Paper: Recursive Language Models arXiv: 2512.24601 | December 2025 Authors: Alex L. Zhang, Tim Kraska, Omar Khattab (MIT)
The context window arms race of 2024-2025 has been spectacular and slightly absurd. We went from 8K tokens to 128K to 1M to Llama 4's 10M. The benchmarks look impressive. The reality is messier. Throwing tokens at a model is not the same as making it reason over them well — and the evidence on whether models actually use long contexts effectively is mixed at best.
Recursive Language Models (RLMs) propose a different answer to the long-context problem. Instead of extending the context window, treat the prompt as an external environment the model can navigate. Let the model decompose long inputs into manageable chunks, call itself recursively on those chunks, and aggregate the results. The result: a standard 8K-context model that can handle 10M-token inputs, often outperforming native long-context frontiers models on the same tasks.
The Problem With Extending Context Windows
Let me be blunt about what extended context windows actually do and don't do.
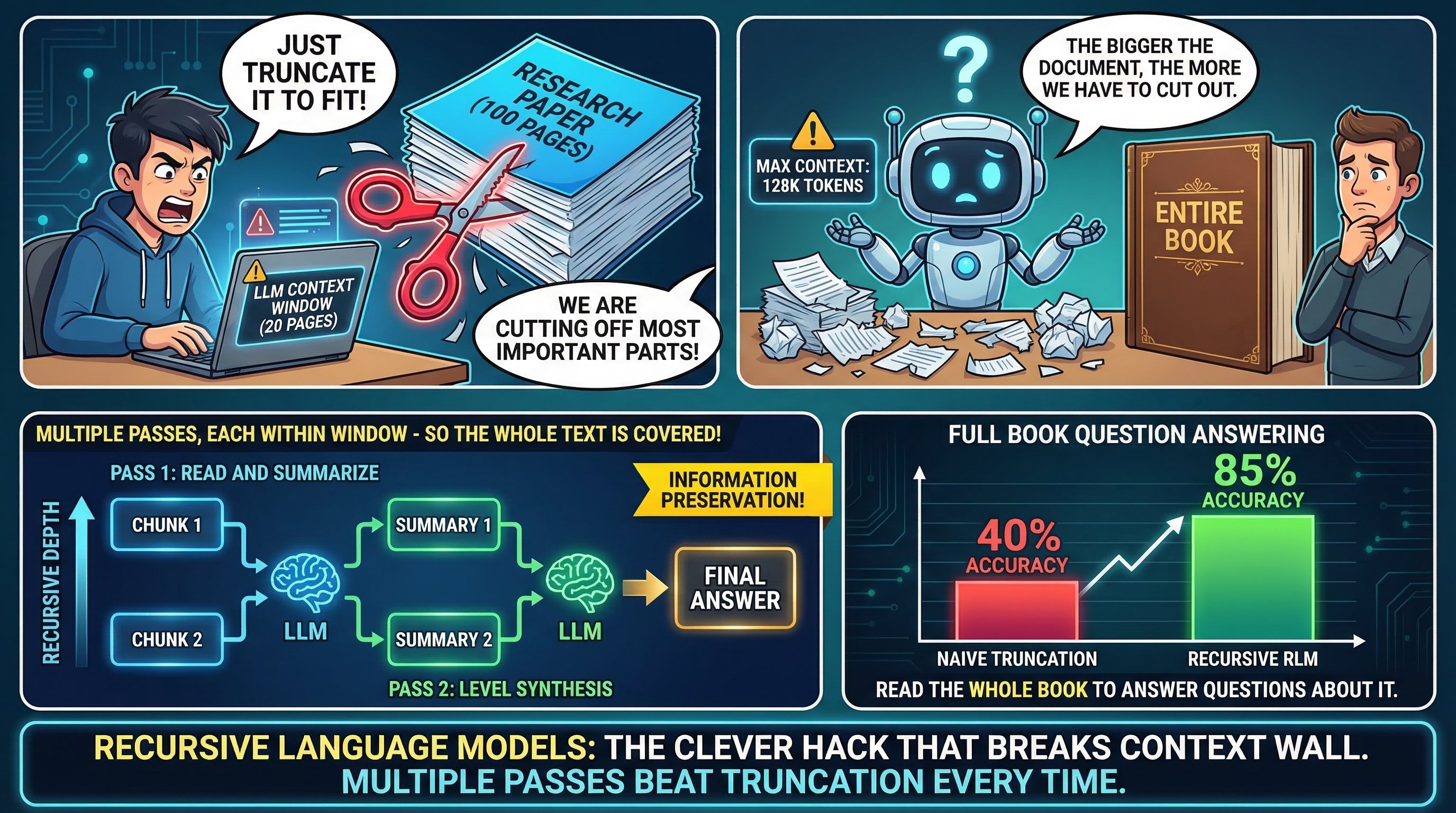
What they do: allow you to stuff more text into a single forward pass. Models with 1M-token context can technically "see" an entire codebase, a lengthy legal document, or a book.
