
Quantization is the open secret of LLM deployment. Virtually every production deployment of a large language model uses some form of quantization — reducing weights from 16-bit or 32-bit floating point down to 8-bit integers, 4-bit integers, or even lower. The memory savings are real and the inference speedup on standard hardware is measurable. But here's what doesn't get said loudly enough: most hardware doesn't natively support the mixed-precision operations that quantized LLMs actually need.
When you quantize weights to INT4 but keep activations in FP16 — the most common practical configuration — you need to perform what's called mixed-precision General Matrix Multiply (mpGEMM): multiplying lower-precision weights by higher-precision activations. Off-the-shelf GPU tensor cores do not support this natively. The standard workaround is dequantization: convert INT4 weights back to FP16 before the multiply, losing most of the memory bandwidth benefit you gained by quantizing in the first place.
The LUT Tensor Core paper, accepted at ISCA 2025 (arXiv:2408.06003), attacks this problem from both the software and hardware sides simultaneously. The result is a co-designed system where software optimizations and hardware design decisions reinforce each other — achieving 1.44x better compute density and energy efficiency compared to the prior state-of-the-art in LUT-based accelerators.
The Lookup Table Alternative
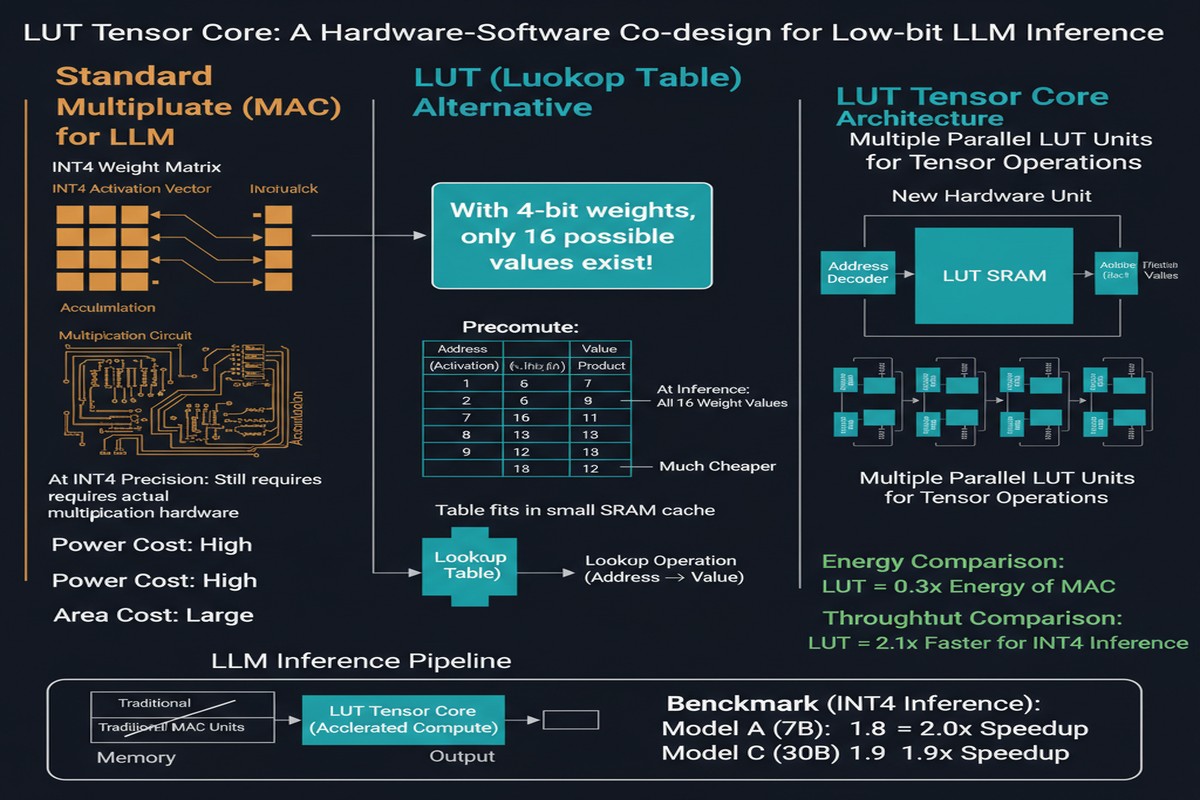
The core idea is elegant. Instead of computing a matrix multiply by performing individual multiplications between weight values and activation values, you precompute all possible products for each set of weight values and store them in a lookup table (LUT). At inference time, you look up the result rather than computing it.
For low-bit weights, this is practical because the number of possible weight values is small:
- INT8: 256 possible values → lookup table of 256 entries
- INT4: 16 possible values → lookup table of 16 entries
- INT2: 4 possible values → lookup table of 4 entries (tiny)
For INT4 weights with FP16 activations, the LUT contains 16 FP16 values — one for each possible weight value multiplied by the current activation chunk. Looking up from a 16-entry table is much cheaper than performing 16 multiplications.
flowchart LR
subgraph "Traditional Dequantization Approach"
A[INT4 Weights] -->|Convert to FP16| B[FP16 Weights]
C[FP16 Activations] --> D[FP16 x FP16 Multiply]
B --> D
D --> E[FP16 Outputs]
end
subgraph "LUT Tensor Core Approach"
F[INT4 Weights] --> G[LUT Precompute:\n16 entries per activation chunk]
H[FP16 Activations] --> G
G --> I[Table Lookup]
I --> J[Accumulate Results]
J --> K[FP16 Outputs]
end
style D fill:#f99,stroke:#c00
style I fill:#9f9,stroke:#090
The problem with a naive LUT implementation is that the precomputation overhead can negate the lookup savings. If you're rebuilding the lookup table too frequently — once per row, once per activation value — the precomputation time dominates. Prior LUT-based designs struggled with this.
