
Here's a problem that keeps hardware architects awake at night: AI models evolve on a timescale of months. Silicon evolves on a timescale of years. A chip designed today for Llama 3.1 workloads will be deployed in products running whatever comes after GPT-7 or Gemini Ultra 3. The mismatch is structural, and the industry has largely accepted it as an unavoidable tax.
A paper from September 2025 (arXiv:2509.18355) proposes a different answer: what if the AI acceleration fabric itself were modular? Not in the software sense — we already have that with frameworks like TensorRT and ONNX — but in the physical sense. Chiplets that you can swap, upgrade, and compose to match evolving model requirements.
The paper presents a chiplet-based RISC-V SoC architecture with modular AI acceleration. The headline contribution is an architecture where the AI compute fabric is composed from standardized chiplet interfaces, allowing different AI accelerator designs to be drop-in replacements without a full SoC respin.
The Respin Problem
Chip development is expensive and slow. A modern SoC from conception to production takes 18-36 months and costs tens to hundreds of millions of dollars in engineering and mask costs. Once a chip is in silicon, its compute capabilities are fixed. If a new model architecture emerges that requires different compute primitives — say, a shift from dense attention to sparse attention, or from FP16 to FP8 arithmetic — the options are:
- Software-emulate the new primitive on existing hardware (inefficient)
- Wait for the next chip generation (too slow)
- Deploy a co-processor (adds cost and latency)
None of these are satisfying. The chiplet-based RISC-V SoC architecture explores a fourth option: design the SoC such that the AI acceleration tile is a chiplet with a standardized interface, allowing physical replacement of the compute fabric when AI workload requirements change significantly.
graph TD
subgraph "Monolithic SoC (Current)"
A[CPU Cores] --- B[Fixed AI Accelerator]
B --- C[Fixed Memory Controller]
A --- C
end
subgraph "Chiplet-Based RISC-V SoC (Proposed)"
D[RISC-V CPU Chiplet] -->|UCIe Interface| E[AI Accelerator Chiplet v1]
D -->|UCIe Interface| F[Memory Controller Chiplet]
G[AI Accelerator Chiplet v2] -.->|Future Swap| E
end
style B fill:#f99,stroke:#c00
style E fill:#9f9,stroke:#090
style G fill:#99f,stroke:#009
The RISC-V choice is not incidental. RISC-V's open ISA means that the CPU compute tiles can be sourced from multiple vendors without licensing constraints, and the instruction set can be extended with custom AI-relevant instructions (RISC-V supports this through the custom extension mechanism). The combination of an open ISA and chiplet modularity creates an architecture where both the CPU and the AI accelerator layers are independently evolvable.
Architecture Details
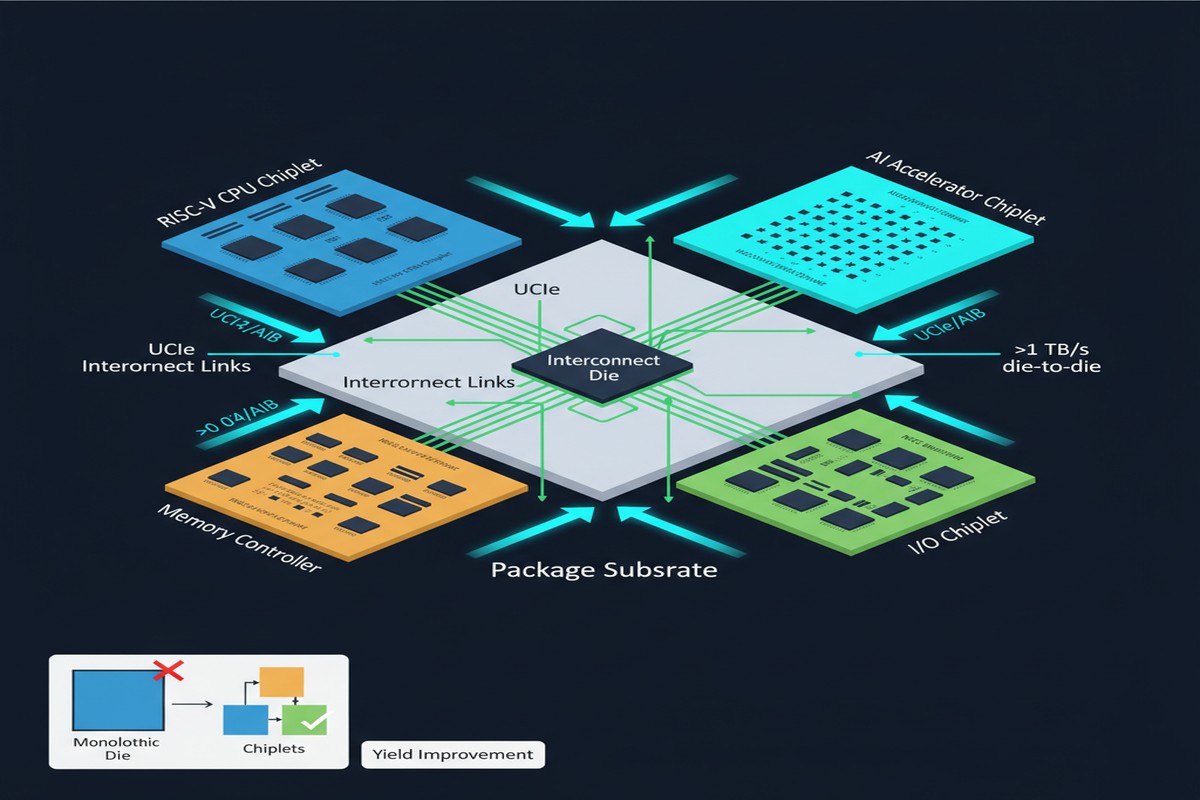
The paper's proposed architecture has three main chiplet categories:
CPU Chiplet — RISC-V cores with extended instruction support for AI-relevant operations (vector operations, matrix multiply accumulate instructions). These handle control flow, pre/post-processing, and operations too irregular for the accelerator.
