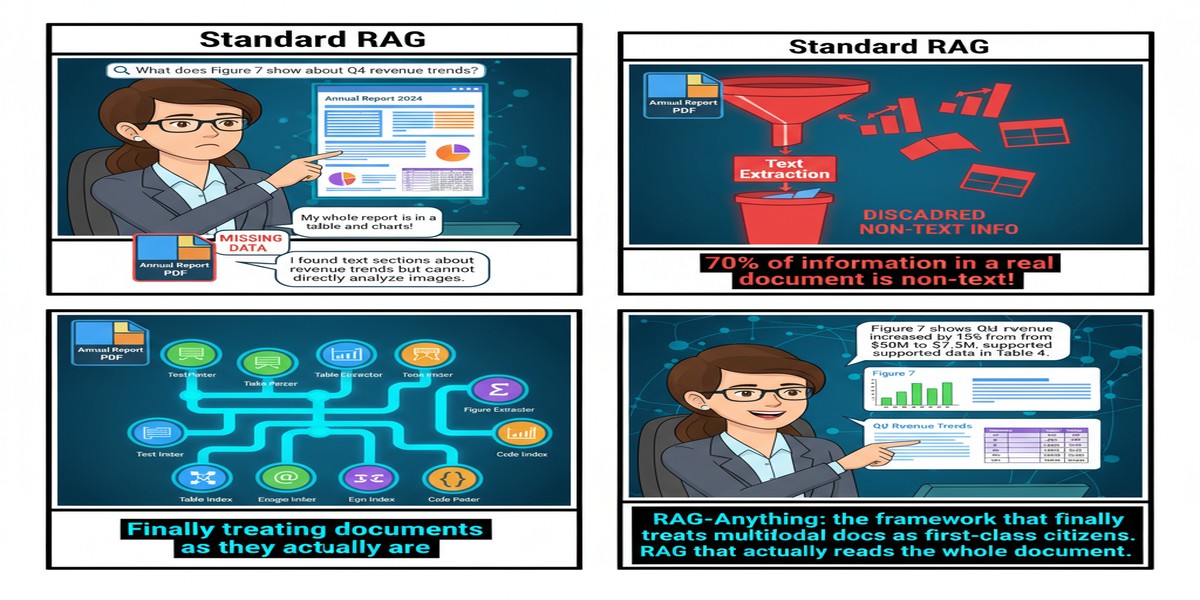
Ask anyone who's built RAG over real documents — annual reports, technical manuals, scientific papers, regulatory filings — and they'll tell you the same thing: the text is the easy part.
The hard part is the table on page 47 that the narrative on page 12 is referring to. The hard part is the architecture diagram in section 3 that the paragraph below it is explaining. The hard part is the equation that the methodology section defines but whose implications are only spelled out in the results. Text-only RAG doesn't just struggle with this — it completely ignores it.
RAG-Anything, published October 14, 2025 by Zirui Guo and colleagues at CUHK, takes this problem seriously. The result is an open-source framework that treats multimodal content as first-class citizens in retrieval, not afterthoughts.
The Problem With Text-Only RAG
Let me be precise about what text-only RAG actually loses.
When you chunk a PDF into text segments, you lose:
- Table structure: The semantic content of a table is in its row/column relationships, not just its cell text
- Visual context: Figures, charts, and diagrams contain information that their captions only partially describe
- Mathematical notation: Equations rendered as LaTeX or images convey structure that raw text extraction mangles
- Cross-modal references: A statement like "as shown in Figure 3" becomes meaningless if Figure 3 was stripped out
Standard RAG pipelines handle this by pretending it doesn't happen. RAG-Anything handles it by building a unified knowledge representation that preserves cross-modal relationships.
