
Paper: s1: Simple Test-Time Scaling arXiv: 2501.19393 | January 2025 Authors: Muennighoff, Yang, Shi, Li et al. (Stanford, UW, Allen Institute)
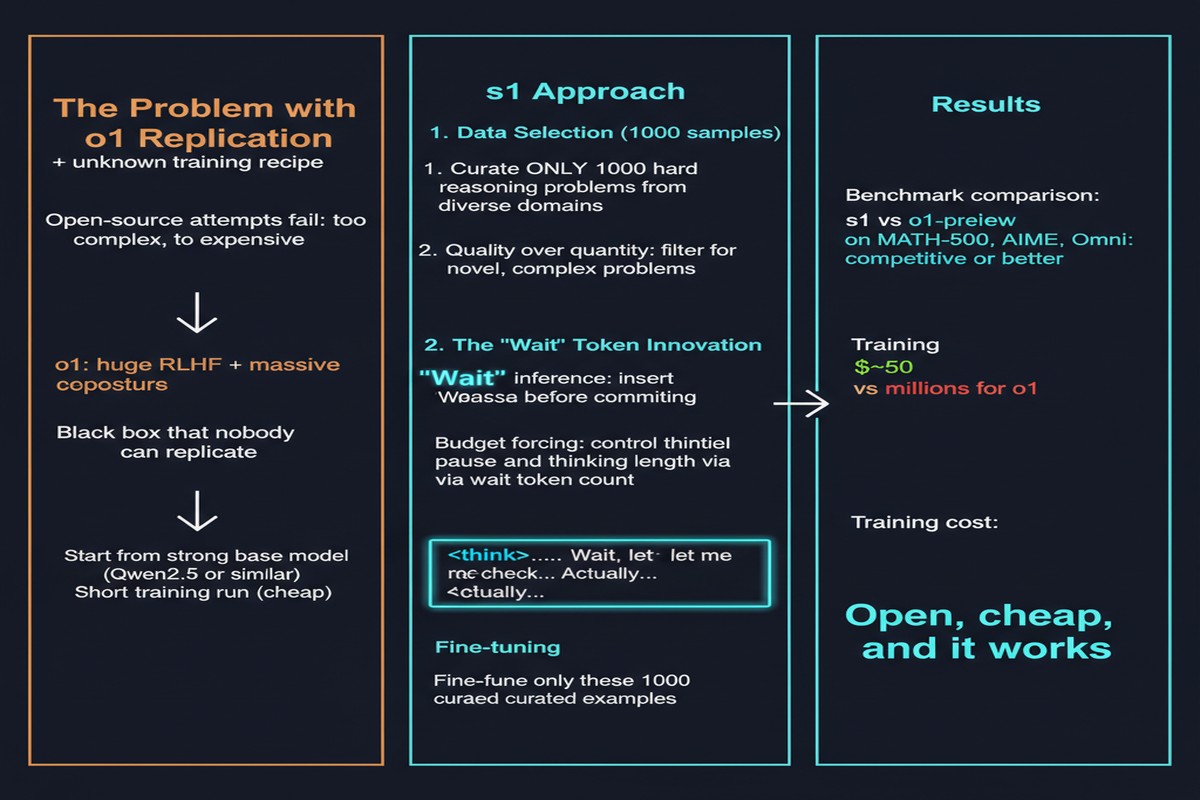
Every so often a paper appears that strips away the mythology surrounding a phenomenon and reveals it's far simpler than the industry wanted to believe. The s1 paper is one of those. It demonstrates that effective test-time compute scaling — the technique behind OpenAI's o1 — can be achieved with 1,000 training examples, a 32B base model, and a delightfully lo-fi inference trick that amounts to appending the word "Wait" to the model's output when it tries to stop thinking too early.
The researchers called this "budget forcing." I call it one of the best ideas in ML papers this year.
The Problem This Paper Addresses
OpenAI's o1 and o1-pro showed that letting a model "think longer" at inference time dramatically improves performance on hard reasoning tasks — math competitions, coding challenges, complex science problems. The mechanism is conceptually simple: instead of greedy decoding to an answer, the model generates an extended internal reasoning trace, then produces a final answer.
But OpenAI provided no details on how they built this capability. The community scrambled to replicate it. Most attempts required massive synthetic reasoning datasets, specialized reward models, or compute-intensive RL training. The implicit assumption was: you need scale to teach scale.
s1 rejects that assumption.
