
ThinkPRM: Teaching Reward Models to Think Before They Judge
The post-training revolution in LLMs has a verification problem. As we push models to reason over longer chains of thought — math problems, code debugging, logical deduction — we need reward signals that evaluate not just final answers but intermediate reasoning steps. Process Reward Models (PRMs) are supposed to provide this, but they're expensive to train: you need human annotators (or powerful LLMs) to label the quality of every intermediate step in a reasoning trace.
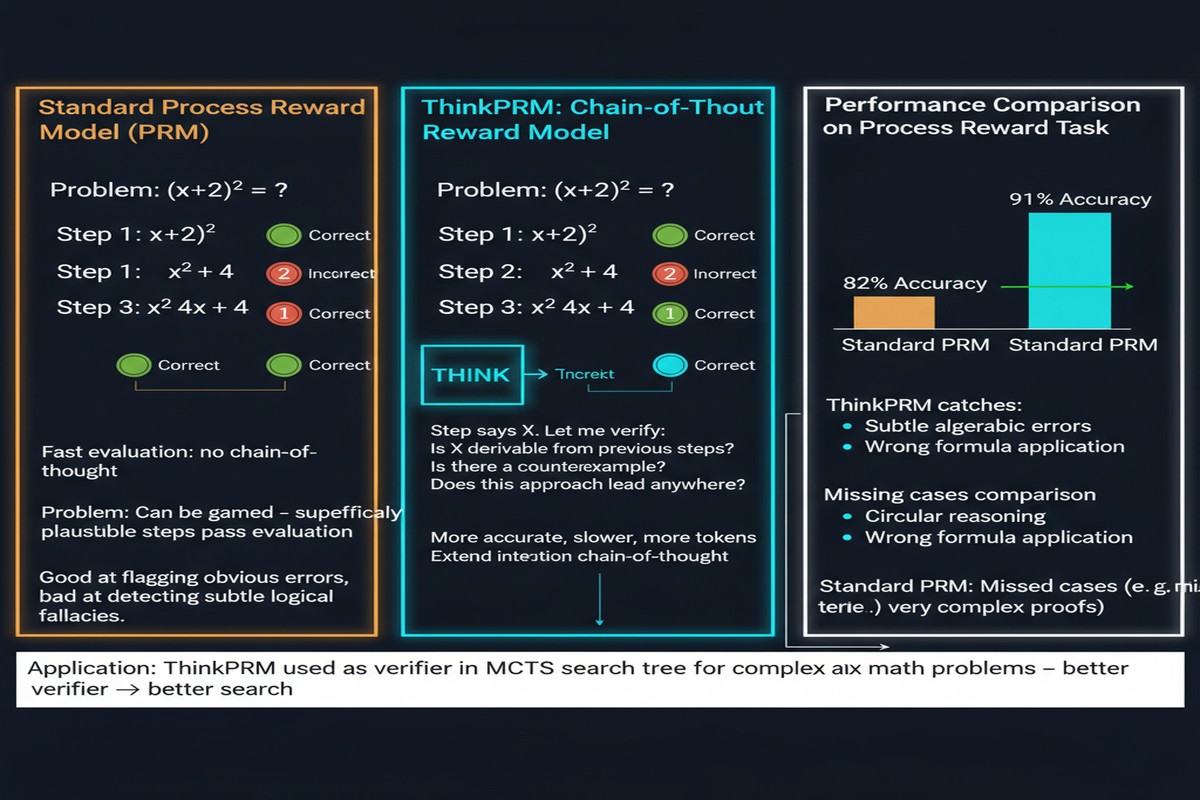
ThinkPRM ("Process Reward Models That Think", arXiv: 2504.16828, Apr 2025) challenges this annotation bottleneck with an elegant solution: train the reward model to generate verification chain-of-thought before scoring each step. The result is a data-efficient PRM that matches or exceeds discriminative PRMs trained on vastly more labeled data.
