
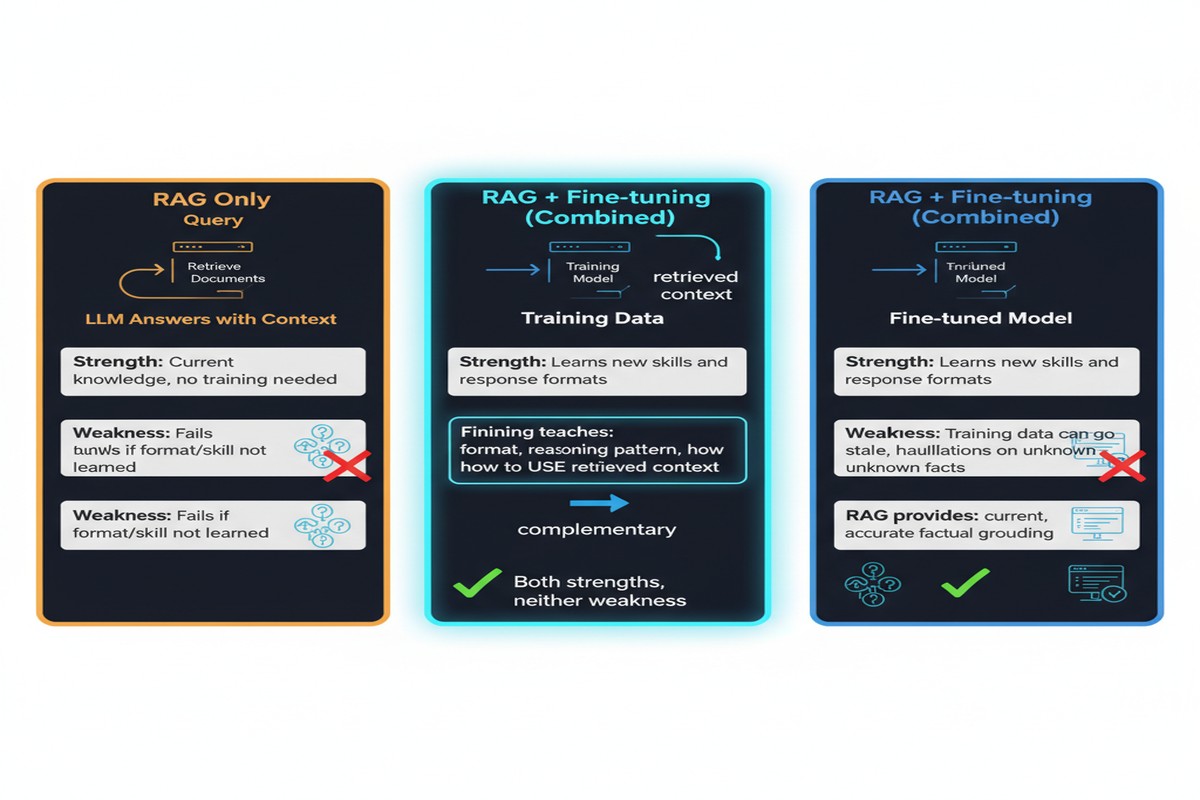
There's a tension at the heart of RAG that nobody likes to talk about: if your model was good enough to use retrieved context effectively, it might not need to retrieve in the first place. And if it's not good enough to use retrieved context, retrieval just adds noise.
Humaid Ibrahim, Nikolai Rozanov, and Marek Rei at Imperial College London published a paper in October 2025 — accepted at ICLR 2026 — that cuts through this tension with a simple but powerful insight: use RAG to train better models, not just to compensate for worse ones.
The Core Problem
Multi-step agent tasks are where RAG systems fail most visibly. The agent needs to perform a sequence of actions — navigate an environment, execute tool calls, reason about state — and at any point, it might lack the knowledge or skill to proceed correctly.
The standard solution is to give the agent a retrieval mechanism: when it doesn't know what to do, it looks it up. But this has compounding failure modes:
- The agent might not know what to look up
- The retrieved context might not help with the type of reasoning needed
- Retrieval adds latency and context length at every step
- The model might ignore retrieved context and proceed confidently with wrong behavior
The paper's diagnosis is sharp: the agent fails because it lacks a skill, not just information. And you can't teach skills by handing information to a model at inference time. You have to train on them.