The Three-Layer Co-Design
LUT Tensor Core's contribution is a three-layer co-design that addresses the precomputation overhead, storage requirements, and hardware utilization simultaneously.
Layer 1: Software Optimizations
The software layer introduces two key ideas:
- Table precompute minimization — the authors analyze when LUTs can be reused across multiple matrix operations without recomputation. By carefully organizing weight access patterns, they reduce precompute frequency significantly.
- Weight reinterpretation — rather than treating each weight element independently, the software groups weights in ways that allow larger LUT sharing, reducing total storage requirements.
Layer 2: Hardware Design — LUT-Based Tensor Core
The hardware design introduces an elongated tiling shape. Standard tensor cores use square tiles (e.g., 16x16 or 8x8 matrix blocks) for weight and activation matrices. LUT Tensor Core uses elongated tiles that maximize table reuse — wider in the weight dimension, allowing the same LUT to be applied across more activation values before needing to recompute.
Additionally, the hardware uses a bit-serial design in the weight dimension, supporting diverse precision combinations (INT2, INT4, INT8 weights against FP16, FP32 activations) with the same hardware through time-multiplexed operation. This makes the Tensor Core a universal low-bit accelerator rather than a fixed-precision unit.
graph TD
subgraph "LUT Tensor Core Hardware"
A[Weight Registers\nINT2/INT4/INT8] --> B[LUT Index Generator]
C[Activation Chunk\nFP16] --> D[LUT Precompute Unit]
D --> E[LUT SRAM\nElongated Tile Buffer]
B --> F[Lookup Engine]
E --> F
F --> G[Bit-Serial Accumulator]
G --> H[FP16 Output Accumulator]
end
subgraph "Performance Gains"
I[1.44x Compute Density vs Prior LUT]
J[1.44x Energy Efficiency vs Prior LUT]
K[Supports INT2/INT4/INT8 Weights]
end
Layer 3: Instruction Set and Compilation
A new instruction set is defined for LUT-based mpGEMM that exposes the LUT precompute, lookup, and accumulate operations explicitly to the compiler. The compiler optimization then schedules these instructions to overlap LUT precompute for future tiles with lookup execution for current tiles — hiding the precomputation latency through software pipelining.
This instruction-compiler co-design is where the hardware-software co-design label is most earned. Neither the hardware nor the software optimization alone produces the full result. It's the interplay between the elongated tile hardware (enabling table reuse) and the compiler's pipelined scheduling (hiding precompute latency) that delivers the 1.44x improvement.
Why Mixed-Precision mpGEMM Is the Critical Bottleneck
Let me put this in context. The current production reality of LLM inference:
- Models are trained in BF16 or FP32
- Deployed with INT4 or INT8 weights (post-training quantization)
- Activations remain FP16 during inference (quantizing activations is harder without quality loss)
- The weight-activation multiply is therefore mpGEMM: INT4 × FP16
This configuration — INT4 weights, FP16 activations — is used in virtually every serious production LLM deployment today. AWQ, GPTQ, and other popular quantization frameworks all produce this format. Hardware that does not support mpGEMM natively forces dequantization, which largely undoes the memory efficiency benefits of quantization.
LUT Tensor Core directly targets the production deployment scenario. This is not a toy academic benchmark.
Why This Matters
The implications extend beyond the energy and performance numbers:
Edge inference viability — INT4 LLM inference on edge hardware is practically limited today by the mpGEMM inefficiency. A LUT-based hardware primitive that efficiently handles INT4 × FP16 could enable substantially larger models on battery-powered devices.
Data center efficiency — At the data center scale, the energy efficiency of each matrix multiply operation compounds enormously. A 1.44x improvement in energy efficiency for mpGEMM translates to proportional improvements in cost per token and carbon per inference.
Quantization confidence — One reason model developers are hesitant to quantize more aggressively (to INT2 or INT3) is that the hardware support is poor. LUT Tensor Core's bit-serial design supports INT2 weights natively. If INT2 inference were hardware-efficient, we would see more models aggressively quantized to INT2, potentially enabling another step change in model size vs. compute cost tradeoffs.
My Take
The hardware-software co-design approach here is the right architecture philosophy, and I'm glad to see it validated at ISCA — the top computer architecture venue. The software and hardware communities have historically been bad at co-design: software people assume hardware is fixed, hardware people design for idealized workloads that don't reflect real model deployments.
LUT Tensor Core demonstrates what you can achieve when both layers are designed together. The elongated tiling shape only makes sense because the software knows to exploit it through the instruction scheduler. The new instruction set only delivers benefits because the hardware exposes the right hooks for the compiler.
My concern: the ISCA paper demonstrates hardware design analysis and simulation, not a fabricated chip. The real-world gains on manufactured silicon could differ from simulation results, particularly in areas like LUT SRAM latency under realistic process variation. Seeing a tape-out and post-silicon measurements would significantly strengthen the case.
The broader takeaway: the industry's fixation on GPU FLOPS as the primary inference efficiency metric is increasingly misleading. For quantized LLM inference — which is how the vast majority of models are actually deployed — the relevant metric is mpGEMM throughput per watt. LUT Tensor Core offers a better answer to that metric than any existing hardware, and it does so through a genuinely novel architectural idea rather than incremental FLOPS scaling.
LUT Tensor Core: A Software-Hardware Co-Design for LUT-Based Low-Bit LLM Inference — ISCA 2025, Tokyo, June 2025. arXiv:2408.06003.


