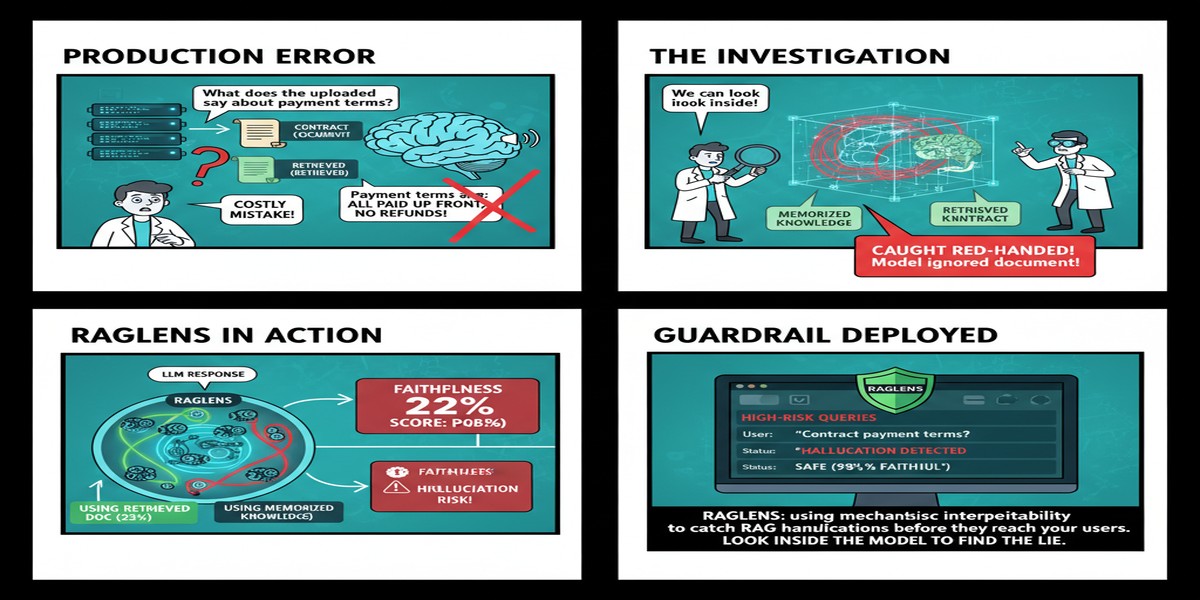
Here's the dirty secret about RAG systems in production: you don't know when they're lying.
You feed in retrieved context. The model generates an answer. The answer sounds confident. But is it faithful to the context? Did the model actually use the retrieved passages, or did it just riff off its parametric knowledge and use the context as decoration? Most evaluation approaches — ask another LLM, compute NLI scores, check citation spans — are expensive, slow, or unreliable.
RAGLens, published December 2025 and accepted at ICLR 2026, takes a completely different approach. Guangzhi Xiong and colleagues at UVA don't evaluate the output. They watch the model think.
The Core Idea: Mechanistic Hallucination Detection
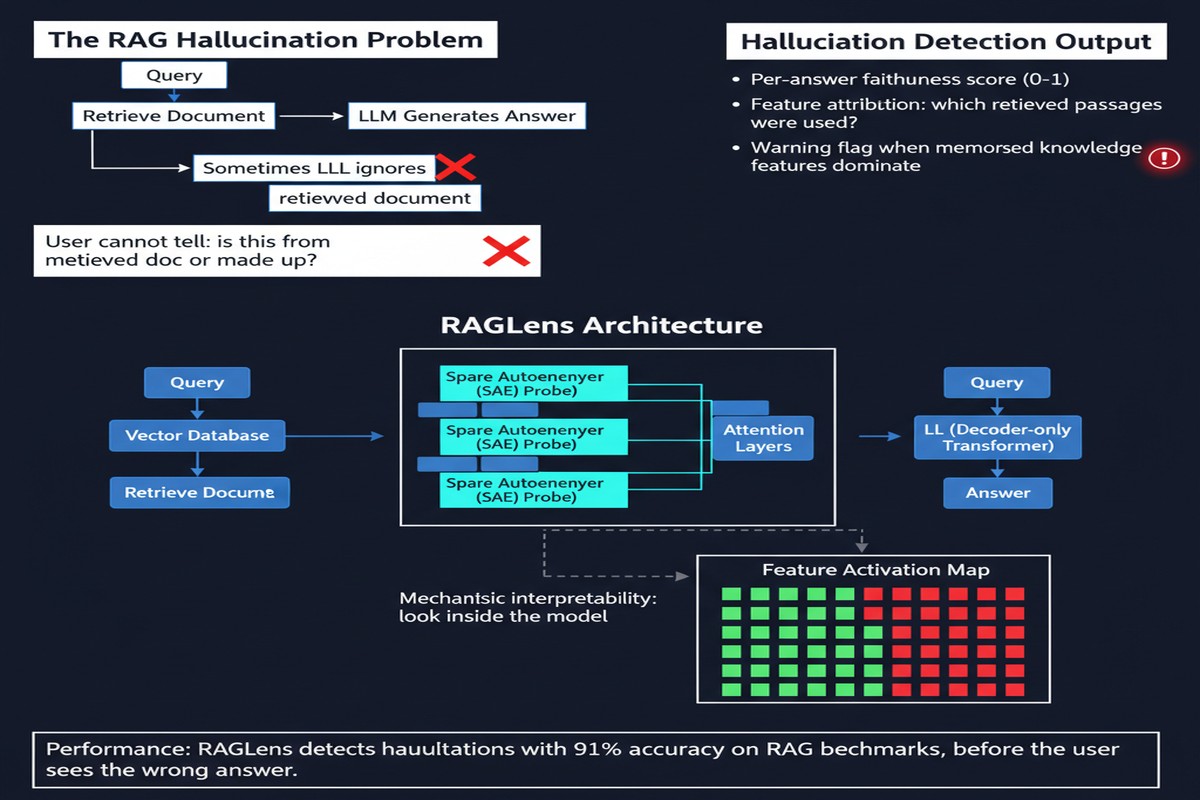
Sparse autoencoders (SAEs) have emerged as a powerful tool in mechanistic interpretability over the last two years. The idea is to decompose the superimposed features in a transformer's residual stream into interpretable, monosemantic components. Each SAE latent captures a specific "concept" the model is tracking internally.