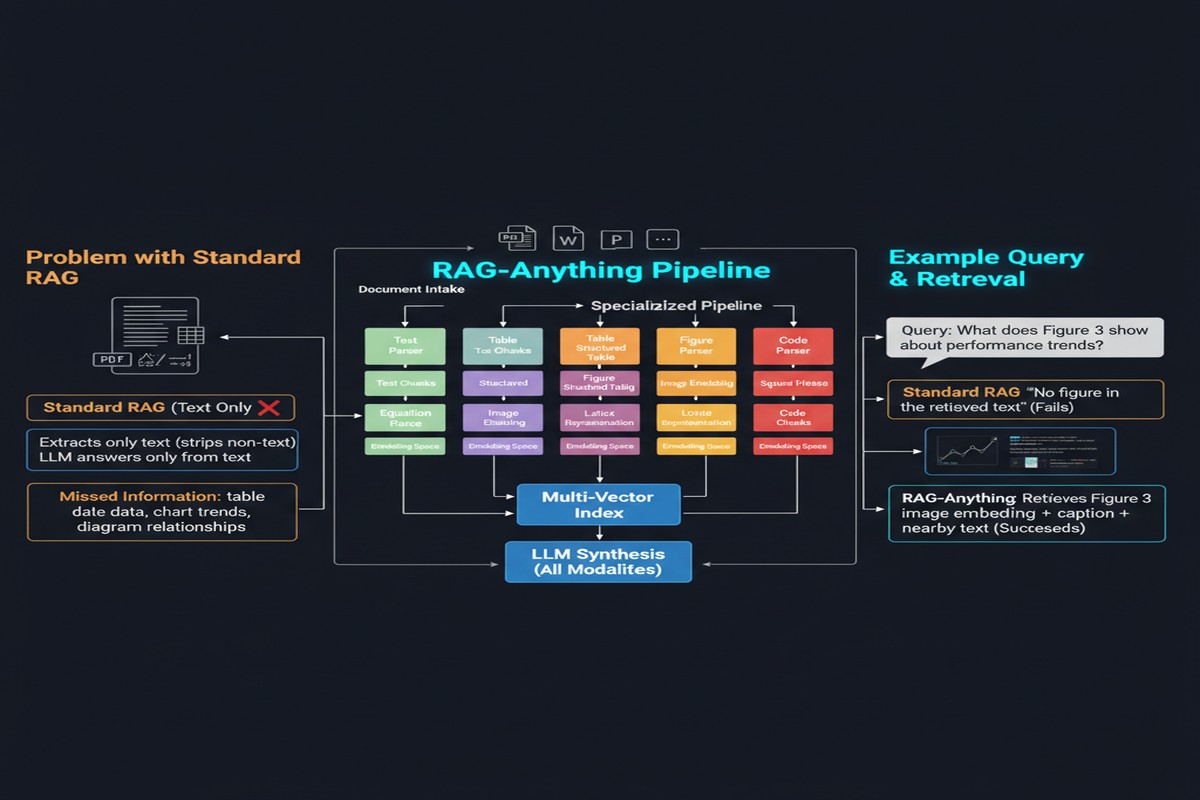
The Architecture
RAG-Anything's architecture has three distinctive components:
flowchart TD
Doc[Input Document] --> Parse[Multimodal Parser]
Parse --> Text[Text Chunks]
Parse --> Tables[Tables]
Parse --> Images[Images/Figures]
Parse --> Math[Equations]
Text --> EG[Entity Graph\nSemantic Nodes]
Tables --> EG
Images --> EG
Math --> EG
EG --> DG1[Intra-Modal Graph\nSame-modality links]
EG --> DG2[Cross-Modal Graph\nCross-modality links]
DG1 --> Hybrid[Hybrid Retrieval Engine]
DG2 --> Hybrid
subgraph Retrieval
Hybrid --> Dense[Dense Semantic Search]
Hybrid --> Struct[Graph Traversal]
end
Dense --> Answer[Answer Generation]
Struct --> Answer
Dual Knowledge Graph: This is the centerpiece. RAG-Anything builds two complementary graphs:
- An intra-modal graph linking related content within each modality (text chunks that discuss the same concept, tables that contain related metrics)
- A cross-modal graph linking content across modalities (a figure to the paragraph describing it, an equation to the prose that interprets it)
The cross-modal graph is what makes this genuinely different. When the retriever finds a relevant text chunk, it can traverse cross-modal edges to retrieve the figure that chunk references. This is the kind of retrieval that mirrors how a human expert reads a technical document.
