
Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning arXiv: 2501.12948 | January 2025 Authors: DeepSeek-AI (Guo et al.)
When DeepSeek-R1 dropped in January 2025, it landed like a meteor. Not because the results were unprecedented — OpenAI had already shown o1 could reason — but because DeepSeek showed how. The answer was elegant, uncomfortable for Silicon Valley, and remarkably cheap: pure reinforcement learning, no human-labeled reasoning traces needed.
This paper is required reading. If you are building AI systems in 2026 and haven't read DeepSeek-R1, you are missing foundational context for everything that followed.
What the Paper Does
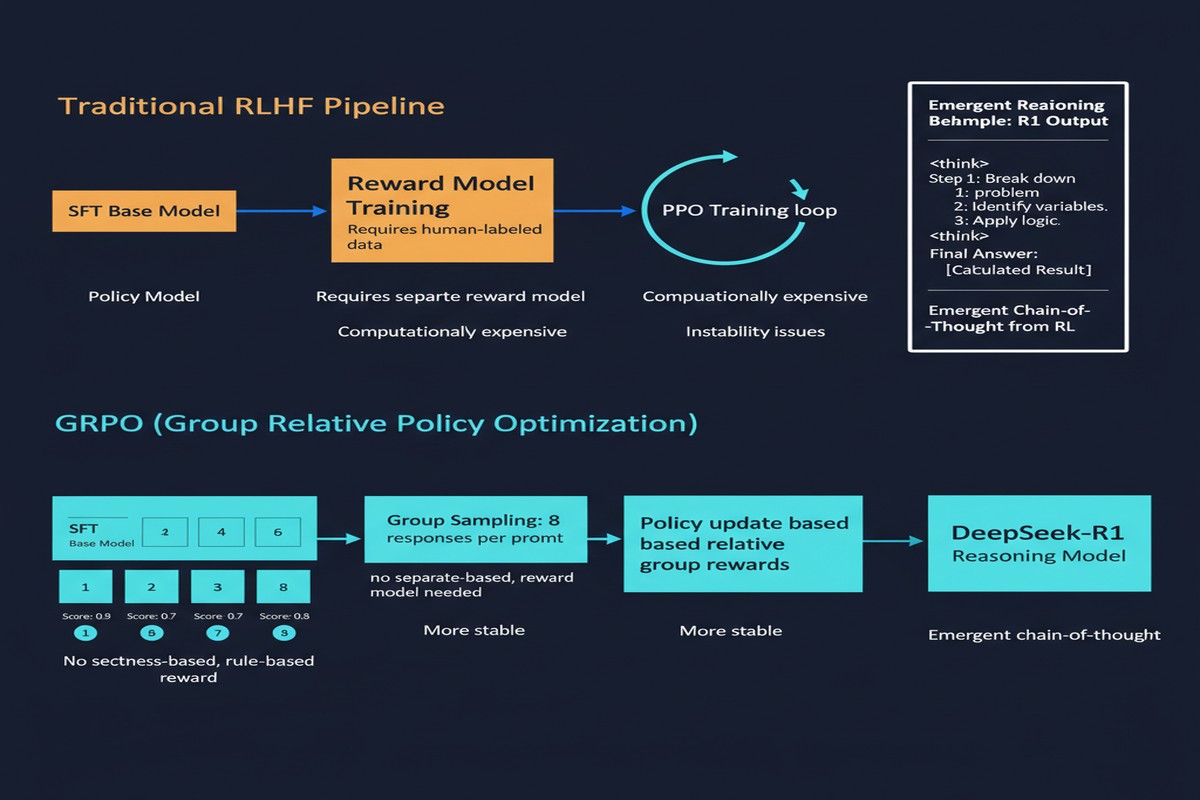
The core claim of DeepSeek-R1 is that you can incentivize reasoning behavior in large language models purely through reinforcement learning — specifically, through a new algorithm called Group Relative Policy Optimization (GRPO) — without relying on any supervised reasoning trajectories.
Prior to this work, the dominant paradigm for teaching models to reason was SFT (Supervised Fine-Tuning) on reasoning traces: you collect examples where a human or a stronger model explains its thinking step-by-step, then train on those. The assumption was that RL alone was too sparse and too unstable to produce coherent, extended reasoning chains.
