
The Open-Source LLM Advantage: How Democratized AI Is Reshaping the Competitive Landscape
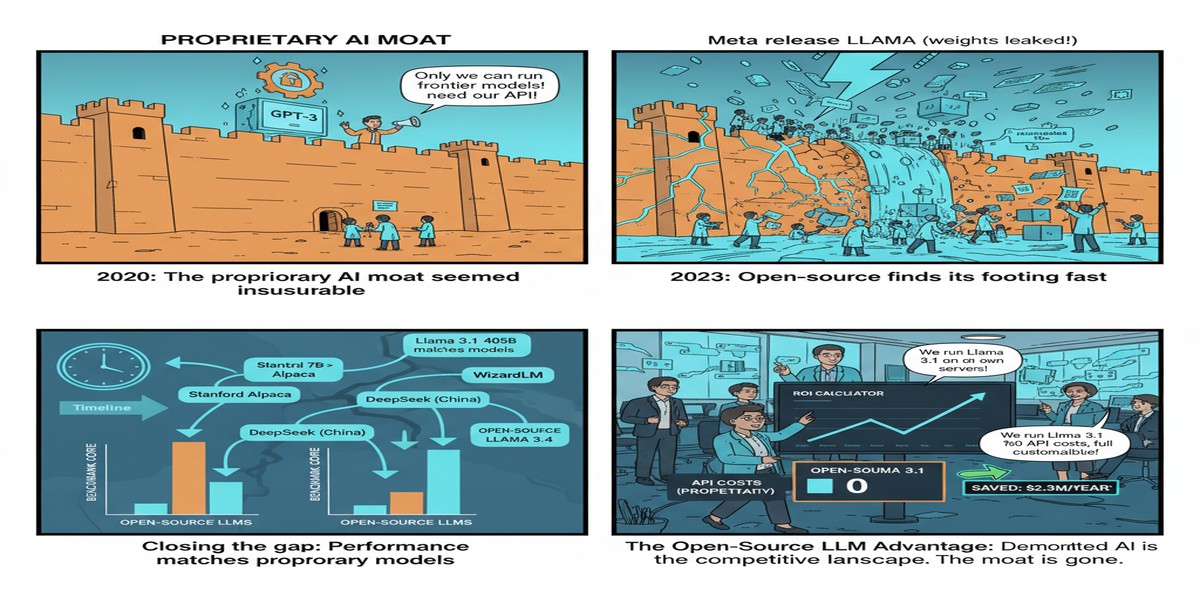
In early 2023, the LLM landscape was simple: closed models (GPT-4, Claude, Gemini) were far ahead, and open-source models were useful for research but not serious production tools. The gap seemed insurmountable — the compute required to train frontier models was available only to a handful of organizations.
Two years later, the picture has transformed. "The Open-Source Advantage in Large Language Models" (arXiv: 2412.12004, Dec 2024) documents this transformation — but the story has continued evolving rapidly through 2025. The ecosystem has shifted so quickly that reading the paper alongside 2025 developments tells a fascinating story about what open source is doing to the AI industry's competitive dynamics.
The State of the Ecosystem in Early 2026
Let me start with where we are now, then trace how we got here.
The 2025-2026 open-weight LLM landscape includes models competitive with GPT-4-level performance from:
- Meta: LLaMA 4 (though it fell from grace rapidly in the community)
- Alibaba/Qwen: Qwen3 series, which overtook LLaMA in download rankings and derivative models
- DeepSeek: DeepSeek-V3 and DeepSeek-R1 — Chinese models that shocked the Western AI community with their efficiency
- Mistral AI: Mistral Large 3, fully open under Apache 2.0 with 256K context
- Others: Kimi, GLM, MiniMax, Yi — multiple contenders from Chinese AI labs
The Hugging Face ecosystem has become the coordination layer: the Hugging Face Transformers library is the de facto standard for LLM implementations, and model pages on the Hub document capabilities, licenses, and community usage.
graph TD
subgraph Frontier Open-Weight Models Early 2026
A[DeepSeek-V3/R1\nMost efficient training\nShocked Western AI community]
B[Qwen3\nOvertook Llama in popularity\nStrong multilingual]
C[Mistral Large 3\nApache 2.0 license\n256K context]
D[LLaMA 4\nMeta's offering\nLost community favor quickly]
E[Emerging: Kimi, GLM\nGlobal competition]
end
F[Hugging Face Hub\nDistribution + Community Layer] --> A
F --> B
F --> C
F --> D
F --> E
Why Open Source Has Caught Up: The Technical Drivers
The paper's core analysis identifies several mechanisms that enabled open-source models to close the gap with closed models:
Instruction Tuning and Alignment Techniques
Early LLaMA models were base models — powerful, but not aligned for instruction following. The open-source community learned to apply RLHF, DPO, and instruction tuning using community-curated datasets. By 2024, instruction-tuned open models matched or exceeded commercial models on many benchmarks.