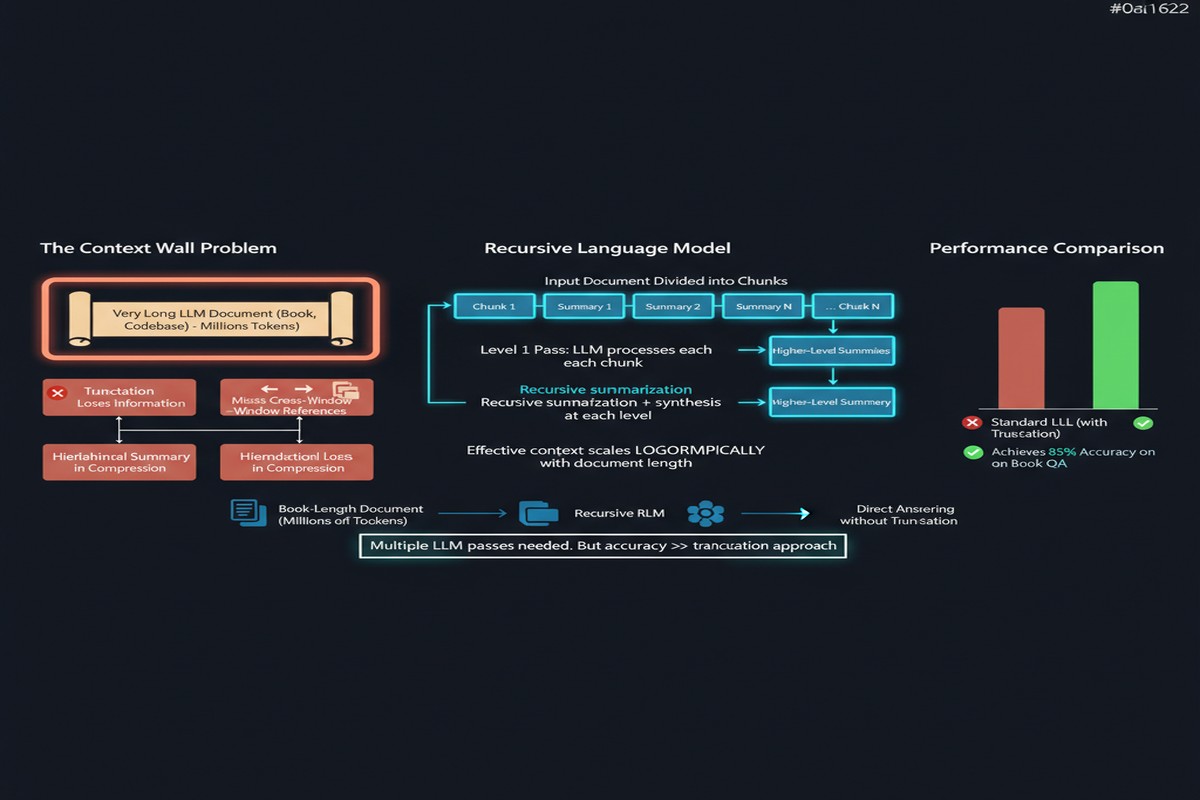
What they struggle with: actually reasoning over that content effectively. Empirical research consistently shows that LLM performance degrades as inputs get longer — the "lost in the middle" problem, attention dilution, and the sheer challenge of linking distant pieces of information are real phenomena that bigger context windows don't automatically solve.
Also: long-context inference is expensive. Processing 1M tokens in a single forward pass requires quadratic memory in the attention mechanism (mitigated by FlashAttention but not eliminated), and the KV cache for such inputs is enormous. The engineering cost is high, and most queries don't need it.
