Most knowledge graph RAG papers start from the engineering side: how do we extract entities, how do we build edges, how do we traverse the graph efficiently? Zirui Liao's EcphoryRAG, published October 2025, starts from a different place — cognitive neuroscience.
The paper's central premise is that current KG-RAG systems fail in the same way that brute-force memory systems fail: they try to store and retrieve everything explicitly, which makes them expensive, brittle, and surprisingly bad at the kind of flexible, context-sensitive reasoning that complex queries require.
Human associative memory doesn't work this way. We don't explicitly store every relationship between every fact we know. Instead, we store key entities and cues, and we dynamically infer relationships when we need them. The word "ecphory" refers specifically to this process — the activation of a stored memory trace through associative cues. EcphoryRAG applies this principle directly.
The Architecture
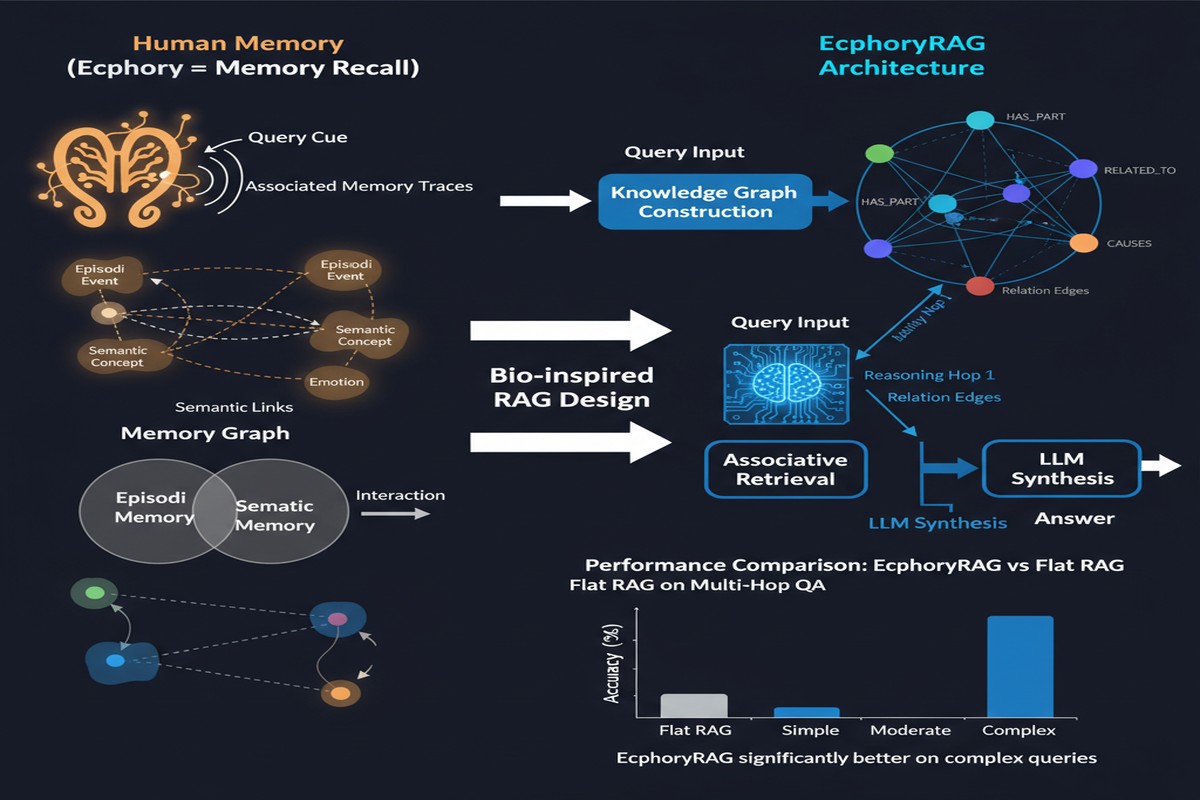
The key design decision is what the system doesn't store.
Traditional KG-RAG systems build dense knowledge graphs: extract every entity, extract every relation, store every (entity, relation, entity) triple. This gives you a complete representation but at enormous storage and retrieval cost.
EcphoryRAG builds a sparse, entity-centric representation:
- Index only entities and their essential metadata (type, description, key attributes)
- Do not store explicit relations — infer them dynamically at query time
- Track entity co-occurrence within document chunks as a proxy for relationship signals
This is the cognitive science insight: instead of pre-computing all relationships, store enough to reconstruct them when needed.
flowchart TD
subgraph EcphoryRAG Indexing
Doc[Documents] --> EE[Entity Extraction\nNames + Metadata]
Doc --> CO[Co-occurrence Tracking\nWhich entities share chunks]
EE --> ES[Entity Store\nSparse representation]
CO --> ES
end
subgraph EcphoryRAG Retrieval
Q[Query] --> QE[Query Entity Extraction]
QE --> EA[Entity Activation\nFind matching entities in store]
EA --> MH[Multi-hop Traversal\nDynamic relationship inference]
MH --> CI[Implicit Relationship Completion\nLLM infers missing connections]
CI --> CTX[Context Assembly]
CTX --> ANS[Answer Generation]
end
Query Time: When a query arrives, EcphoryRAG extracts the query entities and activates the matching entries in the entity store. Then it performs multi-hop traversal — not over an explicit relation graph, but over the co-occurrence structure — following which entities tend to appear alongside the activated ones. For implicit relationships that aren't captured in co-occurrence, an LLM inference step fills the gap.
