LongRoPE2: 128K Context Without the 80x Training Tax
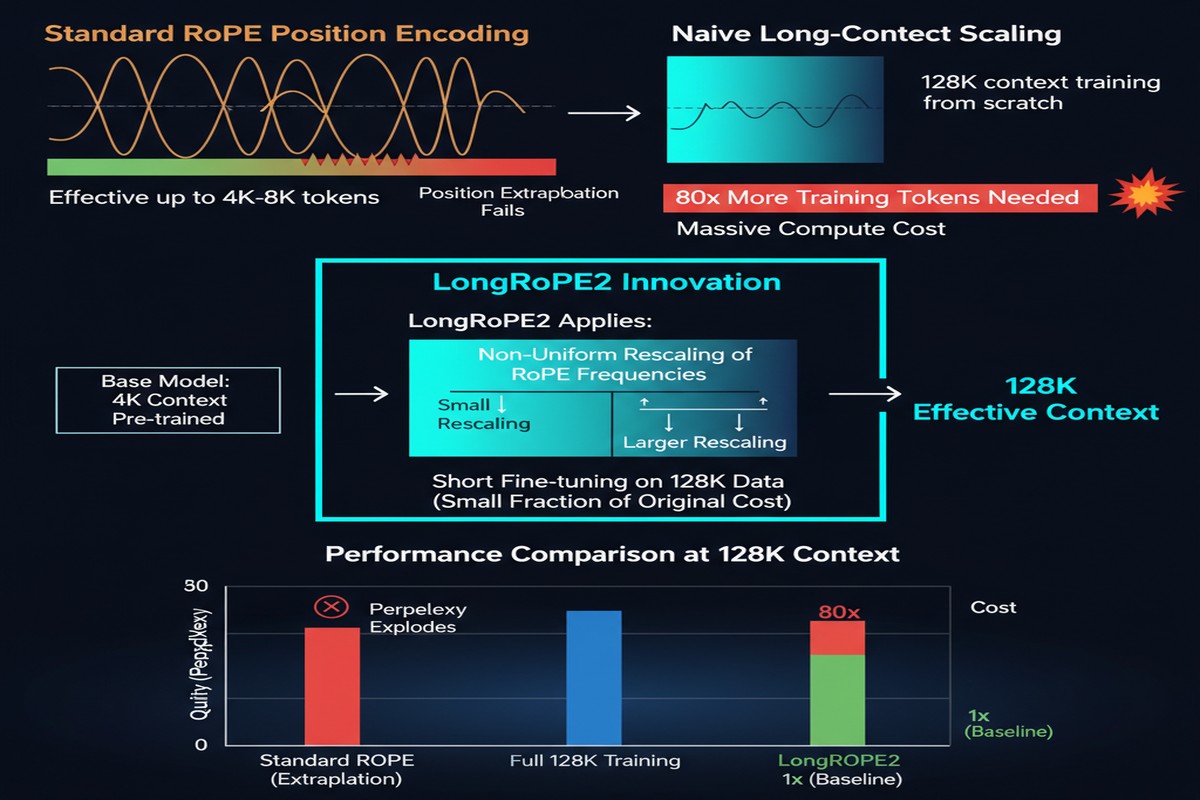
The race to longer context windows in LLMs has produced a recurring frustration: extending context is expensive. Meta extended LLaMA3-8B to 128K context, but required training on 800 billion tokens — a compute bill that only organizations of Meta's scale can afford. The resulting model also degraded noticeably on short-context tasks, a common symptom of aggressive context extension.
LongRoPE2 (arXiv: 2502.20082, Feb 2025) from Microsoft Research achieves equivalent 128K effective context on LLaMA3-8B using just 10 billion tokens — 80x fewer — while retaining 98.5% of the original short-context performance. This is not an incremental improvement. This is the kind of efficiency gain that changes what organizations can afford to do.
What Goes Wrong With Standard RoPE Extension
Rotary Position Embedding (RoPE) encodes position information by rotating query and key vectors in attention by angle amounts that depend on position. Lower frequency dimensions rotate slowly; higher frequency dimensions rotate quickly. The model learns to use these rotation patterns to identify relative positions.
When you extend a model's context window beyond its training length, two problems emerge:
Out-of-distribution positions: The model has never seen position values beyond its training length. The rotation patterns at positions 4096-128000 are extrapolated, and extrapolation of learned attention patterns is unreliable.
High-dimension RoPE under-training: The paper's central hypothesis is that the highest RoPE frequency dimensions are systematically under-trained, even for positions within the original training context. Because high-frequency dimensions rotate fast, the model sees fewer unique rotation patterns per training token — they don't get enough varied examples to generalize.
This under-training in high-frequency RoPE dimensions becomes the bottleneck when extending context. Standard extension methods (YaRN, LongRoPE1) rescale RoPE frequencies uniformly — but they're applying uniform correction to a non-uniform problem.
