
Paper: Scaling Latent Reasoning via Looped Language Models arXiv: 2510.25741 | October 2025 Authors: Zhang et al.
The current playbook for building reasoning models goes like this: pre-train a large language model on a massive corpus, then post-train it to reason using RL, SFT on reasoning traces, or some combination. The reasoning capability is grafted on after the fact — it lives in the fine-tuning layer, not in the architecture.
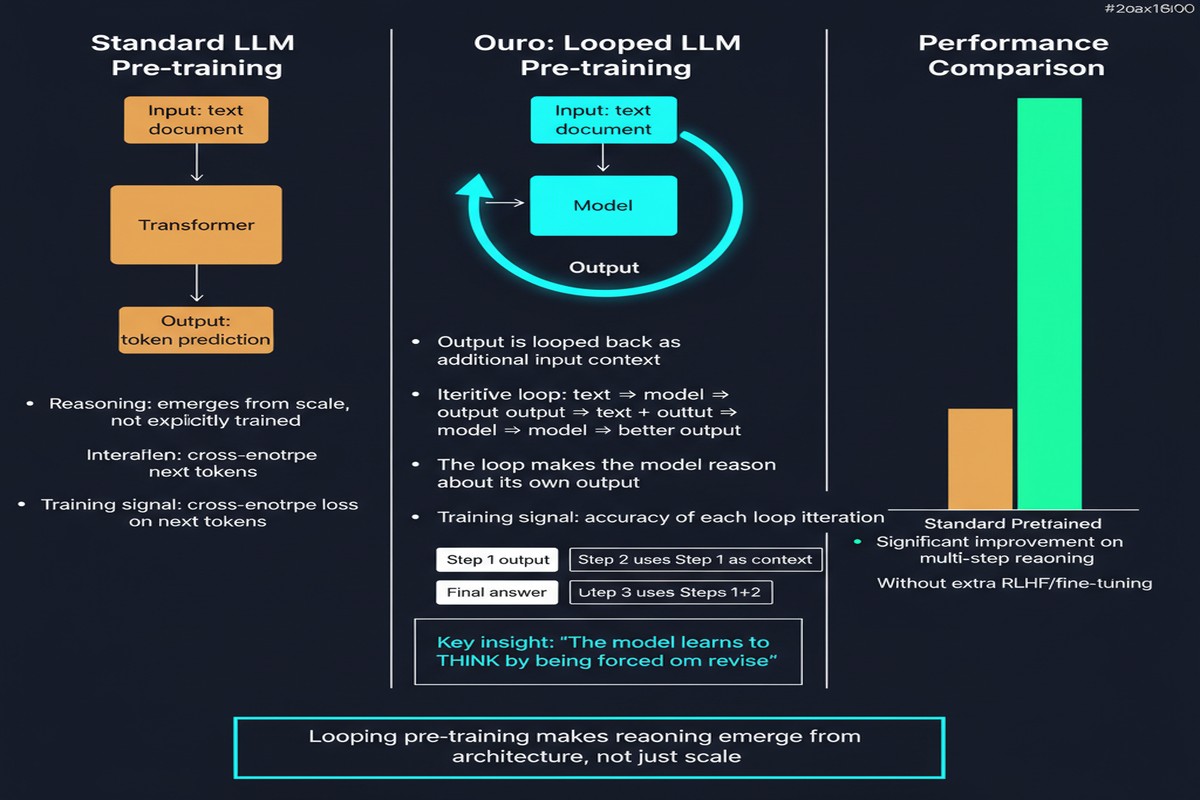
Ouro flips this. It proposes that reasoning should be a first-class citizen of the pre-training phase, baked into the architecture as an iterative computation loop that happens in latent space. The results are remarkable: a 2.6B parameter Ouro model matches 12B-class state-of-the-art LLMs across diverse benchmarks. The efficiency gain is not from a better training recipe on the same architecture — it comes from a fundamentally different model structure.
The Core Idea: Loop Depth as a Third Scaling Axis
Standard LLM scaling is a two-variable problem: you scale parameters and you scale data. More parameters means richer representations. More data means broader knowledge. Both are expensive, and both have well-known diminishing returns.
Ouro introduces a third axis: loop depth. The architecture applies the same transformer blocks repeatedly in a loop, allowing the model to compute iteratively over the same input before producing output. Each loop pass is an additional "step" of latent computation — no new tokens are generated, just deeper processing of existing state.
flowchart TD
subgraph "Standard LLM (Single Pass)"
A1[Input Tokens] --> B1[Layer 1]
B1 --> B2[Layer 2]
B2 --> B3[...]
