
Let me describe a frustration that anyone who has tried to deploy a neural network on custom hardware knows intimately. You have a RISC-V accelerator, or a custom ASIC, or a novel neuromorphic chip. You have a trained model. Between those two things sits a chasm: the compiler stack.
TVM can target your hardware — in theory. MLIR can lower your operations — in principle. But both require extensive backend customization. You need to write tensor decomposition schedules, intrinsic mappings, memory allocation heuristics, and tiling strategies by hand, tuned to your specific hardware's register file, cache topology, and dataflow architecture. This manual engineering effort is what makes deploying ML on custom silicon so expensive that only large teams at Apple, Google, and NVIDIA can do it properly.
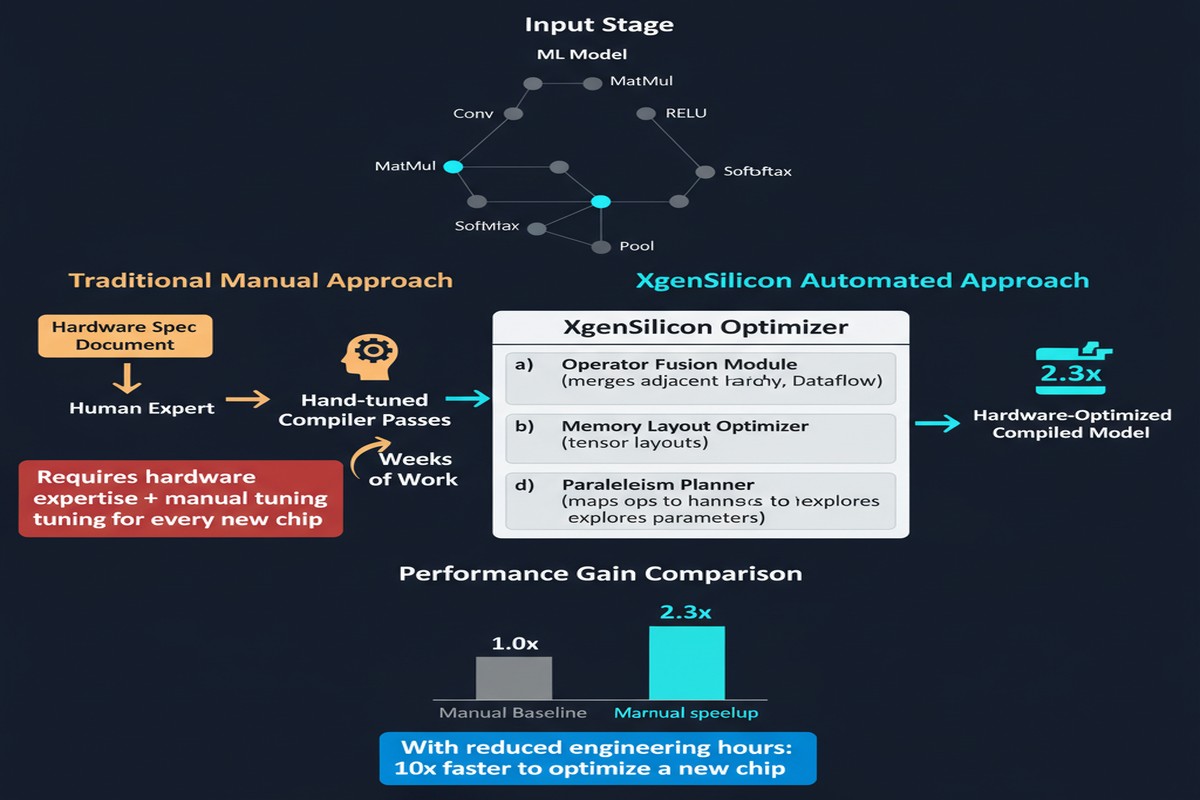
A paper from December 2025 (arXiv:2512.00031) attacks this problem directly. XgenSilicon ML Compiler introduces a fully automated compilation framework for custom RISC-V AI accelerators, replacing manual backend engineering with five search algorithms and a machine-learning-based cost model. The goal: deploy neural networks on custom silicon with zero expert-in-the-loop effort during the optimization phase.
Why Manual Tuning Fails at Scale
The standard ML compiler workflow looks like this:
- Take a neural network graph (from PyTorch, JAX, or ONNX)
- Apply graph-level optimizations (operator fusion, constant folding)
- Lower to hardware-specific code (tiling, vectorization, memory layout)
- Auto-tune: search the schedule space for the configuration that runs fastest on target hardware
Step 4 is where things break down for custom accelerators. Auto-tuning frameworks like TVM's AutoTVM or Ansor assume a hardware target they can sample quickly — either through hardware-in-the-loop execution or fast simulation. For novel custom accelerators, neither option is cheap. Hardware simulation is slow; real hardware may not be available in the quantities needed for extensive search.