The Approach: Failure → Hint → Trajectory → Model
The paper's pipeline is elegant:
flowchart TD
A[Agent Attempts Task] --> B{Succeeds?}
B -->|Yes| C[Collect Successful Trajectory]
B -->|No| D[Extract Failure Pattern]
D --> E[Generate Compact Hint\nvia One-Shot RAG]
E --> F[Generate Improved Teacher Trajectory\nusing Hint + RAG]
F --> G[Remove Hint from Trajectory]
G --> H[Fine-tune Student Model\non Hint-Free Trajectories]
H --> I[Deployed Model:\nNo RAG at Inference]
C --> H
Step 1 — Collect failures: Run the agent on a set of tasks. Record where it fails and how it fails.
Step 2 — Extract hints via RAG: For each failure, use one-shot retrieval to find a compact, reusable hint that would have helped the agent succeed. The hint is not a full retrieved document — it's a distilled piece of task knowledge.
Step 3 — Generate improved teacher trajectories: With the hint available, generate a corrected trajectory showing how the agent should have behaved.
Step 4 — Train without hints: Strip the hints from the trajectories. Fine-tune the student model on the hint-free improved trajectories. The model must internalize the skill from the trajectory pattern alone.
The result: a model that has learned from its failures without needing to retrieve at inference time.
The Numbers
The results are genuinely impressive. On ALFWorld (a household task completion benchmark):
- Baseline agent: 79% success rate
- RAG-augmented baseline: modest improvements
- Fine-tuned model (no inference-time RAG): 91% success rate
On WebShop (product search and purchasing agent):
- Baseline: 61 score
- Fine-tuned model: 72 score
And critically: inference token usage drops substantially. The fine-tuned model doesn't need to retrieve context at every step, so average sequence length decreases. You get better performance and lower cost.
The paper also shows that the approach transfers across model sizes — smaller models benefit from fine-tuning on improved trajectories generated by larger models. This is a form of knowledge distillation specifically for agentic competence.
Why This Is More Important Than It Sounds
Most of the RAG field is focused on inference-time retrieval. How do we retrieve better? How do we rank better? How do we compress the retrieved context? This is all important work.
But the implicit assumption is that the model is fixed and retrieval is the variable we optimize. This paper questions that assumption. If you can change the model, you can eliminate the need for retrieval on the skills you've trained.
This has profound implications for agentic deployment:
graph LR
subgraph Traditional Agentic RAG
T1[Agent] -->|Stuck?| T2[Retrieve Context]
T2 --> T3[Try Again with Context]
T3 -->|Still Stuck?| T2
end
subgraph Fine-tuned Agent
F1[Fine-tuned Agent] -->|Apply Internalized Skills| F2[Succeed Directly]
end
subgraph Cost Comparison
C1[RAG at every step\nHigh latency, Long context]
C2[No retrieval\nLow latency, Short context]
end
For production systems with latency SLAs, the ability to eliminate retrieval hops from the critical path is genuinely valuable. A customer service agent that can handle 80% of queries from internalized skills and only invoke retrieval for truly novel situations is dramatically better than an agent that retrieves for every step.
The Limits
I have to be honest about what this approach doesn't solve.
Domain drift: The fine-tuned skills reflect the task distribution at training time. When the task environment changes — new product catalog, updated policies, different action space — the fine-tuned skills may be stale. RAG-augmented agents adapt automatically; fine-tuned ones don't.
Coverage: The approach teaches the model the skills it needs for observed failure patterns. Novel failure modes that weren't in the training set won't be covered. RAG can at least attempt to retrieve relevant context for novel situations; a fine-tuned model without RAG has no fallback.
Training cost: Fine-tuning is not free. For rapidly evolving domains (news, financial markets, live product catalogs), the cost of retraining whenever the domain changes may outweigh the inference-time savings.
The honest answer is that this approach is most valuable in stable-domain, high-volume agent deployments where the task distribution is known and the inference-time cost of retrieval is a real bottleneck. For knowledge-intensive tasks with rapidly changing ground truth, you still need inference-time RAG.
My Take
This paper represents a genuinely useful reframing of the RAG problem. Most of the field treats models as fixed and optimizes the retrieval layer. This paper treats retrieval as a teacher and optimizes the model. Both approaches are valid; the right choice depends on deployment constraints.
What I find most compelling is the failure-driven approach to hint extraction. It's the right inductive bias: you don't know in advance what skills a model lacks, but you can observe where it fails and systematically close those gaps. This is how good engineers debug systems — not by theorizing about what might go wrong, but by watching what actually goes wrong and fixing it.
The distillation step — removing hints from trajectories and training on hint-free versions — is clever. It forces the model to internalize the skill rather than just learn to condition on hints. This is the difference between learning to read a map and learning to navigate.
Fine-tuning with RAG isn't a replacement for inference-time RAG. It's a complementary technique for teams who have stable task distributions, care deeply about inference cost, and are willing to invest in continuous training pipelines. For those teams, this paper is required reading.
arXiv: 2510.01375