B3 --> B4[Layer N]
B4 --> C1[Output Tokens]
end
subgraph "Ouro Looped LM (Multi-Pass)"
A2[Input Tokens] --> L1[Loop: Layers 1-N]
L1 --> L2[Loop: Layers 1-N again]
L2 --> L3[Loop: Layers 1-N again]
L3 --> L4[...]
L4 --> C2[Output Tokens]
note1[Parameters shared across loops] --> L1
end
The key architectural property: parameter sharing across loops. The same weights are used in every pass. This means Ouro's 2.6B parameter count reflects its storage size, not its effective computational depth. A 2.6B Ouro model running 4 loop passes performs computation equivalent to a 10B+ parameter model in terms of depth, with the same weight count.
The Training Innovation: Entropy-Regularized Loop Depth Allocation
A naive implementation of looped models hits an immediate problem: how many loops does each token need? Hard math requires more passes. Simple pattern matching needs fewer. If every token gets the same loop count, you waste compute on easy inputs and may under-compute on hard ones.
Ouro solves this with an entropy-regularized objective that trains the model to dynamically allocate loop depth based on difficulty. The entropy regularization encourages the model to route easy tokens to fewer loops (lower entropy over depth allocations) and hard tokens to more loops.
This is analogous to Mixture-of-Experts gating, but for computational depth rather than expert selection. It's a principled way to implement adaptive compute that learns from pre-training signal rather than being hand-engineered.
Benchmark Results
Ouro 1.4B and 2.6B models were pre-trained on 7.7 trillion tokens — a reasonable compute budget for models of that size. Results across diverse benchmarks:
| Model | Size | Key Benchmarks |
|---|---|---|
| Ouro (this paper) | 2.6B | Matches 12B SOTA models |
| Standard LLMs | 12B | Baseline |
| Ouro (this paper) | 1.4B | Matches 7B SOTA models |
The paper establishes that the performance gains come primarily from superior knowledge manipulation (how the model uses what it knows) rather than from increased knowledge capacity. Ouro doesn't know more facts — it reasons better with the facts it has.
Importantly, the reasoning traces produced by Ouro are more tightly aligned with its final outputs compared to chain-of-thought models. The latent reasoning is more coherent and less prone to the "reasoning theater" problem where models generate plausible-sounding thoughts that don't actually inform their conclusions.
Why This Matters
1. It challenges the post-training-centric paradigm. The entire reasoning model industry is built on the assumption that you pre-train a base model then teach it to reason. Ouro suggests that pre-training itself can be structured to produce models that reason natively, without post-training reasoning-specific fine-tuning.
2. Compute efficiency is real and significant. Matching a 12B model's performance with a 2.6B architecture is approximately a 4.6x parameter efficiency gain. At inference scale, this translates directly to cost reduction. For enterprises running millions of queries per day, this matters enormously.
3. Loop depth as a dial. At inference time, you can set the number of loops to trade off speed vs. quality. Fast answer? Run 2 loops. Hard problem? Run 8. This is a cleaner and more hardware-efficient version of the test-time scaling that s1 and o1 achieve through extended chain-of-thought generation.
4. Parameter sharing opens new efficiency frontiers. Weight sharing is an underexplored technique in modern LLMs. Ouro demonstrates that it's viable at scale without the quality degradation that early RNN-style sharing approaches suffered.
My Take
I find Ouro one of the most architecturally interesting papers of 2025. The looped architecture is not a new idea — Universal Transformers explored this in 2019 — but Ouro is the first paper to make it work convincingly at modern LLM scale with a clean training recipe.
My primary concern is the gap between reported benchmark performance and real-world generalization. Benchmarks measure specific, often narrow capabilities. The claim that "performance gains come from superior knowledge manipulation" is intriguing but requires more empirical backing across diverse task types — including creative, open-ended, and multi-step agentic tasks.
I also want to see loop depth ablations more carefully. The paper shows that more loops help, but the relationship between loop count and problem difficulty is not fully characterized. Understanding when additional loops stop helping (or hurt) would make the adaptive routing claim much stronger.
The bigger picture: Ouro is part of a quiet revolution in thinking about model efficiency. The field is moving from "scale everything proportionally" to "scale strategically based on what drives performance." Loop depth, mixture-of-experts gating, dynamic computation allocation — these are all instances of the same insight: not all computation is equally valuable for all inputs. The models that figure this out will win the efficiency race.
If the Ouro approach scales to 7B-70B models and maintains its efficiency advantage, it could fundamentally reshape the economics of deploying capable reasoning models. I'll be watching the follow-up work closely.
arXiv:2510.25741 — read the full paper at arxiv.org/abs/2510.25741