The technique democratized further: with LoRA (Low-Rank Adaptation), fine-tuning 7B or 13B models on consumer hardware became feasible. Thousands of community fine-tunes exist for coding, medical, legal, and domain-specific applications.
Knowledge Distillation from Frontier Models
A controversial but powerful technique: generate synthetic training data from GPT-4 or other frontier models, then train smaller open models on this data. DeepSeek's models benefited substantially from distillation approaches. The quality of the teacher directly raises the ceiling for the student.
This creates an interesting dynamic: closed model providers inadvertently improve open-source models by providing better training signal. The more you use GPT-4 to generate data, the better the open-source alternatives that train on that data become.
The Efficiency Revolution: DeepSeek's Impact
DeepSeek-V3's training efficiency shocked the AI community in late 2024. Reported training cost: approximately $6 million. For comparison, frontier model training runs from US labs have been estimated at $50-100 million+.
The efficiency gains came from:
- MoE architecture: Sparse activation dramatically reduces compute per token
- Multi-head latent attention: Efficient attention mechanism reducing KV cache requirements
- FP8 training: Mixed-precision training with 8-bit floats, reducing memory and compute
- Pipeline optimization: Careful overlap of compute and communication in distributed training
If accurate, DeepSeek's training efficiency represents a fundamental challenge to the "only large organizations can train frontier models" narrative. It suggests that algorithmic efficiency improvements, not just raw compute, can close the capability gap.
What Open Source Actually Enables (That Closed Models Can't)
The paper makes an important distinction: "open source" and "open weight" are different, and both provide different advantages over fully closed APIs.
Fully closed API (GPT-4o, Claude): You see inputs and outputs, nothing else.
Open-weight model (LLaMA, Qwen, DeepSeek): Weights are public; you can run inference locally, fine-tune for your domain, modify for your use case.
Fully open source (Pythia, Mistral under Apache 2.0): Training code, data (where available), and weights — full reproducibility.
The advantages of open approaches:
Reproducibility: You can verify performance claims by running the model yourself. Closed model benchmark numbers require trusting the lab's evaluation methodology.
Customization: Fine-tuning on domain-specific data. Healthcare organizations can fine-tune on patient records locally. Legal firms can fine-tune on case law. Neither requires sending proprietary data to an API.
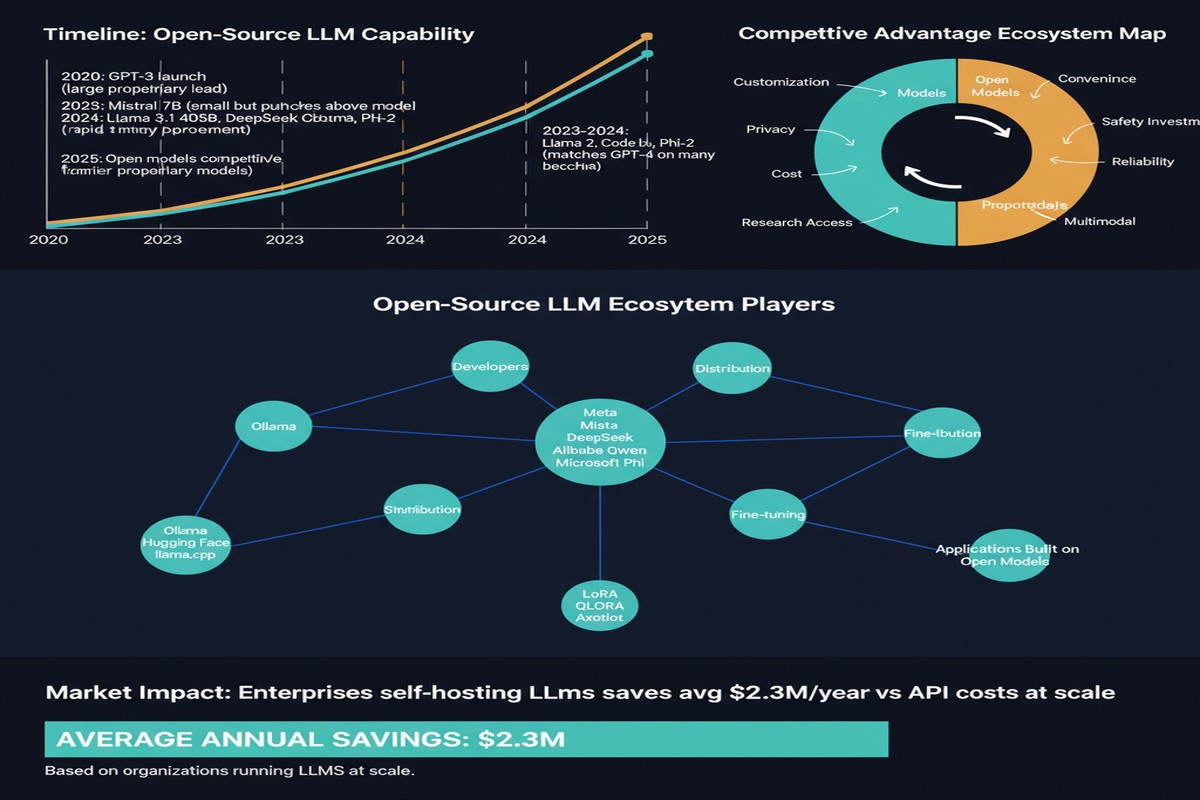
Cost control: Running local inference eliminates per-token API costs. For high-volume applications, this is economically transformative.