AI Accelerator Chiplet — The compute-intensive layer. In the paper's prototype, this implements systolic arrays for matrix multiply, dedicated attention compute units, and activation function hardware. The key design decision is the standardized die-to-die interface, which is UCIe-compatible, enabling future accelerator generations to be physically substituted.
Memory Controller Chiplet — Interfaces to off-package DRAM (LPDDR5 in the prototype) and manages coherent data movement between chiplets. The memory controller is isolated as its own chiplet because memory standards evolve independently of compute standards — and having them on separate dies means you can upgrade either without redesigning both.
flowchart LR
subgraph "Package"
A[RISC-V CPU Chiplet]
B[AI Accel Chiplet]
C[Mem Controller Chiplet]
D[Package Substrate]
A <-->|UCIe| B
A <-->|UCIe| C
B <-->|UCIe| C
A --- D
B --- D
C --- D
end
C <-->|LPDDR5| E[Off-Package DRAM]
style B fill:#aaf,stroke:#00a
The paper evaluates performance on standard AI workloads — image classification (ResNet-50), object detection (YOLO variants), and language model inference (lightweight transformer). The key metric is not raw performance but performance-per-dollar-per-year — explicitly accounting for the fact that modularity allows incremental upgrades rather than wholesale platform replacement.
The Intelligent System-Level Optimization Layer
Beyond the chiplet architecture itself, the paper introduces an intelligent system-level optimization layer that profiles workloads at runtime and dynamically assigns operation classes to chiplets. This matters because not all AI operations are best executed on the dedicated accelerator chiplet. Some irregular, control-heavy operations are faster on the RISC-V CPU cores. The runtime optimizer makes these routing decisions automatically.
This is a form of hardware-aware, adaptive scheduling — similar to what Apple does with the Neural Engine, GPU, and CPU in their SoC designs, but implemented at the chiplet granularity rather than the block granularity.
Why This Matters
The chiplet revolution in AI hardware is happening at two levels:
- Memory integration — HBM chiplets stacked on compute dies (already mainstream in H100, MI300X)
- Compute disaggregation — AI accelerator logic as an independently upgradeable chiplet (this paper's contribution)
Level 2 is much more disruptive, because it breaks the assumption that AI compute capability is fixed once silicon is manufactured. If this architecture reaches production at any significant scale, it fundamentally changes the economics of AI hardware for edge and embedded deployment — the markets where long product lifetimes and evolving software requirements create the sharpest mismatch between silicon and model evolution timescales.
For enterprises deploying on-premises AI inference, modularity means amortizing platform cost across multiple model generations rather than buying new hardware every 18 months. For embedded applications (industrial automation, smart sensors, medical devices), it means field-updatable AI compute without replacing the entire device.
My Take
I think the chiplet-based RISC-V SoC direction is correct, but the paper glosses over the hardest problem: die-to-die interface standardization. UCIe is a promising standard, but it's still not universally adopted, and different chiplet vendors implement it with varying performance characteristics (bandwidth, latency, power). The system-level optimization layer that routes operations between chiplets depends critically on the bandwidth and latency of those interconnects. Get the interconnect wrong and modularity becomes a bottleneck, not a feature.
The RISC-V choice deserves more credit than it typically gets in hardware circles. For embedded AI deployment, proprietary ISAs create long-term vendor lock-in that is often more expensive than the upfront licensing cost suggests. RISC-V eliminates this at the ISA level. Combined with UCIe at the physical interface level, you have a plausible open architecture for composable AI hardware.
What I want to see next: real silicon results. The paper presents simulation-based evaluation, which is necessary at this stage but insufficient for production decisions. The interconnect performance characteristics, thermal management across chiplet boundaries, and yield implications of multi-chiplet packages are all factors that simulation cannot fully capture. Get to tape-out and I'll be much more confident in the performance claims.
That said, the direction is right. The AI chip industry cannot keep building increasingly specialized monolithic chips optimized for last year's model architecture. Modularity through chiplets is the architectural answer. This paper is a concrete step toward making that answer practical.
Chiplet-Based RISC-V SoC with Modular AI Acceleration — arXiv:2509.18355, September 2025.


