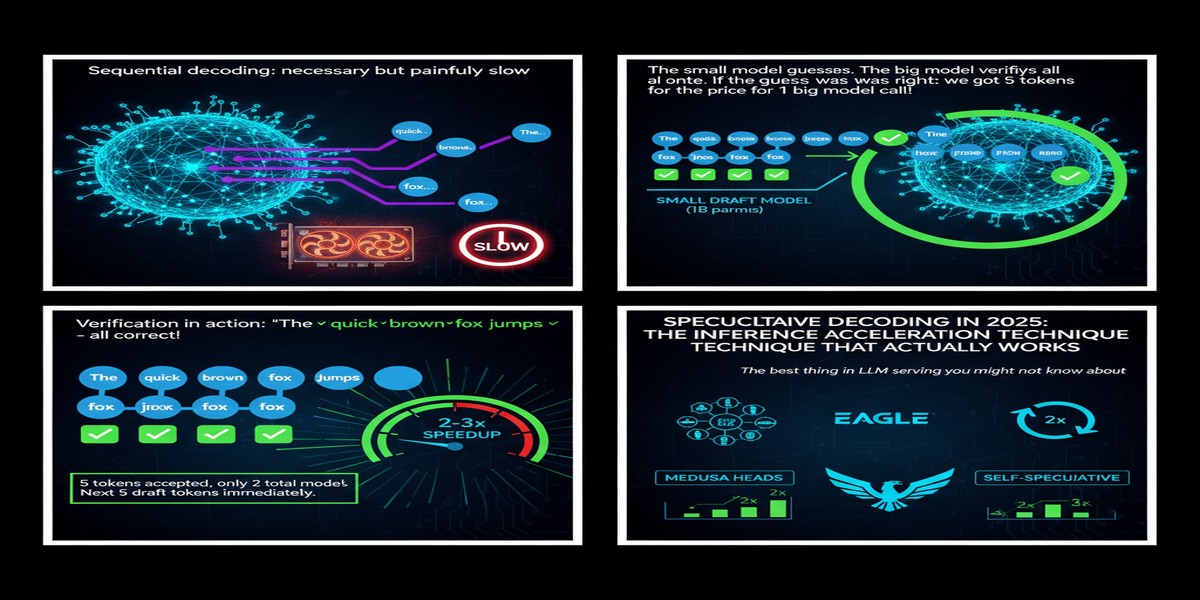
Speculative Decoding in 2025: The Inference Acceleration Technique That Actually Works
LLM inference is bottlenecked by a brutal constraint: autoregressive generation produces one token at a time, and each token requires a full forward pass through the model. For a 70B parameter model, that's expensive. For a 405B parameter model, it's existentially threatening to any product with latency requirements.
Speculative decoding is the most practically significant technique to emerge for addressing this problem. "Speculative Decoding and Beyond: An In-Depth Survey of Techniques" (arXiv: 2502.19732, Feb 2025) provides the field's most comprehensive taxonomy to date, covering dozens of variants, their trade-offs, and where things are going.
The Core Idea
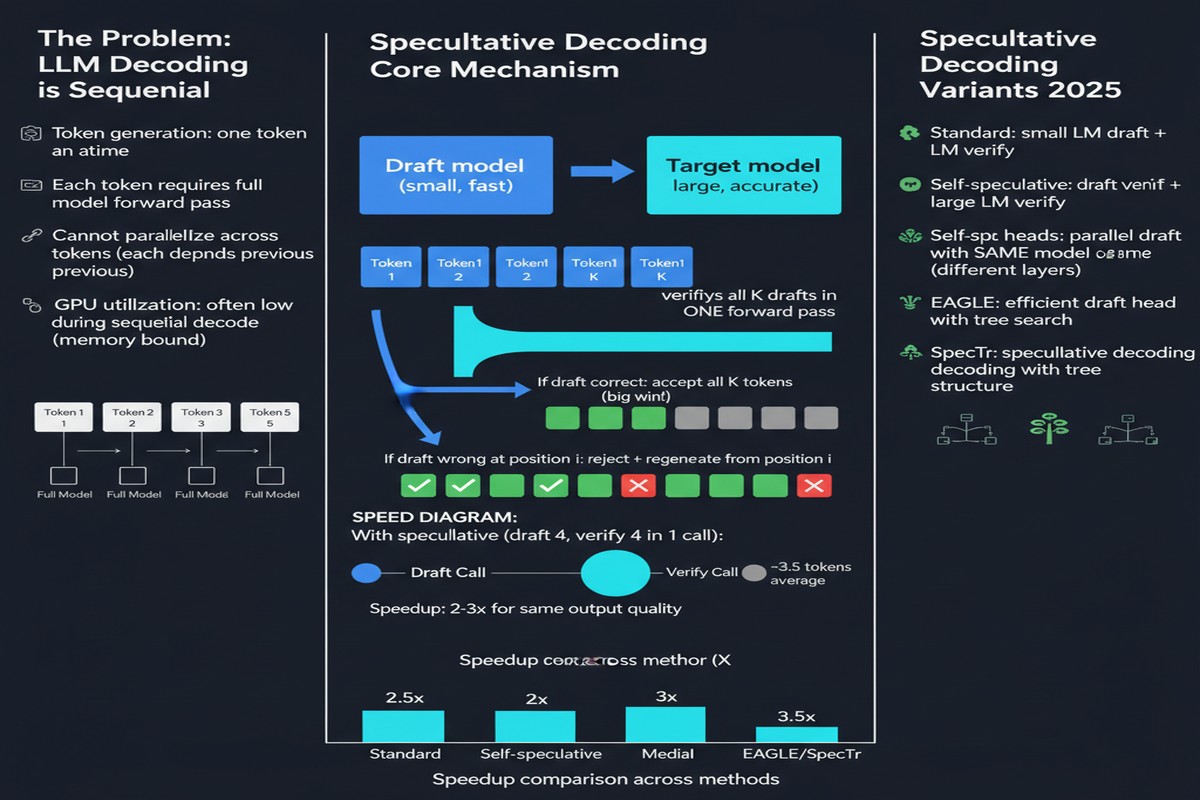
Speculative decoding was introduced independently by multiple groups in 2023, but the core mechanism is simple:
sequenceDiagram
participant D as Draft Model (small/fast)
participant T as Target Model (large/accurate)
participant O as Output
D->>D: Generate k draft tokens in parallel
D->>T: Submit draft tokens for verification
T->>T: Verify all k tokens in one forward pass
T->>O: Accept verified tokens, reject first wrong token
Note over T,O: Accepted tokens = free speedup!
A small draft model generates k candidate tokens speculatively. The large target model verifies all k tokens in a single forward pass (since verification is parallelizable even for autoregressive models). If the draft tokens match what the target would have produced, you get k tokens for the cost of approximately one target forward pass. On rejection, you fall back to sampling from the target at the first disagreement.
The mathematics guarantee that this produces exactly the same distribution as sampling from the target model alone. This is the key property: speculative decoding is a pure latency optimization with zero quality degradation.
The Taxonomy: A Messy but Useful Landscape
The survey organizes speculative decoding variants along several axes:
Draft Model Source
Model-based drafting: Use a smaller model from the same family (e.g., LLaMA-7B to draft for LLaMA-70B). The smaller model shares architectural inductive biases with the target, improving token acceptance rates.
Self-speculative / Draft-free methods: The target model drafts using its own early layers, intermediate states, or medusa-style parallel prediction heads — no separate model required. Reduces deployment complexity at the cost of some acceptance rate.
Retrieval-based drafting: Use an n-gram index built from the context window to propose candidate continuations. Surprisingly effective for long-document tasks like code completion or document summarization where repetition is common.
