
Federated Learning for LLMs: Training Without Seeing the Data
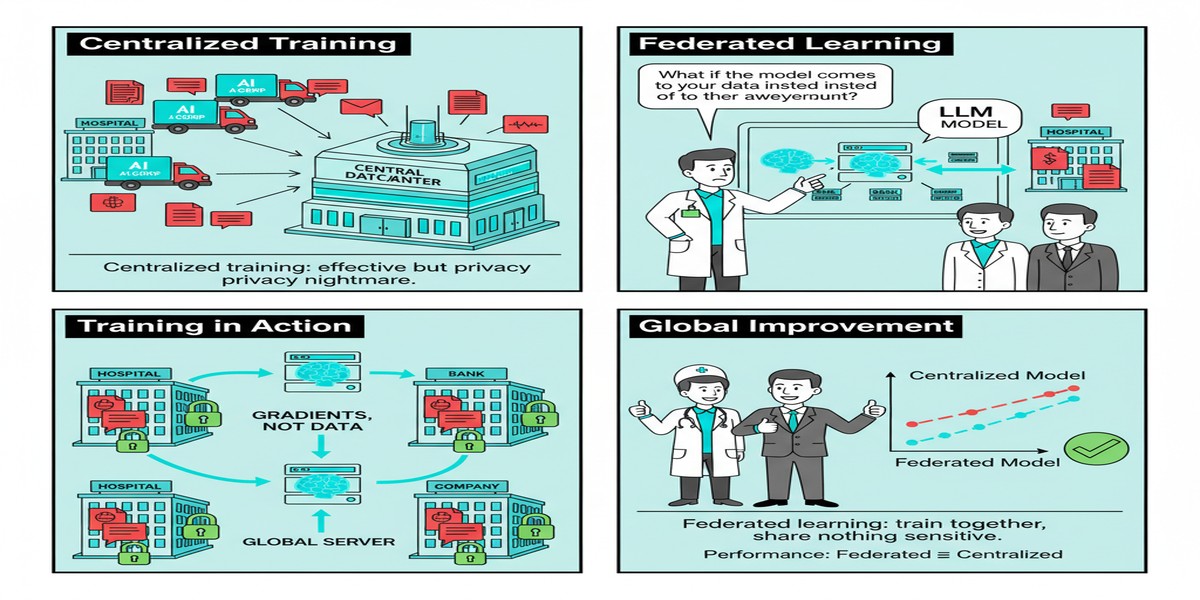
Every enterprise that wants to fine-tune an LLM on proprietary data faces the same dilemma: the data is the competitive advantage, and sending it to a cloud API is a risk they may not be willing to take. Patient health records, legal case files, financial transaction data, customer communication histories — this data is valuable precisely because it can't be shared freely.
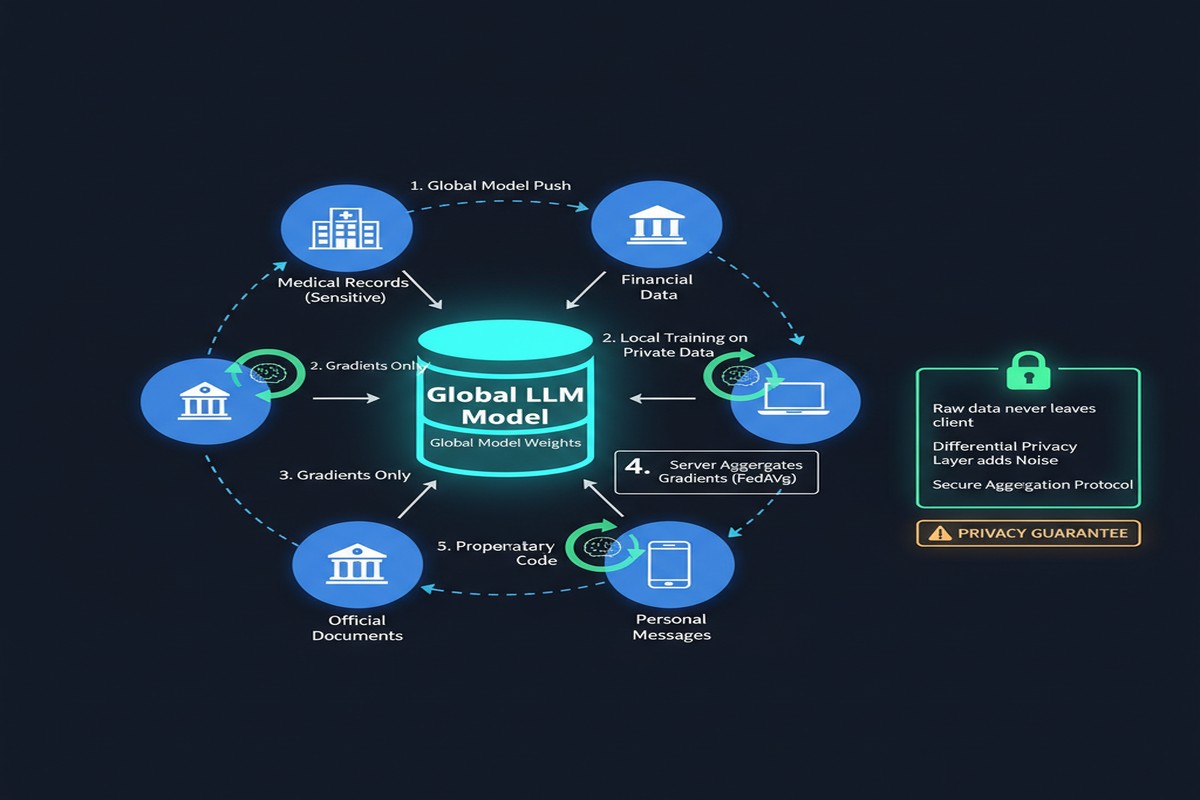
Federated learning promises a solution: train the model across distributed data sources without centralizing the raw data. Each participant trains locally on their own data, shares only model updates (gradients or weights), and a central aggregator combines these updates into an improved global model — without ever seeing any participant's actual data.
