
Let me be direct: most "agentic RAG" papers are dressed-up pipelines. They still have fixed retrieval stages, pre-baked query reformulation, and hand-coded orchestration logic. The only thing "agentic" about them is that someone added the word to the abstract.
A-RAG, published February 3, 2026 by Mingxuan Du and colleagues at USTC, is different. It actually gives the model control over retrieval — not just what to retrieve, but how to retrieve it. And the empirical results back it up.
What A-RAG Does
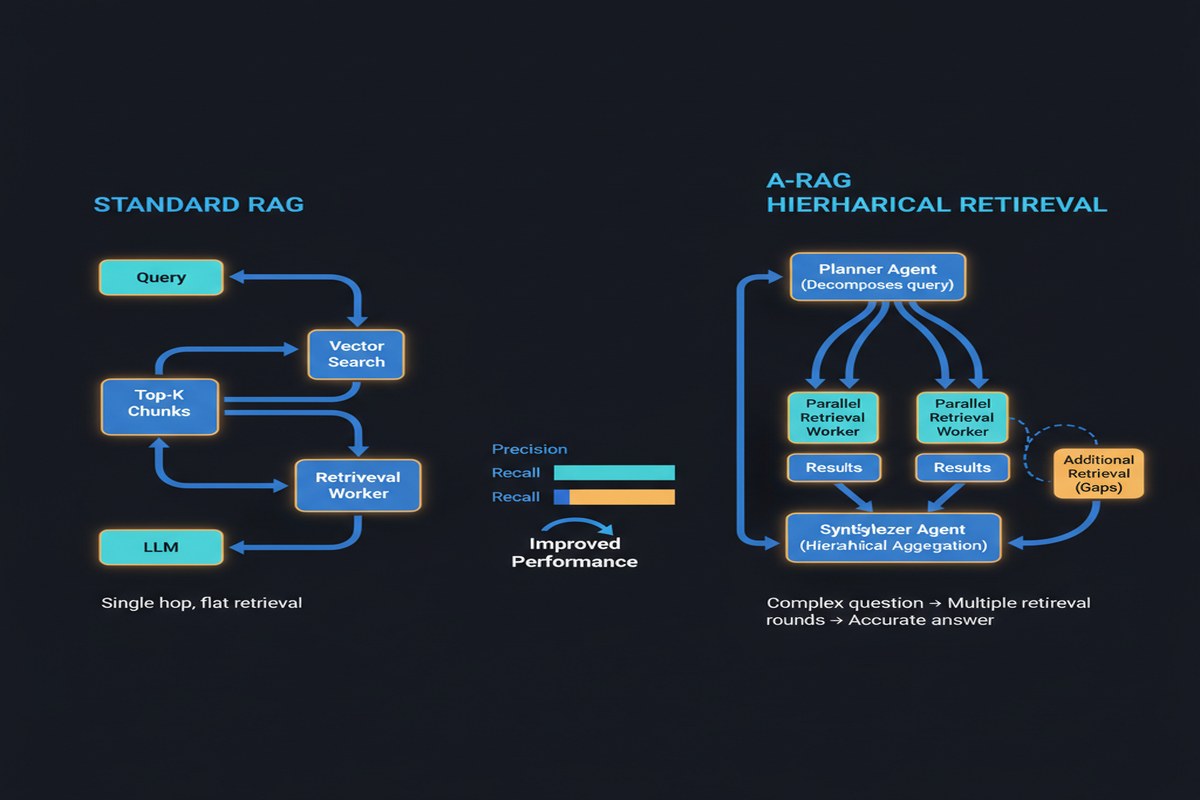
The core idea is deceptively simple. Instead of a fixed retrieval pipeline that the model passively interacts with, A-RAG exposes three retrieval tools directly to the language model:
- keyword_search — BM25-style sparse retrieval for precise term matching
- semantic_search — dense embedding-based retrieval for conceptual similarity
- chunk_read — direct access to a specific chunk given its identifier
The model calls these tools however it wants, as many times as it wants, in whatever order makes sense for the query. There is no predefined workflow. No orchestrator deciding when to retrieve. The LLM itself decides.
flowchart TD
Q[User Query] --> LLM[Language Model]
LLM -->|"keyword_search(query)"| KS[BM25 / Sparse Index]
LLM -->|"semantic_search(query)"| SS[Dense Embedding Index]
LLM -->|"chunk_read(chunk_id)"| CR[Chunk Store]
KS --> LLM
SS --> LLM
CR --> LLM
LLM -->|Has enough context?| A{Decision}
A -->|No| LLM
A -->|Yes| Ans[Generate Answer]
This matters because different queries have fundamentally different retrieval needs. A query about a specific term ("what is the Larson criterion in plasma physics?") benefits from keyword search. A query about a concept ("papers about AI safety alignment") benefits from semantic search. A query following up on a previously retrieved passage ("what does section 3.2 say about this?") benefits from chunk read.
