
There's a version of the AI deployment conversation that almost never happens in hardware circles, and it needs to start happening more. It goes like this: not only does the model need to produce an output, it needs to know when it doesn't know.
This is the uncertainty quantification problem, and it matters enormously in high-stakes domains. A medical diagnostic model that says "malignant — 97% confident" is useful. A model that says "malignant — 61% confident" tells the clinician to run more tests. An autonomous vehicle that knows its object detector is uncertain in foggy conditions can slow down or hand control to a human. A financial risk model that quantifies prediction uncertainty can trigger a human review. Without uncertainty estimates, you get predictions; with them, you get information.
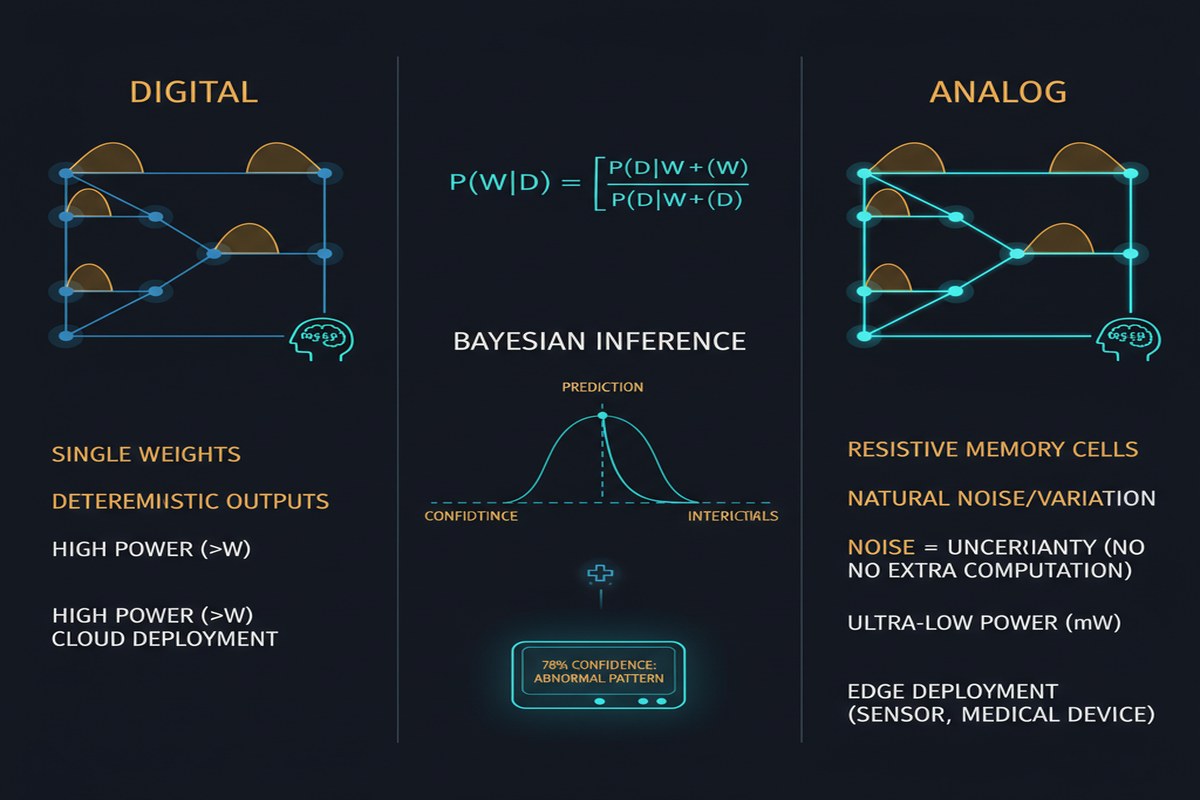
Bayesian neural networks (BNNs) are the principled approach to uncertainty quantification in deep learning. Instead of learning a single set of weights, BNNs maintain a probability distribution over weights — encoding both what the model believes and how confident it is. At inference time, multiple samples from the weight distribution produce predictions whose variance measures uncertainty.
The problem: BNNs are expensive. Standard BNN inference requires sampling from weight distributions and running multiple forward passes, which multiplies inference cost. A paper from October 2025 (arXiv:2510.24951) addresses this for the embedded and analog computing setting — the domain where energy budgets are tightest and uncertainty quantification is often most valuable.
The Embedded AI Uncertainty Gap
Consider the domains where embedded AI is being deployed:
- Medical devices (continuous health monitoring, implantable sensors)
- Industrial quality control (fault detection on assembly lines)
- Autonomous robotics (navigation in unstructured environments)
- Environmental monitoring (anomaly detection in sensor networks)
All of these domains share two characteristics: strict energy constraints (battery-powered or energy-harvesting devices) and a need for reliable uncertainty estimates (because acting on a wrong prediction is costly or dangerous). These two requirements are currently in conflict. BNNs that give good uncertainty estimates are too expensive for embedded hardware. Deterministic networks that run efficiently on embedded hardware don't give uncertainty estimates at all.
The paper attacks this conflict through joint algorithmic and hardware optimization — simultaneously compressing the BNN through model compression and approximate Bayesian inference techniques, and then deploying on both digital ASIC accelerators and analog hardware platforms.
flowchart TD
A[Bayesian Neural Network\nFull precision, expensive] --> B[Joint Optimization]
B --> C[Model Compression\nPruning + Quantization]
B --> D[Approximate Bayesian Inference\nDropout / MC Sampling / Laplace]
C --> E[Compressed BNN]
D --> E
E --> F{Target Hardware}
F --> G[Digital ASIC Accelerator\nLow-power embedded]
F --> H[Analog Computing Platform\nIn-memory inference]
G --> I[Uncertainty Estimates\nLow energy]
H --> I
Approximate Bayesian Inference on Constrained Hardware
Full BNN inference is expensive because:
- Weight distributions need to be stored (2x memory vs. deterministic networks)
- Multiple weight samples need to be drawn at inference time
- Multiple forward passes need to be run for each input
The paper reduces this cost through approximation:
MC Dropout — treating dropout at inference time as approximate Bayesian inference (Gal & Ghahramani, 2016). This requires only a single weight set, uses standard dropout layers for uncertainty, and reduces overhead to the cost of running N forward passes with dropout enabled. No dedicated weight distribution storage required.