DeepSeek-R1-Zero disproves this assumption directly. Starting from a base language model and training only with RL on verifiable tasks (math problems, coding challenges, STEM questions), the model develops:
- Extended chain-of-thought reasoning
- Self-reflection and error correction mid-reasoning
- Verification loops — the model re-checks its own conclusions
- Dynamic strategy shifts when one approach fails
All of this emerged from RL without any explicit supervision on how to reason.
How GRPO Works
Standard PPO (Proximal Policy Optimization), the workhorse of RLHF, requires a separate value network to estimate advantages. GRPO eliminates this. Instead, it groups multiple rollouts of the same prompt together and uses the relative performance of those rollouts to compute advantages.
flowchart TD
A[Prompt: Math Problem] --> B[Sample G rollouts from current policy]
B --> C[Compute reward for each rollout]
C --> D[Normalize rewards within group to get advantages]
D --> E[Update policy to favor higher-advantage rollouts]
E --> F[Clip updates using KL divergence penalty]
F --> G[Next training step]
subgraph Reward Model
H[Rule-based: Correct final answer = 1.0]
I[Format reward: CoT format bonus]
end
C --> H
C --> I
The reward signal is entirely rule-based. For math: if the final boxed answer matches the ground truth, reward = 1. Otherwise 0. No learned reward model, no human preference data. This dramatically reduces training cost and removes the reward hacking surface that plagues learned reward models.
The Results
DeepSeek-R1 matches OpenAI o1-1217 on AIME 2024 (79.8% vs 79.2%), achieves 97.3% on MATH-500 (vs 96.4% for o1), and is competitive across a range of STEM benchmarks. For coding, it ranks in the top 0.3% on Codeforces, comparable to o1.
More interestingly: DeepSeek-R1 also shows that you can distill a smaller model from a reasoning model without losing much capability. DeepSeek-R1-Distill-Qwen-32B, using only the reasoning traces from R1 as SFT data, outperforms o1-mini on nearly every benchmark.
This distillation result is arguably more consequential than the main result. It means that once one organization produces a reasoning model via expensive RL, the reasoning capability can be transferred efficiently to smaller models — democratizing access.
Why This Matters
The implications cascade across the entire field:
1. RL-based reasoning is now proven viable at scale. The field had debated whether RL alone could produce coherent extended reasoning. R1 settled this. Multiple teams have since replicated the approach with different base models, confirming it's not a fluke.
2. The cost asymmetry is staggering. DeepSeek reportedly trained R1 for roughly $5.5M USD in compute. OpenAI o1 was estimated at orders of magnitude more. Whether those estimates are accurate, the gap in efficiency is real and significant.
3. Verifiable domains are the proving grounds. GRPO works because rewards are verifiable — math has right answers, code either runs or it doesn't. The challenge for the next generation is extending RL training to domains where correctness is harder to verify: legal reasoning, medical diagnosis, open-ended planning.
4. Chinese AI labs have closed the gap. This is the geopolitical subtext nobody wants to say plainly. DeepSeek-R1 demonstrated that the US AI lead is narrower than many assumed, and that it was achieved with fewer resources and without the largest GPU clusters.
My Take
I'll be direct: DeepSeek-R1 is the most important LLM training paper since InstructGPT. It demonstrates that the critical ingredient for reasoning is not more data or more parameters — it is the right training signal. GRPO is elegant, cheap, and works. That combination rarely happens in ML.
What troubles me is the narrowness of the verifiable reward signal. R1 is brilliant at math and code because those have ground truth. But the world's most valuable reasoning problems — strategy, medicine, law, engineering judgment — are not cleanly verifiable. GRPO-style RL is not obviously applicable there, and I suspect we will spend the next two years figuring out how to extend these ideas to open-ended domains.
I am also watching the distillation angle carefully. If the reasoning capability in R1 can be transferred to 7B and 14B models with minimal degradation, it changes the deployment economics of reasoning models completely. You don't need a 671B MoE to get o1-level reasoning in controlled domains. A 32B distilled model may be enough — and that changes the build-vs-buy calculus for every enterprise team I know.
The paper is not without weaknesses. DeepSeek-R1-Zero, the pure RL model, occasionally produces reasoning traces with language mixing (English/Chinese interleaved), suggests the RL training is not entirely stable. The full R1 uses a cold-start SFT phase to address this, which means it's not purely RL — a detail that sometimes gets lost in the excitement.
Still: if you are building on LLMs in 2026 and you haven't internalized the GRPO training loop, you are behind. This paper rewired how I think about model training, and I believe it will remain foundational for years.

arXiv:2501.12948 — read the full paper at arxiv.org/abs/2501.12948


