
Everyone building RAG at scale knows the latency problem. You retrieve 10 passages at 512 tokens each. That's 5,000 tokens of context before you even start generating. The LLM processes all of it, paying full attention cost across every retrieved token, to produce an answer that probably only needed 200 tokens of relevant context to generate.
This is not a subtle inefficiency. It's a massive structural waste that the RAG community has largely accepted as unavoidable.
REFRAG, published September 2025 by Xiaoqiang Lin, Aritra Ghosh, and colleagues from NUS and other institutions, does not accept it as unavoidable. Their approach — compression, sensing, and expansion at the decoding level — achieves approximately 30x acceleration on time-to-first-token without accuracy loss. That's not an incremental improvement. That's a qualitative change in what's feasible for RAG deployment.
The Root Cause: Sparse Attention Over Dense Context
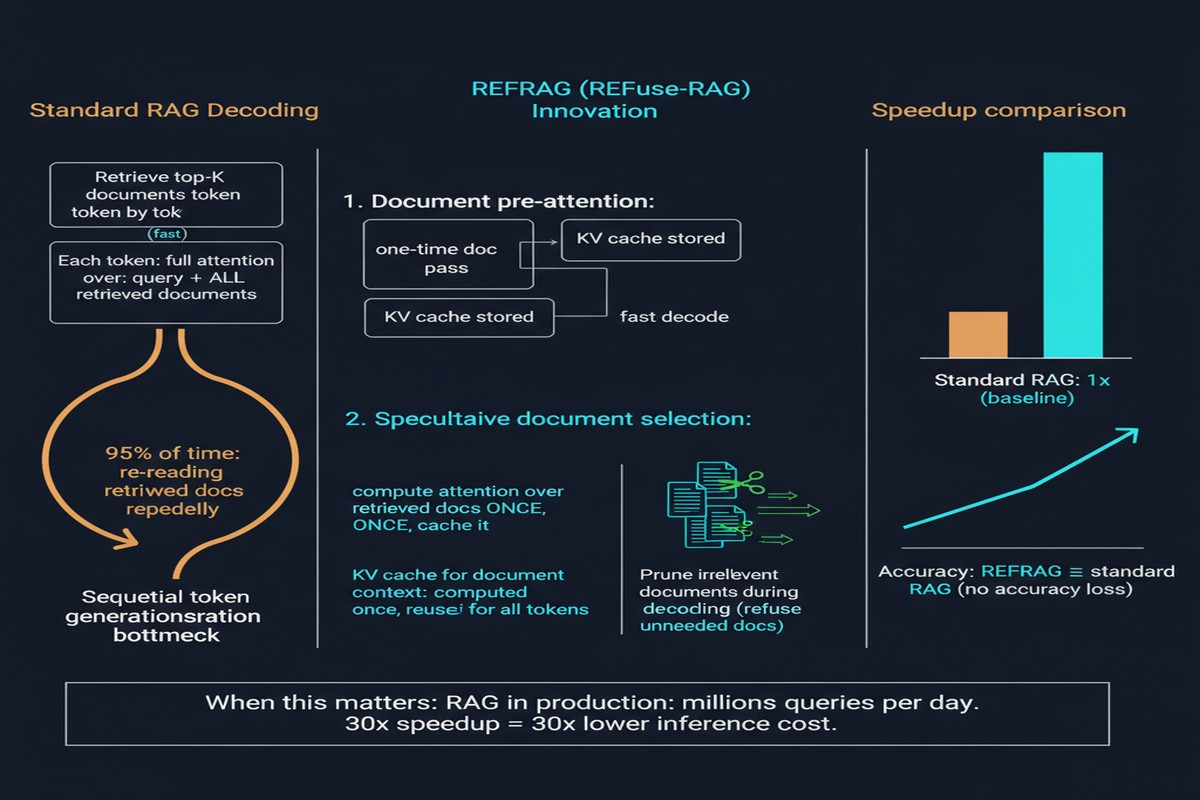
The paper starts with a clean observation: in RAG, the model's attention patterns are sparse. Most retrieved tokens receive negligible attention because most retrieved content is tangentially related, not directly relevant, to the specific generation step.
This is obvious if you think about it. When a model generates a specific sentence in a RAG answer, it attends heavily to the query, to a small subset of relevant retrieved passages, and to what it's already generated. The other 80-90% of the retrieved context — the passages that happened to be topically similar but don't bear on this particular generation step — receive almost zero attention.
But the model doesn't know this in advance. It has to process all the retrieved tokens and compute attention over all of them before it can determine which ones are relevant. Full attention over the entire context is the price you pay for not knowing which parts of the context matter.