XgenSilicon addresses this with a learned cost model — a surrogate model trained to predict execution time on the target hardware from a set of schedule configuration features, without running every candidate configuration on silicon.
flowchart TD
A[Neural Network Model] --> B[Graph Optimization\nOperator Fusion, Constant Folding]
B --> C[Schedule Space Generation]
C --> D{Search Algorithm}
D --> E[Bayesian Optimization]
D --> F[Genetic Algorithm]
D --> G[Simulated Annealing]
D --> H[Random Search]
D --> I[Grid Search]
E --> J[Learned Cost Model]
F --> J
G --> J
H --> J
I --> J
J --> K[Predicted Execution Time]
K --> L{Best Schedule Found?}
L -->|No| D
L -->|Yes| M[RISC-V Code Generation]
M --> N[Deployment on Custom Accelerator]
The five search algorithms are not chosen arbitrarily. They represent qualitatively different tradeoffs in the search space exploration:
- Bayesian Optimization — sample-efficient, works well when evaluation is expensive; builds a probabilistic model of the schedule performance landscape
- Genetic Algorithm — population-based, good at escaping local optima; useful when the landscape is highly non-convex
- Simulated Annealing — classic randomized local search; fast convergence for moderate-dimensional search spaces
- Random Search — often surprisingly competitive, serves as a baseline and fallback
- Grid Search — exhaustive over small spaces; guarantees optimality within the searched region
The learned cost model sits between any of these search algorithms and the actual hardware. Instead of sampling hardware performance for every candidate schedule, the algorithms query the cost model — which is fast — and only periodically validate predictions with actual hardware execution. This creates a sample-efficient search loop.
The RISC-V Target Architecture
The paper's target hardware is a custom RISC-V accelerator with ML-specific custom instructions — vector dot products, matrix multiply accumulate, and activation function primitives added via RISC-V's custom extension mechanism. The accelerator is representative of the class of RISC-V-based ML chips emerging from both academic labs and commercial startups (SiFive, Esperanto, Tenstorrent's RISC-V roadmap).
The compiler needs to understand:
- How to vectorize operations to use the custom instruction set
- How to tile matrix multiplications to fit the accelerator's scratchpad memory
- How to schedule data movement between DRAM and scratchpad to overlap with compute
- Which operations to fuse to eliminate intermediate memory writes
Previously, each of these decisions required hardware-specific engineering expertise. XgenSilicon automates all of them through the learned cost model and search framework.
graph LR
subgraph "XgenSilicon Search Space"
A[Tiling Factor: M]
B[Tiling Factor: N]
C[Tiling Factor: K]
D[Vectorization Width]
E[Loop Order]
F[Scratchpad Allocation]
end
subgraph "Learned Cost Model"
G[Feature Extraction]
H[Gradient Boosted Tree / Neural Net]
I[Predicted Latency]
end
A --> G
B --> G
C --> G
D --> G
E --> G
F --> G
G --> H --> I
The paper reports results on ResNet-50, MobileNetV2, BERT-base, and a lightweight GPT-2 variant. Across all benchmarks, XgenSilicon finds schedules within 5-15% of manually tuned baselines — while requiring zero expert engineering effort and completing the full optimization in under an hour on a workstation. For comparison, manual tuning by hardware experts typically takes weeks per model.
The Compiler Gap
The AI hardware community has a dirty secret: most of the performance difference between "works in theory" and "works in practice" on custom silicon is compiler quality, not hardware capability. NVIDIA's dominance in AI compute is not entirely because their hardware is better. It is substantially because CUDA, cuDNN, and TensorRT represent 15 years of compiler and library engineering. Custom accelerators cannot replicate this depth quickly.
XgenSilicon is an attempt to close this gap programmatically — using ML to optimize ML deployment. The irony is not lost on me, and I think it's the right approach.
Why This Matters
The stakes here are not academic. AI chip startups and research labs are designing novel accelerators constantly, but most of them cannot achieve good real-world performance because they lack the compiler infrastructure. A working model deployed with a mediocre hand-tuned schedule runs 2-5x slower than the hardware's theoretical peak. A 5x slowdown at the hardware layer means you need 5x more chips for the same throughput — completely eliminating the cost advantage of a more efficient architecture.
If automated ML compiler optimization works reliably — and the XgenSilicon results suggest it can, within an acceptable performance gap — then the barrier to building competitive custom AI hardware drops significantly. This matters most for:
- Academic research accelerators — enabling researchers to actually benchmark new hardware ideas against real model workloads, not just synthetic benchmarks
- AI chip startups — removing the compiler engineering bottleneck from the critical path to product readiness
- Edge AI deployment — custom embedded hardware with constrained resources where manual tuning is impractical at product scale
My Take
The learned cost model approach is the correct investment, but I have a concern about generalization. Cost models trained on one hardware configuration may not transfer well to a substantially different architecture — different cache sizes, different memory bandwidth, different custom instruction latencies. The paper evaluates on a single target RISC-V configuration. The methodology should work across configurations in principle, but you'll need to retrain the cost model for each new hardware target, which requires profiling data collection on the new hardware.
The five-algorithm search ensemble is a practical hedge against not knowing which search algorithm will work best for any given hardware-model combination. But it also suggests the authors don't yet have a principled understanding of which algorithm wins under what conditions. That understanding would let you skip straight to the right algorithm rather than running all five.
What I find most valuable in this work is the framing: the problem is not "how do we write better compiler backends" but "how do we automate the compiler backend engineering process entirely." That reframing is the key insight. The hardware-software co-design community has spent decades assuming expert engineering was necessary for the compilation layer. XgenSilicon challenges that assumption and makes a credible case that ML-guided search can replace much of it.
The day when you can design a custom RISC-V AI accelerator, spec it in RTL, and have an automated compiler framework produce near-optimal code for any model is still a few years away. But XgenSilicon is a significant step in that direction.

Hardware-Aware Neural Network Compilation with Learned Optimization: A RISC-V Accelerator Approach — arXiv:2512.00031, December 2025.


