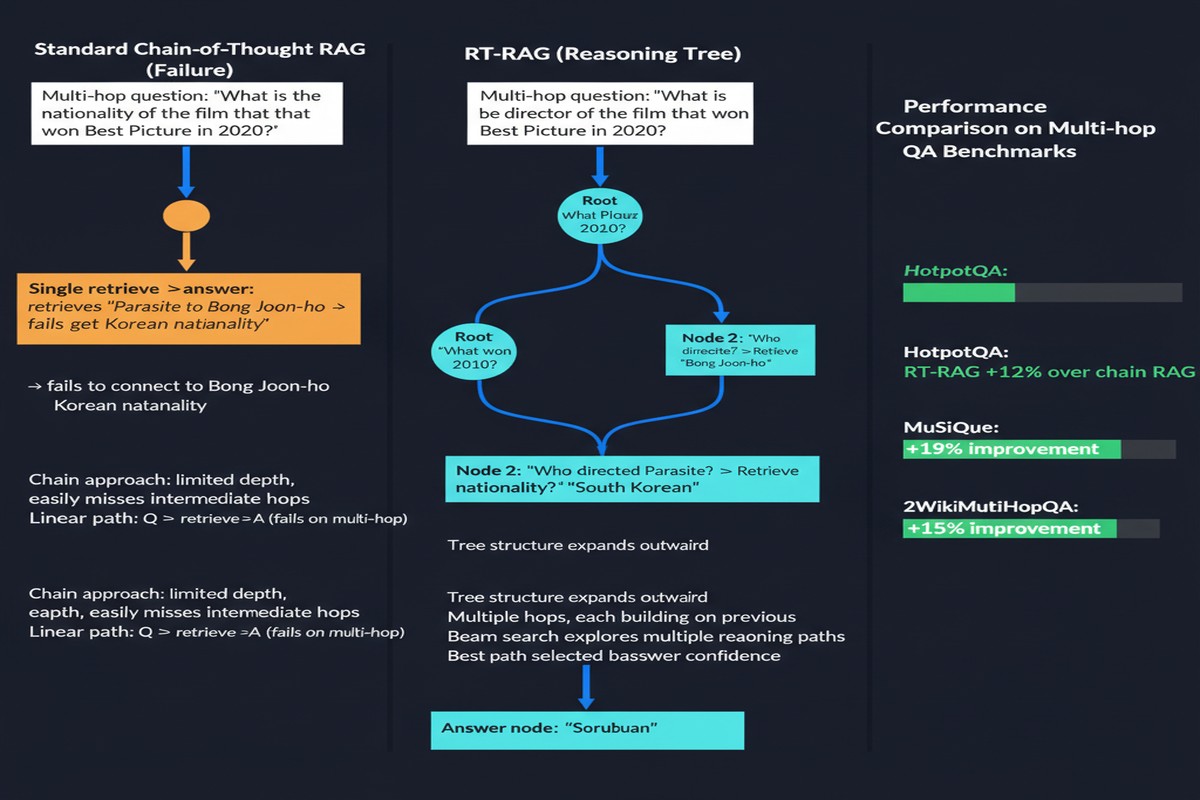
Multi-hop: "What was the birth city of the director of the highest-grossing film of 2019?" You need to know the film (Avengers: Endgame), find the director (Anthony and Joe Russo, though the question is ambiguous), look up their birth city, and answer. Each step depends on the previous one. Each retrieval failure propagates forward.
The standard approach — decompose the question into sub-questions, retrieve for each, chain the answers — has a well-documented failure mode: decomposition errors and error propagation. If you get the decomposition wrong, or if you retrieve the wrong answer for an intermediate step, subsequent steps work from a corrupted premise.
RT-RAG, presented at WWW 2026 by Yuling Shi and colleagues, addresses this directly. The key insight: trees, not chains.
The Problem With Chained Decomposition
Before describing RT-RAG, let me be precise about what's wrong with the chain approach.
Standard iterative RAG decomposition looks like this:
- Decompose Q into {Q1, Q2, Q3}
- Retrieve for Q1, get A1
- Substitute A1 into Q2, get Q2'
- Retrieve for Q2', get A2
- Continue...
This has two structural problems:
Decomposition accuracy: The LLM decomposing the question doesn't know what's retrievable. It makes decomposition decisions based on the question structure, not the corpus. If the question requires an intermediate entity that the corpus expresses differently than the question implies, the decomposition produces a sub-query that retrieval can't answer.
Error propagation: If A1 is wrong, Q2' is wrong, and A2 is likely wrong. Errors compound through the chain. In a 3-hop chain with 80% accuracy per hop, overall accuracy is 0.8³ = 0.51. For 5 hops, it's 0.33.
RT-RAG's tree structure addresses both problems:
graph TD
Q[Original Query:\nBirth city of director of top 2019 film?]