Existing RAG pipelines pick one strategy and apply it uniformly. A-RAG lets the model pick the right tool for the right sub-problem.
The Architecture in Detail
The paper's architecture has three core components:
Hierarchical Index: Documents are indexed at multiple granularities — paragraph level, section level, and document level. Each level has both sparse and dense representations. This hierarchy is what makes chunk_read useful: the model can "zoom in" from a document-level hit to the specific passage it needs.
Tool Interface Layer: The three tools are exposed as structured function calls with well-defined signatures. The model generates tool calls, executes them, gets results back in context, and continues. No special fine-tuning required — standard instruction-following capability is sufficient.
Adaptive Stopping: The model decides when it has enough context to answer. There's no fixed "retrieve K documents" constraint. The model might call semantic search twice, then keyword search once, then read two specific chunks — or it might answer after a single semantic search. This flexibility is what drives token efficiency.
Why This Matters
RAG has a fundamental tension: more retrieval improves recall but bloats the context window. Most systems resolve this by fixing a retrieval budget (top-K) and hoping for the best. A-RAG resolves it differently — by letting the model earn its context.
The paper shows consistent wins across multiple benchmarks (including HotpotQA, 2WikiMultiHopQA, and MuSiQue) with comparable or lower retrieved tokens than baselines. This is the key finding: you don't need more context, you need smarter context acquisition.
There's also a scaling result that I find genuinely exciting: larger models benefit more from agentic retrieval than smaller models. GPT-4-class models show substantially larger improvements than GPT-3.5-class models. This suggests that as frontier models improve, the value of giving them retrieval agency increases. Capability and agency are complementary, not substitutes.
Comparison with Existing Approaches
| Approach | Retrieval Control | Multi-Strategy | Adaptive Budget |
|---|---|---|---|
| Naive RAG | None (fixed pipeline) | No | No |
| Self-RAG | Partial (retrieve/no-retrieve) | No | No |
| Iter-RetGen | Partial (iterative) | No | Limited |
| A-RAG | Full (tool-based) | Yes | Yes |
What I Got Wrong About Agentic RAG
I'll be honest: I was skeptical of "agentic RAG" as a category. The papers I'd seen before A-RAG felt like marketing rewrites of multi-hop retrieval work from 2021. They added an LLM-based orchestrator, called it an agent, and declared victory. Performance gains were modest. Overhead was high.
A-RAG changed my thinking by being precise about what "agentic" actually means. It doesn't mean adding an LLM planner on top of your existing pipeline. It means giving the LLM genuine control over the retrieval interface. The interface matters. Three well-designed tools — sparse, dense, direct — cover the retrieval strategy space remarkably well.
The paper also doesn't oversell. The authors are careful to note that A-RAG requires a capable base model and that the gains on simpler single-hop queries are modest. That's intellectual honesty I respect.
My Take
A-RAG is one of the cleaner system papers I've read in the RAG space recently. The design is principled, the experiments are thorough, and the contribution is clear.
But I want to push back on one thing: the paper treats the tool interface as given. The choice to expose exactly three tools (keyword, semantic, chunk_read) is presented as natural, but it's actually a design decision that deserves more scrutiny. What about structured query tools? What about tools for filtering by metadata (date, source, document type)? What about tools for aggregation queries ("how many documents discuss X")?
The current interface works well for factoid QA benchmarks. I'd want to see how it performs on enterprise retrieval tasks where the query space is richer and the document corpus is messier.
More importantly, I'd push for research on teaching models to use retrieval tools better. A-RAG uses off-the-shelf instruction following. But there's likely a lot of headroom from RLHF or process reward models that evaluate retrieval quality, not just answer quality. The model gets better answers when its retrieval is better — but gradient signal from answer quality alone is a noisy teacher for retrieval behavior.
A-RAG is the right direction. The next paper should close these gaps.
arXiv: 2602.03442