Last-layer Laplace approximation — applying the Laplace approximation only to the final classification layer while treating all earlier layers as deterministic. This requires fitting a Gaussian approximation to the posterior over the final layer weights — which can be done in a single post-training step with minimal computational cost.
Low-rank weight perturbation — representing the weight uncertainty as a low-rank perturbation of the mean weights. At inference, the uncertainty contribution is computed via a cheap low-rank matrix multiply rather than full weight sampling.
These approximations reduce the uncertainty estimation overhead from "N full forward passes" to something much cheaper — in some configurations, approaching the cost of a single deterministic forward pass.
The Analog Hardware Dimension
The unique contribution of this paper is evaluating these compressed BNNs on analog computing platforms — specifically, platforms that perform inference using analog in-memory computing (AIMC) with resistive memory devices.
Analog in-memory computing performs matrix-vector multiplications by storing matrix weights as analog conductance values in resistive memory (PCM, RRAM, or similar devices) and performing the multiply as an analog voltage/current computation. This can be 10-100x more energy efficient than digital SRAM-based inference for the right workloads.
The challenge: analog hardware is noisy. Resistive memory devices have inherent conductance variation, drift over time, and read noise. A deterministic network calibrated on ideal hardware may degrade significantly on analog hardware due to these noise sources. But a BNN trained with weight uncertainty already accounts for weight noise — the weight distribution naturally models the hardware-induced variability.
graph LR
subgraph "Analog Hardware Noise Sources"
A[Conductance Variation\n±10% typical] --> D[Performance Degradation]
B[Conductance Drift\nlog-time drift] --> D
C[Read Noise\nkT/C thermal] --> D
end
subgraph "BNN Robustness"
E[Weight Distribution\nmodels uncertainty] --> F[Hardware noise ≈\nweight uncertainty]
F --> G[Natural robustness\nto analog noise]
end
D -.->|BNN mitigates| G
The paper demonstrates that compressed BNNs show better degradation characteristics on analog hardware than equivalently compressed deterministic networks — because the weight uncertainty that BNNs maintain as a feature turns out to be a feature in the face of hardware-induced weight variation.
This is a beautiful result: the property that makes BNNs useful for uncertainty quantification (maintaining weight distributions) also makes them more robust to the noise characteristics of analog hardware. Deploying BNNs on analog hardware is not just a cost-reduction strategy; it may actually be the natural pairing.
Performance Results
The paper evaluates on image classification benchmarks (CIFAR-10, CIFAR-100) and medical diagnosis datasets. Key results:
- Compressed BNNs achieve 85-92% of full-precision BNN accuracy with 4-8x memory reduction
- Uncertainty calibration quality (measured by Expected Calibration Error) is preserved within 5-10% of full-precision BNN even after compression
- Analog hardware deployment degrades deterministic networks by 3-8% accuracy; compressed BNNs degrade by 1-3% — a meaningful robustness advantage
- Energy consumption on analog hardware is 15-30x lower than equivalent digital ASIC deployment
Why This Matters
Uncertainty quantification is not a luxury feature for edge AI — it is a safety requirement for many applications. The fact that reliable uncertainty estimates were previously only achievable with expensive BNNs has effectively excluded uncertainty-aware inference from the embedded AI design space.
This paper demonstrates a path to uncertainty-aware inference on analog hardware at energy budgets compatible with embedded deployment. If this methodology is validated across a wider range of hardware platforms and task domains, it could significantly expand the class of applications where embedded AI can be deployed safely.
The medical and industrial applications are the clearest cases: embedded health monitoring devices that flag uncertain predictions for review, quality control systems that know when to escalate to human inspection, and environmental monitoring nodes that distinguish genuine anomalies from sensor noise. All of these applications need uncertainty — and all of them need to run on constrained hardware.
My Take
This paper tackles a combination of problems that individually have received substantial attention (BNN efficiency, analog AI) but have not previously been addressed together. The insight that analog hardware noise and BNN weight uncertainty are complementary — rather than conflicting — is the most interesting finding.
I do have a concern about the calibration results. The paper shows that uncertainty calibration quality is "preserved within 5-10% of full-precision BNN," but what matters for safety-critical applications is not relative preservation but absolute calibration quality. A system where 90% of 80%-confidence predictions are correct is well-calibrated. A system where 70% of 80%-confidence predictions are correct can lead to dangerous overconfidence in uncertain situations. The paper needs to report absolute calibration curves, not just relative degradation.
The analog hardware robustness advantage is real and important. I want to see it validated on more analog hardware platforms beyond the specific devices used in this study. PCM drift characteristics differ significantly between manufacturers and device generations; showing robustness across multiple analog hardware variants would be much more convincing.
The broader message from this work: the embedded AI field needs to stop treating uncertainty quantification as an afterthought. As AI models make higher-stakes decisions on constrained hardware — medical, industrial, autonomous — knowing when the model doesn't know becomes a first-class engineering requirement, not a research topic.
Resource-Efficient and Robust Inference of Deep and Bayesian Neural Networks on Embedded and Analog Computing Platforms — arXiv:2510.24951, October 2025.