"Federated Learning: A Survey on Privacy-Preserving Collaborative Intelligence" (arXiv: 2504.17703, Apr 2025) is the comprehensive 2025 reference for understanding the state of federated learning, with specific attention to LLM applications. Here's what practitioners actually need to know.
The Core Architecture
sequenceDiagram
participant C1 as Client 1\n(Hospital A)
participant C2 as Client 2\n(Hospital B)
participant C3 as Client 3\n(Hospital C)
participant S as Federated Server
S->>C1: Distribute global model
S->>C2: Distribute global model
S->>C3: Distribute global model
C1->>C1: Train on local data\n(patient records never leave)
C2->>C2: Train on local data
C3->>C3: Train on local data
C1->>S: Send gradient update\n(not raw data)
C2->>S: Send gradient update
C3->>S: Send gradient update
S->>S: Aggregate updates\n(FedAvg or variants)
S->>C1: Updated global model
S->>C2: Updated global model
S->>C3: Updated global model
This sounds elegant. The reality is messier.
What Actually Works for LLMs
The survey identifies a critical tension: LLMs are large, and federated learning is communication-intensive.
Standard LLMs have billions of parameters. Communicating full gradient updates for each parameter in each round would require transmitting gigabytes of data per client per round — defeating the practical purpose of federated learning for most enterprise settings.
The solutions that work:
Parameter-Efficient Federated Fine-Tuning
Rather than fine-tuning all parameters, only fine-tune a small adapter module (LoRA, prefix tuning) and share only those adapter weights. A LoRA adapter for a 7B LLM might have ~10M parameters — 700x fewer than the full model. Communication overhead becomes manageable.
graph LR
A[Pre-trained LLM\n7B params\nFrozen] --> B[LoRA Adapter\n~10M params\nFederated]
B --> C[Task-specific output]
D[Federated aggregation\n10M params shared\nnot 7B] --> B
style A fill:#6b7280,color:#fff
style B fill:#2563eb,color:#fff
style D fill:#059669,color:#fff
PriFFT (arXiv: 2503.03146, Mar 2025) extends this further with privacy guarantees: privacy-preserving federated fine-tuning using function secret sharing. Clients and servers share model inputs and parameters through cryptographic secret sharing, performing secure fine-tuning without any party accessing plaintext data or gradients. The accuracy penalty is approximately 1.33% for ε=10 differential privacy guarantee — acceptable for many applications.
Gradient Compression
Even compressed adapter gradients can be reduced further through quantization (8-bit, 4-bit) and sparsification (share only the top-K% largest gradient components). Modern gradient compression achieves 10-100x compression with minimal accuracy loss.
Asynchronous Federated Learning
Standard federated learning requires all clients to complete their local training before aggregation — a major bottleneck when clients have heterogeneous compute and data sizes. Asynchronous approaches allow the server to aggregate updates as they arrive, substantially improving throughput at the cost of some coordination complexity.
The Privacy Guarantees: What Federated Learning Actually Provides
Here's the uncomfortable truth that marketing materials about federated learning often omit: basic federated learning does not guarantee privacy.
Sharing gradient updates can leak information about the training data. Gradient inversion attacks can recover training samples from gradients in some settings. This is why production federated learning systems combine federated training with additional privacy mechanisms:
Differential Privacy (DP): Add calibrated Gaussian noise to gradient updates before sharing. This provides a formal mathematical guarantee (ε-differential privacy) that individual data points cannot be inferred from the gradients. Cost: accuracy degrades with privacy level.