RLMs propose a paradigm shift: instead of processing everything simultaneously, process it recursively.
How Recursive Language Models Work
The core idea is that an LLM can be given tools — specifically, a Python REPL — and instructed to treat long inputs as external data to be examined programmatically rather than as tokens to be attended over.
flowchart TD
A[Long Input Document: 10M tokens] --> B[RLM receives task + Python REPL tool]
B --> C[Model examines document structure]
C --> D{Can solve directly?}
D -- "Yes: chunk is small enough" --> E[Process chunk, return result]
D -- "No: too long" --> F[Decompose into sub-chunks]
F --> G[Call self recursively on each sub-chunk]
G --> H[Aggregate results from recursive calls]
H --> I[Return to parent call]
I --> J[Final Answer]
style G fill:#4a9eff,color:#fff
style F fill:#ff6b6b,color:#fff
The model stores the long input in a Python variable in its REPL environment. When asked a question about it, instead of trying to attend over the entire thing, it writes code to inspect, slice, and process the input — calling itself recursively on manageable chunks as needed.
This is not just prompt engineering. The researchers also fine-tune a dedicated model (RLM-Qwen3-8B) to excel at this recursive paradigm, trained specifically to decompose long-context problems and aggregate recursive results coherently.
Performance at Scale
The results are striking. RLM-Qwen3-8B, trained on this paradigm, outperforms the underlying Qwen3-8B model by 28.3% on average across long-context tasks. On three out of four tasks, it approaches the quality of GPT-5 operating natively on the same inputs.
More importantly: RLMs maintain near-constant performance up to inputs of 10M tokens and beyond, while native long-context models degrade progressively. The degradation pattern for standard models is well-documented; RLMs don't exhibit it because they never force attention over the entire input at once.
Cost comparison is also favorable. Processing 10M tokens in a single forward pass is prohibitively expensive for most inference infrastructure. Recursive calls on 8K-token chunks, even many of them, are often cheaper because smaller chunks are more likely to trigger early termination and the compute parallelizes better.
Why This Matters
1. It decouples architectural context limits from effective context limits. You don't need a special million-token model to process million-token inputs. Any model with good tool use can be extended via this paradigm. The implication: model releases no longer need to compete on context window size — they need to compete on reasoning quality over chunks.
2. It scales to inputs no one has context windows for. 10M tokens is the current frontier for context windows. But there are real-world use cases that exceed this: full enterprise codebase analysis, multi-year document repositories, entire legal case histories. RLMs handle these without architecture changes.
3. It's closer to how humans actually reason. When I read a long technical specification, I don't try to hold all of it in working memory simultaneously. I navigate it, index it, look up specific sections when needed, and summarize. RLMs replicate this more cognitively plausible approach.
4. Recursive architectures are inherently parallelizable. Independent sub-chunks can be processed in parallel. The recursive structure naturally maps to a tree of API calls that can run concurrently. For teams with access to parallel compute, this can be significantly faster than sequential long-context inference.
My Take
This paper excites me more than most of what I've read in the long-context space. The insight is conceptually clean: if you can't extend the model, extend the system. Use the model's reasoning and tool-use capabilities to transcend its architectural limits.
What I find particularly compelling is the trained-model variant. A fine-tuned RLM is not just prompt engineering with recursive calls — it has internalized the decomposition-and-aggregation skill during training. That means the recursive reasoning quality is fundamentally better than what you'd get by naively prompting a standard model with "divide this into chunks."
My skepticism: the evaluation is primarily on structured long-context retrieval and comprehension tasks. The harder question is how RLMs perform on tasks requiring synthesis across a long document — where the answer emerges from integrating information spread across many chunks, not from reading any single chunk carefully. Recursive aggregation of local summaries may lose cross-chunk relationships that matter for synthesis.
I'm also watching whether the Python REPL dependency creates practical friction. In production agentic systems, giving models free code execution for long-context navigation adds a security surface. The efficiency gains are real, but so is the engineering overhead of sandboxed execution environments.
Despite these concerns: RLMs represent a meaningful architectural idea for long-context processing, and the paper makes a strong empirical case. I expect to see this approach adopted and extended significantly in 2026, particularly in agentic codebases where long-context reasoning is a core requirement.
arXiv:2512.24601 — read the full paper at arxiv.org/abs/2512.24601