RAGLens asks: when a model hallucinates in a RAG context — when it ignores the retrieved evidence and generates something inconsistent with it — does that leave a distinctive fingerprint in the activations? The answer, compellingly, is yes.
flowchart LR
C[Retrieved Context] --> M[Language Model]
Q[Query] --> M
M -->|Internal Activations| SAE[Sparse Autoencoder]
SAE -->|Disentangled Features| FE[Feature Extractor]
FE -->|Hallucination Features Active?| D{RAGLens Detector}
D -->|Faithful| OUT1[✓ Pass]
D -->|Unfaithful| OUT2[⚠ Flag]
M -->|Generated Answer| ANS[Answer]
The training process works like this:
- Collect a dataset of (context, query, generation) triples with faithfulness labels.
- Train an SAE on the model's internal activations at generation time.
- Identify which SAE features are predictive of unfaithfulness — these are the "hallucination features."
- Build a lightweight linear classifier on top of these features.
At inference time, RAGLens monitors the model's activations as it generates. When the hallucination features activate, it flags the output.
Why Sparse Autoencoders and Not Something Simpler?
This is a fair question. Why not just train a probe directly on the raw activations? Or use the model's own log probabilities as a faithfulness signal?
The paper addresses this directly. Raw activation probes work but lack interpretability — you can't explain why a generation was flagged as unfaithful. Log probability methods fail in a subtle way: a model can be highly confident while being unfaithful if its parametric knowledge strongly contradicts the retrieved context.
SAE features give you both signal and interpretation. The paper includes a fascinating analysis of which features fire during hallucination: features associated with "contradiction," "inconsistency," and "ignoring context" become more active. This interpretability is what separates RAGLens from a black-box classifier.
The authors also make a practical choice I appreciate: they use an existing SAE trained on the base model (they don't train a new one from scratch for each deployment). This makes RAGLens genuinely deployment-friendly.
Performance That Matters
The paper benchmarks RAGLens against several strong baselines:
- LLM-as-a-judge (GPT-4 evaluating faithfulness)
- NLI-based detectors
- Activation-based linear probes
RAGLens matches or outperforms all of them on standard faithfulness benchmarks, while being dramatically cheaper at inference. An LLM judge costs roughly 1,000x more per sample. NLI models are cheap but brittle. RAGLens is fast, cheap, and accurate.
The interpretability results are the hidden gem. The paper shows that the features flagged by RAGLens are semantically coherent — researchers can actually read what the model is tracking when it hallucinates. This is rare in applied ML papers. Most interpretability work stays in the lab; this one ships to production.
Why This Matters
The RAG hallucination problem is massively underappreciated in production systems. I've talked to teams running RAG in enterprise settings who are checking faithfulness by... manually sampling 10 responses per week. That's not a reliability strategy, that's wishful thinking.
RAGLens changes the economics. If you can run lightweight activation-based faithfulness detection at every inference step, you can:
- Flag low-confidence responses for human review before they reach users
- Build reinforcement learning reward signals based on real-time faithfulness
- Create audit trails for compliance-sensitive applications
- Improve retrieval by identifying which passages are being ignored
graph TD
subgraph Production RAG System
R[Retriever] --> C[Context Assembly]
C --> G[Generator]
G --> RAGLens
RAGLens --> |Faithful| Resp[Deliver Response]
RAGLens --> |Unfaithful| Review[Human Review Queue]
RAGLens --> |Pattern Analysis| RI[Retrieval Improvement]
end
The last point deserves emphasis: if you know your model is consistently ignoring certain types of retrieved context, that's signal you can act on. Maybe your chunking strategy is wrong. Maybe your retriever is surfacing passages that are semantically similar but factually irrelevant. RAGLens helps you debug your retrieval pipeline, not just monitor your generation pipeline.
My Take
I think RAGLens is one of the most practically important RAG papers of late 2025. Not because it's the most theoretically innovative — SAEs and mechanistic interpretability are established tools. But because it makes the right engineering choice: take a powerful interpretability technique and apply it to a real deployment problem that teams are currently solving badly.
My one criticism: the paper focuses on faithful RAG but doesn't address the opposite failure mode — over-faithfulness, where the model cites the retrieved context even when that context is itself wrong. If your retriever pulls a hallucinated Wikipedia passage, a faithful model will confidently propagate the error. RAGLens won't catch that because the generation is faithful to the retrieved context.
This is the fundamental limitation of any context-grounded faithfulness approach: you can only be as good as your retrieved context. RAGLens assumes your retriever is trustworthy. In many production deployments, that's a bad assumption.
But for the problem it does solve — detecting when models ignore or contradict good retrieved context — RAGLens is the best tool I've seen. The ICLR acceptance is well-deserved.
Build this into your RAG monitoring stack. You'll find out things about your system that will surprise you.
arXiv: 2512.08892