Secure Aggregation: Use cryptographic protocols so the server only sees the aggregate of all client updates, not individual client contributions. This prevents any single malicious server from inferring individual participant data. Cost: significant communication and compute overhead.
Trusted Execution Environments (TEEs): Run the aggregation inside Intel SGX or AMD SEV enclaves that hardware-guarantee the server can't inspect the computation. Cost: hardware requirements and performance overhead.
graph TD
A[Federated Learning\nBasic] --> B[Gradient Sharing\nNo Privacy Guarantee]
A --> C[+ Differential Privacy] --> D[Formal ε-DP Guarantee\nSome accuracy loss]
A --> E[+ Secure Aggregation] --> F[Server can't see\nindividual updates]
A --> G[+ TEE Computation] --> H[Hardware-guaranteed\nprivacy boundary]
D --> I[Production-grade\nPrivacy-preserving FL]
F --> I
H --> I
style I fill:#059669,color:#fff
style B fill:#ef4444,color:#fff
The Heterogeneity Challenge
Real-world federated learning involves heterogeneous clients:
- Different dataset sizes (hospital with 1,000 patients vs. one with 100,000)
- Different data distributions (regional patient demographics vary)
- Different compute capabilities (on-premises GPU servers vs. CPU-only environments)
- Different network connectivity (high-bandwidth institutional networks vs. mobile connections)
The survey documents that standard FedAvg (Federated Averaging) performs poorly under high heterogeneity. Better approaches include:
- FedProx: Adds a proximal term to client objectives to prevent large deviations from the global model
- SCAFFOLD: Uses control variates to correct for client drift
- Personalized FL: Allows clients to maintain some local model components rather than fully adopting the global model
For LLMs specifically, the data heterogeneity problem is severe: a healthcare system's language patterns, terminology, and task distribution differ drastically from a legal firm's. Simple averaging of their fine-tuned adapters may perform worse than either model alone.
Regulatory Tailwinds: Why This Matters Now
The timing of this survey is not coincidental. Several regulatory pressures are making federated learning more relevant:
GDPR and its successors: The EU's data governance framework restricts cross-border data transfer for personal data. Federated learning enables collaborative model training without violating data localization requirements.
Healthcare data: HIPAA (US), GDPR-Health (EU), and emerging national healthcare data laws restrict patient data sharing. Federated learning enables healthcare AI without centralized patient data.
Financial data: Banking regulators increasingly require data governance controls that make centralizing customer transaction data for AI training legally complex.
India's DPDP Act: The Digital Personal Data Protection Act creates new compliance requirements for AI systems trained on Indian user data — federated approaches can help navigate these.
Why This Matters for Enterprise AI
For most large enterprises, the question isn't "should we use federated learning" — it's "can we build an AI system that our legal and compliance teams will approve."
Centralized fine-tuning of LLMs requires either sending data to a cloud API (legal red flag) or centralizing data in a single location (data governance challenge). Federated learning offers a path that keeps data in place while still enabling model improvement.
The practical threshold: federated learning for LLMs makes sense when:
- Data is genuinely sensitive and regulated
- Multiple organizations have complementary data but can't share it
- On-premises compute is available at participant sites
- The accuracy trade-off of DP is acceptable for the use case
My Take
Federated learning for LLMs is moving from a theoretical curiosity to a practical enterprise necessity. The GDPR-era pressure on data governance has created genuine demand for privacy-preserving training that federated learning can meet.
The PriFFT paper's result — only 1.33% accuracy loss for ε=10 DP with federated LoRA fine-tuning — is important. That's an acceptable trade-off for many regulated applications where the alternative is either no AI or unacceptable data exposure risk.
My honest assessment of the current state: federated learning for LLMs is deployable for fine-tuning adapters on task-specific data in regulated enterprise settings. It is not yet deployable for pretraining large models from scratch in federated settings — the communication overhead and convergence challenges are too severe at that scale.
The next 2 years will see productization of federated LLM fine-tuning as a service — cloud providers packaging the infrastructure so enterprises don't have to build it themselves. That's when adoption accelerates.
Data sovereignty is the next AI infrastructure battle. Federated learning is a key weapon.
Paper: "Federated Learning: A Survey on Privacy-Preserving Collaborative Intelligence", arXiv: 2504.17703, Apr 2025. Also: "PriFFT: Privacy-preserving Federated Fine-tuning of Large Language Models via Function Secret Sharing", arXiv: 2503.03146, Mar 2025.
Explore more from Dr. Jyothi