REFRAG breaks this cycle with three techniques:
flowchart TD
RC[Retrieved Context\n5,000 tokens] --> C[Compress\nKV Cache Compression\nReduce irrelevant tokens]
C --> S[Sense\nAttention Pattern Analysis\nIdentify relevant regions]
S --> E[Expand\nSelective KV Expansion\nRecover needed context]
E --> G[Decode\nGenerate with minimal\nbut sufficient context]
style C fill:#4a90d9,color:#fff
style S fill:#7b68ee,color:#fff
style E fill:#50c878,color:#fff
Compress: Before decoding begins, REFRAG applies KV cache compression to the retrieved passages. This is not naive truncation — it uses learned compression that preserves the high-attention regions of each passage while aggressively compressing low-attention regions. The result is a compressed KV cache that's a fraction of the original size.
Sense: During early decoding, REFRAG monitors the model's attention patterns to identify which compressed passages are actually being used heavily. This is the "sensing" step — the system learns what it doesn't know.
Expand: For passages identified as highly relevant, REFRAG expands the KV cache back to full resolution by loading the un-compressed version. Passages that remain low-attention stay compressed.
The net effect: the model pays full attention cost only for the small fraction of retrieved context that's actually relevant.
The Numbers
The paper's benchmark results are striking:
Time-to-First-Token: ~30.85x acceleration compared to standard RAG. For reference, prior best approaches achieved ~8x. REFRAG is 3.75x better than the previous state-of-the-art.
Context Extension: RAG systems effectively handle 16x more retrieved context without accuracy loss. A system that previously handled 4K tokens of retrieval context can now handle 64K. This is the difference between retrieving 8 passages and retrieving 128 passages.
Accuracy: No accuracy degradation on standard RAG benchmarks (NaturalQuestions, TriviaQA, PopQA). The compressed/expanded approach preserves the information that matters.
The TTFT improvement is particularly meaningful for interactive applications. If your RAG system takes 3 seconds to produce its first token, users experience it as slow. If REFRAG cuts that to 0.1 seconds while maintaining accuracy, the user experience difference is transformative.
Why This Matters for Production RAG
Most discussions about RAG efficiency focus on retrieval — faster vector search, smaller indexes, approximate nearest neighbor algorithms. REFRAG focuses on the generation side, which is often where the actual latency lives.
Consider a typical RAG pipeline latency breakdown:
graph LR
subgraph Standard RAG Latency
Q[Query] --> VS[Vector Search\n~50ms]
VS --> CTX[Context Assembly\n~20ms]
CTX --> PREF[Prefill\n~400ms for 5K tokens]
PREF --> GEN[Generation\n~200ms]
end
subgraph REFRAG Latency
Q2[Query] --> VS2[Vector Search\n~50ms]
VS2 --> CTX2[Context Assembly\n~20ms]
CTX2 --> PREF2[Compressed Prefill\n~15ms for compressed context]
PREF2 --> SENS[Sense + Expand\n~25ms]
SENS --> GEN2[Generation\n~200ms]
end
The prefill step — processing the retrieved context before generation begins — is where REFRAG intervenes. For large retrieval contexts, prefill dominates total latency. REFRAG attacks the dominant cost.
The context extension capability is the other major enabler. Today's RAG systems are constrained by practical context limits — you can't retrieve 100 passages because the context would be too long and expensive to process. REFRAG changes this constraint. You can retrieve more broadly (higher recall) and compress down to what's needed.
What's Being Left on the Table
I want to flag a few things the paper doesn't fully address.
Compression quality variance: The paper evaluates on standard open-domain QA benchmarks. These are relatively clean, factoid-style questions where the relevant passage is usually very clear. In settings where relevance is more distributed — analytical questions that draw on multiple passages, documents with subtle cross-references — the compression heuristics may struggle to identify which regions to preserve.
KV cache architecture dependence: REFRAG's approach is tied to transformer KV cache structure. As the field moves toward hybrid architectures (Mamba, state-space models, sliding window attention), the specific compression-sensing-expansion pipeline will need rethinking.
Retrieval-compression interaction: REFRAG treats retrieval as fixed and optimizes the decoding stage. But there's an opportunity for co-optimization: if you know you're going to compress the retrieved context anyway, you can retrieve differently — perhaps retrieving more broadly and trusting compression to focus, rather than trying to retrieve precisely.
My Take
REFRAG is pure systems engineering applied to the right problem. The latency and cost of processing long retrieved contexts is a genuine blocker for RAG deployment at scale, and the paper addresses it directly with techniques that are immediately applicable.
The 30x TTFT improvement is the headline, but I find the context extension capability more interesting strategically. Right now, RAG teams make painful tradeoffs about how much to retrieve. More retrieval = higher recall but higher cost and latency. REFRAG breaks this tradeoff open — you can retrieve more and pay less.
This is the kind of infrastructure paper that doesn't get the recognition it deserves because it's not proposing a new model architecture or a new training paradigm. It's making an existing paradigm dramatically more efficient. But in production, efficiency is the difference between a RAG system that runs and one that scales.
If your RAG system serves user-facing applications with latency requirements, REFRAG belongs on your reading list. The implementation details are in the paper and the approach is architecture-agnostic enough to apply to most transformer-based deployments.
arXiv: 2509.01092