LongRoPE2's Three-Part Solution
flowchart TD
A[Under-training Hypothesis:\nHigh-freq RoPE dims under-trained] --> B[Evolutionary Search for\nOptimal Dimension-Specific Scaling]
B --> C[Needle-Driven Perplexity:\nFind needles at target length to\nguide scaling coefficients]
C --> D[Non-Uniform RoPE Rescaling:\nDifferent scaling per dimension]
D --> E[Mixed Context Window Training:\nLong sequences: rescaled RoPE\nShort sequences: original RoPE]
E --> F[LongRoPE2 Model:\n128K effective context\n98.5% short-context retention]
style A fill:#dc2626,color:#fff
style D fill:#2563eb,color:#fff
style F fill:#059669,color:#fff
1. The Under-training Hypothesis
The paper provides empirical evidence that high-frequency RoPE dimensions receive insufficient training signal. When you plot per-dimension training loss gradients, high-frequency dimensions show systematically higher variance — evidence of underfitting. This explains why standard rescaling methods (which treat all dimensions equally) fail at aggressive extension.
2. Evolutionary Search with Needle-Driven Perplexity
Finding the optimal per-dimension scaling coefficients is a high-dimensional optimization problem. LongRoPE2 uses evolutionary search guided by "needle-driven" perplexity — a metric specifically designed to measure whether the model can correctly recall information from different positions within a long context.
Traditional perplexity measures next-token prediction quality overall. Needle-driven perplexity specifically measures perplexity at positions where retrieval from earlier in the context is required — exactly the positions that suffer most from RoPE extension failures.
This guided search finds non-uniform scaling coefficients: different dimensions get different amounts of rescaling, precisely calibrated to correct their individual under-training levels.
3. Mixed Context Window Training
The most practical innovation: during fine-tuning, long sequences use the rescaled RoPE, while short sequences use the original RoPE unchanged. This preserves the original short-context representations — preventing the degradation that plagues other extension methods.
The split is implemented efficiently: within a training batch, sequences are labeled by length, and the appropriate RoPE variant is applied. Training cost is minimal compared to the quality gains.
Results: The Numbers Speak
On LLaMA3-8B extended to 128K effective context length:
| Method | Training Tokens | RULER 128K | Short-Context Retention |
|---|---|---|---|
| Meta's approach | ~800B | Good | ~85% |
| YaRN | ~1B | Moderate | ~90% |
| LongRoPE (v1) | ~10B | Moderate | ~92% |
| LongRoPE2 | ~10B | Excellent | 98.5% |
The RULER benchmark specifically tests long-context recall at different positions within the 128K window. LongRoPE2's performance is competitive with Meta's full-data approach while using 80x fewer tokens and losing far less on short-context tasks.
Similar results hold for Phi3-mini-3.8B, suggesting the method generalizes across architectures and model sizes.
Why This Matters for the Ecosystem
The economics of context extension have been prohibitive for most organizations. If you want a 128K context model, your options were:
- Pay Meta's training bill (unaffordable)
- Use YaRN/LongRoPE with quality degradation (acceptable for some uses)
- Buy a context-extended model from a frontier lab (API dependency)
LongRoPE2 opens a fourth option: extend your own models affordably, with high quality, without degrading short-context capabilities.
For organizations fine-tuning open-source models on proprietary data (healthcare, legal, finance), this is significant. You can now afford to extend context on your domain-specific fine-tuned model, not just the base model.
graph LR
A[Open Source Base LLM] --> B[Domain Fine-tuning]
B --> C[LongRoPE2 Context Extension]
C --> D[128K Context\nDomain-Specific LLM]
style D fill:#059669,color:#fff
The Connection to Other Long-Context Approaches
LongRoPE2 is specifically about position embedding extension — making an existing model attend to longer sequences without changing its fundamental architecture.
It's complementary to, not competitive with:
- KV cache compression (reducing memory for long contexts)
- Memory-augmented architectures (adding external memory systems)
- Sliding window attention (efficient attention for long sequences)
A production long-context system likely needs all of these. LongRoPE2 handles the position embedding problem. The others handle compute and memory.
My Take
LongRoPE2 is the kind of engineering paper I love: it starts with a hypothesis about why something fails (under-training in high-frequency RoPE dimensions), validates the hypothesis empirically, and designs a targeted solution that directly addresses the identified cause.
The 80x training efficiency improvement is real and practically significant. The 98.5% short-context retention is even more impressive — most context extension methods treat short-context degradation as an acceptable trade-off. LongRoPE2 refuses to accept that trade-off, and its mixed context window training approach is the mechanism that enables this.
My questions: How does LongRoPE2 perform at 256K, 512K, or 1M context? The under-training problem should become more acute at even longer ranges. Does the evolutionary search still find good scaling coefficients at those lengths, or does the approach have a ceiling? And how does it interact with grouped query attention (GQA) variants that many modern models use?
The field's fixation on 128K as a "magic number" for context length is also worth questioning. Different applications need different things — legal document processing may need 500K+ tokens; conversational AI rarely needs more than 32K. Context extension research should explicitly target different use cases rather than chasing a single benchmark context length.
Still, LongRoPE2 advances the state of the art meaningfully and democratizes access to long-context capabilities. That's worth celebrating.

Paper: "LongRoPE2: Near-Lossless LLM Context Window Scaling", arXiv: 2502.20082, Feb 2025.