This is the "ecphory" in action: a memory cue (the query) activates an entity, which activates associated entities, which collectively assemble the context needed to answer.
The Token Efficiency Numbers
The paper's headline result is that EcphoryRAG uses up to 94% fewer tokens compared to other structured RAG approaches (the comparison is against GraphRAG-style systems that store full relation triples).
Let me put this in concrete terms. A dense KG-RAG system might represent a 1,000-document corpus with a knowledge graph containing 500,000 entity-relation-entity triples. Retrieving context for a query might pull 200 of those triples into the context window. EcphoryRAG represents the same corpus with a much smaller entity store and assembles context dynamically — the in-context representation for the same query might be 12 entities with metadata rather than 200 triples.
This has two practical implications:
- Indexing cost: The entity store is dramatically cheaper to build than a full KG
- Retrieval cost: The context assembled per query is much shorter, reducing both latency and LLM cost
Performance: Exact Match Improvement
On three benchmark datasets (the paper uses KGQA and multi-hop QA benchmarks), EcphoryRAG improves exact match from approximately 0.392 to 0.474 compared to the best baseline KG-RAG approach.
That's a meaningful improvement (~21% relative gain) achieved with a fundamentally more efficient architecture. The paper attributes this to two factors:
Reduced noise: By not storing explicit relations, the system avoids the entity extraction and relation extraction errors that plague dense KG systems. Relation extraction is notoriously unreliable for complex, nuanced relationships; EcphoryRAG sidesteps this by not trying to extract them in the first place.
Better multi-hop traversal: Dynamic relationship inference allows the system to follow chains of reasoning that weren't anticipated at indexing time. A dense KG can only traverse edges that were explicitly extracted. EcphoryRAG can infer new connections at query time.
graph TD
subgraph Dense KG-RAG Failure Mode
A1[Entity: Bengaluru] -->|extracted edge| B1[Entity: India]
A1 -->|extracted edge| C1[Entity: Tech Hub]
D1[Entity: Infosys] -->|extracted edge| B1
D1 -.->|MISSING: not extracted| A1
end
subgraph EcphoryRAG Success
A2[Entity: Bengaluru] --- CO1[Co-occurrence\nwith Infosys in 47 chunks]
D2[Entity: Infosys] --- CO1
CO1 -->|Dynamic inference| LINK[Inferred: Infosys headquarters in Bengaluru]
end
The Limitations Worth Acknowledging
EcphoryRAG's efficiency comes from a design choice that also introduces a fundamental limitation: implicit relationships require inference at query time.
For relationships that are frequently co-occurring in the corpus, this works well. For rare or subtle relationships, the dynamic inference may fail or be unreliable. A dense KG that explicitly stores (Elon Musk, founded, SpaceX) will always return that fact. EcphoryRAG will return it if "Elon Musk" and "SpaceX" frequently co-occur in the same document chunks — which they do — but may miss more obscure or nuanced relationships.
The paper also doesn't fully address the single-author limitation: this appears to be primarily a single-researcher work, with Zirui Liao as the sole author. While that's not inherently a problem, it means less diverse experimental validation and a higher risk of overlooked failure modes.
I'd also want to see evaluation on truly adversarial multi-hop queries — chains of 4-5 hops where the connection between the query and the answer is genuinely indirect. The benchmarks used in the paper are mostly 2-hop.
Why the Cognitive Science Framing Matters
I want to defend the paper's cognitive science framing, which some readers might dismiss as marketing. It's not.
The framing matters because it generates the right design constraints. If you start from "how do humans store and retrieve knowledge," you arrive at different design decisions than if you start from "how do we build an efficient graph database." Specifically:
- Store sparse cues, not complete facts
- Infer dynamically at retrieval time, not index time
- Use co-occurrence as a proxy for relationship salience
- Trust inference to fill gaps rather than trying to be exhaustive
These are principled decisions with theoretical grounding. That's different from the usual system paper approach of "we tried various things and this combination worked best."
My Take
EcphoryRAG is a genuinely creative paper that benefits from starting with the right question: what's the minimum representation that preserves sufficient information for retrieval? The answer turns out to be entities + co-occurrence + dynamic inference, and the efficiency gains from that answer are substantial.
The 94% token reduction is impressive, but I'm more interested in the design philosophy. The RAG field has been building incrementally more complex retrieval systems — adding more graph structure, more edge types, more traversal algorithms. EcphoryRAG pushes back: do less at index time, do more at inference time. That's a valid and underexplored point in the design space.
For teams using graph RAG today who are hitting scalability walls, EcphoryRAG is worth serious consideration. The efficiency gains are real and the accuracy improvements are genuine. The tradeoff is potential brittleness on rare or subtle relationships, which may or may not matter depending on your corpus.
arXiv: 2510.08958