The Two-Part Method
Dataset: s1K
The researchers curated exactly 1,000 questions from existing open-source datasets. Their curation criteria were strict:
- Difficulty: problems must require non-trivial reasoning
- Diversity: broad coverage across math, science, coding, logic
- Quality: reasoning traces must be high-quality
Each question was paired with a reasoning trace sourced from the Gemini Thinking model. Total dataset: 1,000 samples. This is not a typo. One thousand.
They fine-tuned Qwen2.5-32B-Instruct on this dataset using standard supervised fine-tuning.
Inference: Budget Forcing
The critical innovation is budget forcing — a simple technique to control how much compute the model uses at inference time:
flowchart LR
A[Question] --> B[Model starts reasoning]
B --> C{Model tries to end?}
C -- "Yes, but budget not reached" --> D[Append 'Wait' token]
D --> B
C -- "Yes, and budget reached" --> E[Allow model to conclude]
C -- "No" --> B
E --> F[Final Answer]
subgraph "Budget Control"
G[Min tokens: force extended thinking]
H[Max tokens: truncate + force conclusion]
end
If the model starts generating a final answer before it has used its compute budget, the researchers suppress the end-of-thinking token and append "Wait" — literally. The model then continues reasoning. Conversely, if the model runs too long, the thinking is truncated and it's forced to conclude.
This bidirectional control creates a test-time compute dial. More "Wait" injections = more compute = better performance on hard problems.
The Results Are Stunning
s1-32B (Qwen2.5-32B fine-tuned on s1K with budget forcing) outperforms OpenAI o1-preview on AIME24 by up to 27%. It achieves 56.7% on AIME24 vs o1-preview's 44.6%.
On competition math (MATH benchmark), s1-32B reaches 93.0%, competitive with o1-mini.
The test-time scaling behavior is smooth: as you allow more thinking tokens, performance scales predictably. The model genuinely gets smarter the longer you let it think — but only because it was trained to use extended thinking productively.
Why This Matters
1. Data efficiency is the real story. 1,000 examples is extraordinary. The ML community has developed a cultural assumption that more data is always better, but s1 demonstrates that for fine-tuning specific capabilities, quality and selection criteria massively outweigh quantity.
2. Budget forcing generalizes. The inference-time intervention is model-agnostic. Any model trained to produce thinking traces can be equipped with budget forcing to adjust compute at inference time. This is immediately deployable by any team running open-weight reasoning models.
3. The OpenAI moat is thinner than thought. o1-preview was positioned as a major technical achievement requiring enormous compute and proprietary methodology. s1 delivers comparable performance on competition math with 1,000 examples and open-source components. That should recalibrate expectations significantly.
4. Inference compute is now a tunable parameter. For agentic systems, this is particularly important. Easy tasks get fast, cheap answers. Hard tasks get extended thinking. You don't need separate models for different complexity levels — budget forcing handles it.
My Take
I have a few strong opinions about this paper.
First: the "Wait" token idea is brilliant in its simplicity. The instinct in ML is always to add complexity — more training signals, more reward models, more architectural innovation. Budget forcing does the opposite. It exploits the fact that fine-tuned reasoning models already know how to think; they just need permission to keep going. This is a pattern I expect to see replicated across many domains.
Second: the curation methodology matters more than people realize. The 1,000 examples in s1K are not random. The researchers ran extensive ablations showing that quality and diversity are more predictive of fine-tuned performance than raw quantity. The implication is that dataset curation is a core competency, not a preprocessing step. Teams that invest in systematic data selection will consistently outperform teams that throw more data at the same quality.
Third: I am moderately skeptical of the benchmark comparisons to o1-preview. AIME24 is a clean, verifiable domain where test-time scaling works especially well. s1 may not close the gap on less structured reasoning tasks. OpenAI's advantage likely lies in training across more varied domains, not in any single architectural secret.
But that caveat doesn't diminish what s1 achieved. It proved the principle, showed the recipe, and open-sourced it. Any organization can now deploy effective test-time scaling with modest resources. The question is whether they will build the data curation infrastructure to do it well.
If I were building a reasoning-capable product today, s1 would be my starting point: Qwen2.5-32B, a focused 1K-5K sample dataset curated around my target domain, budget forcing at inference. That's a production-ready reasoning system available to anyone with a single A100 node.

arXiv:2501.19393 — read the full paper at arxiv.org/abs/2501.19393