Q --> N1[Node 1: What was the top 2019 film?\nKnown: year=2019\nUnknown: film_name]
N1 -->|Retrieved: Avengers Endgame| N2[Node 2: Who directed Avengers Endgame?\nKnown: film=Avengers Endgame\nUnknown: director_name]
N2 -->|Retrieved: Russo Brothers| N3a[Node 3a: Where was Anthony Russo born?\nKnown: person=Anthony Russo\nUnknown: birth_city]
N2 --> N3b[Node 3b: Where was Joe Russo born?\nKnown: person=Joe Russo\nUnknown: birth_city]
N3a -->|Retrieved: Cleveland, OH| Agg[Aggregation Node\nCombine and resolve]
N3b -->|Retrieved: Cleveland, OH| Agg
Agg --> Ans[Answer: Cleveland, Ohio]
style N1 fill:#4a90d9,color:#fff
style N2 fill:#7b68ee,color:#fff
style N3a fill:#50c878,color:#fff
style N3b fill:#50c878,color:#fff
style Agg fill:#f4a261,color:#fff
The RT-RAG Architecture
RT-RAG builds an explicit reasoning tree where:
- Each node represents a sub-question
- Nodes track known entities (already retrieved or given in the query) and unknown entities (what needs to be retrieved)
- Branches diverge when multiple answer paths are possible
- Aggregation nodes resolve ambiguity
The known/unknown entity tracking is the crucial innovation. By explicitly tracking what the system knows and doesn't know at each step, RT-RAG can:
- Write more precise retrieval queries (using known entities as constraints)
- Detect when an intermediate result is ambiguous and branch
- Avoid substituting uncertain answers into subsequent sub-queries
Iterative Query Rewriting: At each node, RT-RAG iteratively refines the retrieval query based on what's been retrieved so far and what's still unknown. This is more than simple keyword substitution — it uses the retrieved context to write a better next query.
Evidence Quality Assessment: Before propagating an intermediate result to the next node, RT-RAG assesses whether the retrieved evidence actually answers the sub-question with sufficient confidence. Low-confidence results trigger additional retrieval rather than propagating uncertainty.
The Numbers
On three multi-hop QA benchmarks (HotpotQA, 2WikiMultiHopQA, MuSiQue), RT-RAG achieves:
- +7.0% F1 over prior state-of-the-art
- +6.0% EM (Exact Match)
These are significant gains in a research area where 1-2% improvements are typically treated as meaningful advances.
The gains are not uniform across query types. RT-RAG performs best on "bridge" questions (where the answer to one sub-question bridges to the next) and on "comparison" questions (where multiple retrieval paths need to be compared). It shows smaller gains on "intersection" questions (where the answer is the intersection of two retrieval results).
This is an honest paper. The authors include ablations showing which components contribute most, and they don't claim universal superiority.
Why This Matters Beyond Multi-Hop QA
The multi-hop QA benchmarks are useful for measurement, but the real application is enterprise knowledge retrieval where questions are naturally complex.
Consider: "What are the regulatory requirements that changed in the last 12 months that affect our product line X, and what's our current compliance status against each?" This is a multi-hop question. You need to retrieve recent regulatory changes, identify those affecting product line X, retrieve current compliance documentation, and cross-reference them. A chained approach will accumulate errors. A tree approach that explicitly tracks what's known vs. unknown at each step is fundamentally more robust.
flowchart LR
subgraph Real Enterprise Multi-hop
R1[Recent regulatory changes] --> Filter[Filter: affects product X]
R2[Product X documentation] --> Filter
Filter --> Cross[Cross-reference compliance status]
Cross --> Report[Gap Analysis Report]
end
The RT-RAG architecture maps naturally to this kind of task. The known/unknown entity tracking is essentially a dynamic state representation of what the system has established vs. what it still needs to determine. That's the right mental model for complex information retrieval tasks.
Critiques
I'll push back on a few things.
The tree construction overhead: Building a reasoning tree is more expensive than simple decomposition. The paper doesn't report inference cost comparisons in depth. For latency-sensitive applications, the improvement in answer quality may need to be weighed against increased time-to-answer.
Evaluation corpus limitation: All three benchmarks are English, factoid-style knowledge, Wikipedia-sourced. Enterprise RAG operates on proprietary documents with different structures, terminology, and query patterns. I'd want to see RT-RAG evaluated on technical domain corpora before recommending it for enterprise deployment.
Aggregation node design: The paper's aggregation nodes resolve ambiguity and combine branch results, but the design of these nodes is somewhat hand-wavy. How exactly does the system decide when to aggregate vs. return multiple answers vs. ask for clarification? The paper covers the common cases but the edge cases are underspecified.
My Take
RT-RAG is the right architectural response to a real problem. The diagnosis — that chains propagate errors while trees can handle branching and aggregation — is correct. The implementation is principled. The gains are real.
What I appreciate most is the known/unknown entity tracking. It's a clean formalization of something that practitioners know intuitively: complex queries have a state, and retrieval should be conditioned on that state. Most systems treat retrieval as stateless. RT-RAG makes the state explicit.
The WWW 2026 acceptance is well-deserved. This isn't the last word on multi-hop RAG — there's room for improvement in tree construction efficiency, aggregation design, and domain generalization — but it advances the state of the art in the right direction.
If your RAG system handles complex multi-step queries and you're seeing answer quality degrade on questions that require more than two retrieval steps, RT-RAG's architecture is the place to start your redesign.
arXiv: 2601.11255