Background: Why Process Supervision Matters
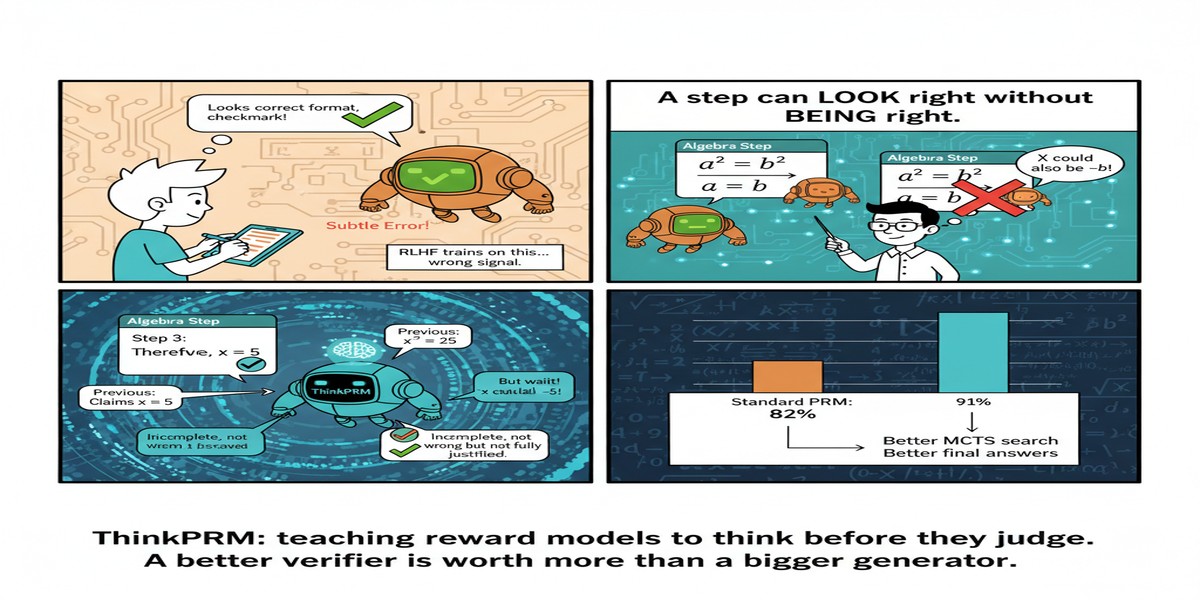
Standard Outcome Reward Models (ORMs) judge the final answer. For math problems, this is straightforward — either the answer is correct or not. But outcome supervision has a fundamental problem: it provides no signal about why the answer is correct or wrong. A reasoning chain with lucky final answer gets the same reward as a principled reasoning chain. This encourages reward hacking — finding paths to correct answers through flawed or shortcut reasoning.
Process Reward Models evaluate each reasoning step independently. A step that uses a wrong formula gets penalized even if subsequent steps happen to recover the correct answer. This provides denser, more principled supervision.
flowchart TD
subgraph ORM - Outcome Reward Model
Q1[Problem] --> R1[Step 1]
R1 --> R2[Step 2 wrong]
R2 --> R3[Step 3 lucky recovery]
R3 --> A1[Correct Answer]
A1 --> ORM_score[Score: +1.0 MISLEADING]
end
subgraph PRM - Process Reward Model
Q2[Problem] --> S1[Step 1: +0.9]
S1 --> S2[Step 2: -0.8 CAUGHT ERROR]
S2 --> S3[Step 3: +0.3]
S3 --> A2[Correct Answer]
A2 --> PRM_agg[Aggregate: 0.46 ACCURATE]
end
style ORM_score fill:#ef4444,color:#fff
style PRM_agg fill:#059669,color:#fff
style S2 fill:#dc2626,color:#fff
The problem with PRMs in practice is the annotation cost. Labeling step-level quality for thousands of reasoning traces requires either expensive human annotation or LLM-as-judge approaches that have their own reliability issues.
ThinkPRM: The Verification Chain-of-Thought Approach
ThinkPRM reframes the PRM as a generative model, not a discriminative classifier. Instead of taking a reasoning step and outputting a scalar quality score, ThinkPRM takes a reasoning step and first generates a verification chain-of-thought — a natural language analysis of whether the step is correct — then uses this CoT to produce a final score.
sequenceDiagram
participant S as Reasoning Step
participant T as ThinkPRM
participant C as Verification CoT
participant Sc as Final Score
S->>T: "Let x = 3, then 2x + 1 = 7..."