Sovereignty: No dependency on a vendor's API availability, pricing, or terms of service changes. Organizations with regulatory requirements for data sovereignty can self-host.
Research: The academic community can study open models in ways closed models don't permit. Understanding of attention mechanisms, emergent capabilities, and alignment properties all require model weights.
The License War: Open-Weight Isn't Always Open
One of the paper's most important observations: the definition of "open source" in the LLM context is contested.
Most "open-source" LLMs use custom licenses that restrict commercial use, use for competing AI services, or application to certain use cases. Llama's license prohibits use in competing AI services. Many models restrict training new models on their outputs.
Truly permissive open-source AI (Apache 2.0, MIT) is rarer:
- Mistral Large 3 (Apache 2.0) — notable exception
- Older Mistral models (7B, 8x7B)
- Some smaller research models
This matters for enterprise adoption: an organization building commercial AI products needs to understand that a "free" LLaMA model may have license restrictions that make commercial deployment legally complex.
The Competitive Pressure on Closed Labs
The open-source ecosystem creates competitive pressure that benefits everyone:
When Llama 2 was released in July 2023, OpenAI had to justify why GPT-4 was worth paying for. When DeepSeek matched GPT-4-level performance at a fraction of the training cost, every AI lab had to reevaluate their compute cost assumptions. When Qwen3 demonstrated strong multilingual performance, it created pressure on closed models in Asian markets.
The existence of capable open-source alternatives forces closed labs to:
- Continuously improve quality (can't rest on API lock-in)
- Provide genuine value-add services (fine-tuning, tooling, safety, reliability) rather than just model access
- Price reasonably (overpricing loses customers to self-hosted alternatives)
This is healthy for the ecosystem.
Why This Matters for the Industry
The open-source LLM revolution is reshaping AI industry structure in fundamental ways:
The "moat" is shrinking: The argument that frontier model capabilities are a durable competitive moat is weakening as open-source models close the gap. The sustainable competitive advantages are shifting to data, compute infrastructure, deployment quality, and enterprise relationships.
Vertical AI is becoming viable: Specialized AI for healthcare, legal, finance, manufacturing — fine-tuned open models may outperform general-purpose closed models in specific domains while costing a fraction of the API alternative.
AI sovereignty is becoming achievable: Nations and organizations that previously had no path to AI self-sufficiency now do. India, Europe, and Southeast Asia are investing in local open-source AI development.
My Take
The open-source LLM ecosystem has exceeded virtually everyone's predictions for how quickly it would develop. Two years ago, I would have said it would take 5 years for open-source models to approach frontier closed models on practical tasks. It took 18 months.
DeepSeek's training efficiency results deserve special attention. If frontier-level models can be trained for $6M rather than $100M+, the assumption that only large Western tech companies can develop frontier AI is wrong. The implications for both the competitive landscape and for AI governance are significant.
My concern: the "open" in "open source" is increasingly diluted by restrictive licenses. The community should be clearer about distinguishing truly permissive open models from open-weight models with commercial restrictions. Calling both "open source" creates false equivalence.
The Qwen ecosystem overtaking LLaMA in popularity is a geopolitically significant signal. Chinese AI labs are now producing models that the global developer community prefers to use over American alternatives. That's a competitive and strategic shift worth paying attention to.
Open-source AI is not just democratizing — it's redistributing AI capability globally in ways that will reshape the industry for a decade.
Paper: "The Open-Source Advantage in Large Language Models", arXiv: 2412.12004, Dec 2024. Updated context from 2025 ecosystem developments.
Explore more from Dr. Jyothi