Unified Embedding Space: All content types — text, table summaries, image captions, equation descriptions — are projected into a shared embedding space. This enables semantic search across modalities without modality-specific pipelines.
Hybrid Retrieval: The system combines dense semantic retrieval (for finding semantically similar content) with graph traversal (for following explicit cross-modal connections). Neither alone is sufficient.
What Works and What Doesn't
The paper's benchmarks on multimodal QA datasets (SlideVQA, MP-DocVQA) show meaningful improvements over text-only RAG and naive multimodal baselines. The gains are especially large on questions that require integrating information across modalities — "what does the chart in section 4 show about the trend that the text on page 8 predicts?"
The open-source release is genuinely useful. I've looked at the code. The parser handles the messy reality of PDF extraction with reasonable robustness, and the graph construction is well-engineered.
Where it struggles: the quality of cross-modal link detection depends heavily on reference extraction, which is brittle. "As shown in Figure 3" is easy to parse. "The above diagram" requires understanding relative positioning in the document. Implicit cross-modal relationships — where a table supports a claim in the text but isn't explicitly cited — are largely missed.
The paper also doesn't address the challenge of quality degradation in OCR-heavy documents. If your PDF is a scanned document with imperfect text extraction, the knowledge graph built on top of it will be noisy.
Why This Matters
Here's the thing: the real world does not store its knowledge in text-only documents.
Financial reports contain tables with key metrics alongside narrative commentary. Medical records combine lab results with physician notes. Engineering specifications embed CAD drawings alongside tolerance tables. Legal contracts reference schedules, exhibits, and amendments that are themselves heterogeneous documents.
Any enterprise RAG deployment that ignores non-text content is building on a false premise. The premise that you can extract meaningful answers from complex documents by only reading the text is wrong, and we've known it's wrong, but most teams default to it because multimodal RAG is hard.
RAG-Anything doesn't make multimodal RAG easy. But it makes it tractable. It provides a principled architecture and a working implementation that teams can adapt.
graph LR
subgraph Real Enterprise Documents
PDF1[Technical Manual\n12% text, 88% tables/figures]
PDF2[Financial Report\n60% tables, 40% commentary]
PDF3[Research Paper\n40% equations/figures, 60% text]
end
subgraph Text-Only RAG
PDF1 --> Lost1[❌ Most content lost]
PDF2 --> Lost2[❌ Tables flattened]
PDF3 --> Lost3[❌ Equations ignored]
end
subgraph RAG-Anything
PDF1 --> KG1[✓ Unified Knowledge Graph]
PDF2 --> KG2[✓ Unified Knowledge Graph]
PDF3 --> KG3[✓ Unified Knowledge Graph]
end
My Take
RAG-Anything is a well-scoped system paper that solves a real problem. I respect the authors for not overselling: they're not claiming to solve document understanding in general, they're claiming to build a better retrieval system for heterogeneous documents. That's a tractable problem and they've made genuine progress.
My criticism is about what comes after retrieval. The paper focuses heavily on the retrieval side — getting the right multimodal content into context — but says less about generation. Even if you perfectly retrieve a table alongside the text that references it, generating a correct answer from that combined context is nontrivial. Table-augmented generation is its own research area, and the paper doesn't engage with it deeply.
I also want to see this evaluated on truly messy real-world documents — the kind you encounter in enterprise deployments. The benchmarks use curated multimodal datasets. Real PDFs have inconsistent formatting, missing alt-text, and extraction artifacts that would stress-test the pipeline significantly.
But these are extensions, not criticisms of what the paper actually delivers. If you're building RAG over document-heavy enterprise data and you're currently throwing away everything that isn't text, RAG-Anything is the place to start.
arXiv: 2510.12323