T->>C: Generate: "The substitution is correct.\n2(3)+1 = 7. But we haven't verified\nif x=3 satisfies the original constraint..."
C->>Sc: 0.65 (step is algebraically correct\nbut logically incomplete)
The key insight: generating verification reasoning forces the model to explicitly articulate why a step is good or bad, rather than learning a mapping from step → score that may be superficial or over-fit to surface patterns.
Data Efficiency: The Critical Advantage
Standard discriminative PRMs require step-level binary labels (correct/incorrect) for each intermediate step in a reasoning trace. ThinkPRM is trained primarily on:
- Outcome labels (which final solutions are correct) — abundant and cheap
- A small number of process labels — orders of magnitude fewer than discriminative PRMs
The verification CoT is generated by the model itself during training through a self-supervised process. The model learns to produce coherent verification reasoning by being trained to produce accurate final judgments, with the CoT acting as an internal scratchpad that grounds the score.
The paper demonstrates that ThinkPRM matches state-of-the-art discriminative PRMs while requiring roughly 100x fewer explicit process labels in training. This collapses the annotation bottleneck.
Performance on Test-Time Compute Scaling
One of the primary uses of PRMs is guiding test-time compute — using beam search or best-of-N sampling, where the PRM scores candidate solutions and helps select the best one.
ThinkPRM excels here. When used to guide best-of-N sampling on MATH and other reasoning benchmarks:
- ThinkPRM as verifier consistently outperforms ORM-guided search
- ThinkPRM matches discriminative PRMs trained on 100x more data
- The improvement compounds at higher N (more candidates) — ThinkPRM's verification quality scales better with more compute
This last finding is significant for the test-time scaling literature. As systems shift toward inference-time compute (think o1, DeepSeek-R1, QwQ), the quality of the verifier becomes the bottleneck. ThinkPRM's ability to produce coherent verification reasoning may be exactly what's needed to unlock the next level of reasoning quality.
Connection to the Broader PRM Landscape
ThinkPRM emerges alongside a rich literature on PRMs (see the comprehensive survey, arXiv: 2510.08049, Oct 2025):
- AgentPRM extends process supervision to agent trajectories with tool use and multi-step actions
- VRPRM applies visual reasoning for multimodal process verification
- Math-Shepherd pioneered Monte Carlo estimation for step-level labels — an approach ThinkPRM shows is inferior to LLM-as-judge and human annotation
The trend is clear: PRMs are moving from discriminative classifiers to generative verifiers. ThinkPRM is the leading paper in this direction.
Why This Matters
The bottleneck in post-training LLMs is increasingly data quality, not quantity. Getting step-level process supervision at scale has been the critical limitation for pushing reasoning quality. If ThinkPRM's data efficiency claims hold across domains beyond mathematics, this is a genuinely enabling technology.
Consider the downstream applications:
Code debugging: Process supervision at each reasoning step could supervise a coding agent's debugging process, penalizing incorrect hypotheses before they lead to wrong fixes.
Scientific reasoning: Step-level verification in chain-of-thought for scientific problem-solving could catch reasoning errors before they propagate to incorrect conclusions.
Agent decision-making: PRMs for agent trajectories (AgentPRM) could provide step-level feedback on tool use and planning decisions — richer signal than outcome-only reward.
My Take
ThinkPRM is a clever and important paper. The idea of making a reward model generate reasoning before judging is exactly the kind of architecture alignment that the field should be pursuing — making models more interpretable and more accurate simultaneously.
I'm particularly excited about the data efficiency result. The bottleneck to deploying PRMs in real applications has always been annotation cost. If ThinkPRM's approach genuinely reduces this by 100x, it changes the economics of process supervision.
My skepticism: the results are primarily on mathematical reasoning benchmarks where step-level correctness is well-defined. Verification CoT for ambiguous or open-ended reasoning tasks — where there isn't a clear right answer to each step — is harder. I'd like to see ThinkPRM evaluated on creative writing, legal reasoning, or qualitative analysis where step quality is more subjective.
Still, this is the right direction. Reward models that reason about their judgments are more trustworthy than reward models that classify in the dark. The test-time scaling era needs trustworthy verifiers. ThinkPRM is a step toward that.
Paper: "Process Reward Models That Think", arXiv: 2504.16828, Apr 2025.