Diffusion-based drafting: DART (arXiv: 2601.19278) uses a diffusion model to draft non-autoregressive sequences, then verifies with an autoregressive target. Novel architecture combining two paradigms.
Verification Strategy
Standard speculative decoding uses token-level rejection sampling. Recent variants propose:
- Tree-based verification: Draft a tree of candidate sequences, not just a single sequence. The target verifies all branches simultaneously, recovering more accepted tokens on average.
- Speculative speculative decoding (ICLR 2026): A meta-approach where even the verification step is sped up through a recursive application of speculative decoding — drafters all the way down.
graph TD
A[Target Model] -->|Draft Request| B[Draft Model L1]
B -->|Draft Request| C[Draft Model L2]
C --> D[Fast N-gram Drafter]
D -->|k tokens| C
C -->|verified tokens| B
B -->|verified tokens| A
style A fill:#dc2626,color:#fff
style B fill:#d97706,color:#fff
style C fill:#2563eb,color:#fff
style D fill:#059669,color:#fff
System Deployment Variants
The survey breaks down single-model (one GPU, one process), pipeline-parallel, and distributed speculative decoding:
Distributed speculative decoding: The draft model runs on some nodes while the target model runs on others, overlapping compute. Can yield near-linear speedup in distributed settings if communication overhead is controlled.
Collective speculation: Multiple draft models vote on token candidates, with the target model verifying the majority-voted sequence. Reduces variance in acceptance rates.
Where Speculative Decoding Actually Helps (and Where It Doesn't)
The survey is admirably honest about limitations. Key findings:
Speculative decoding excels at:
- Low-batch inference (1-4 concurrent requests) where latency is the primary concern
- Tasks with high repetition or predictable structure (code, structured data)
- Long generations where draft-target acceptance rates stabilize over time
Speculative decoding struggles with:
- High-batch inference. When you can batch many requests, the GPU is already near-full utilization. The draft model's compute overhead becomes costly relative to the diminishing latency benefit.
- Creative/diverse generation tasks where draft acceptance rates fall below ~50%
- Tasks where the draft and target model families differ significantly (mismatched training distributions hurt acceptance rates)
The survey introduces the concept of γ-tolerance — the minimum acceptance rate threshold below which speculative decoding stops providing speedup. Understanding your task's typical acceptance rate is essential before committing to the technique.
The Production Reality
Despite academic enthusiasm, speculative decoding adoption in production has been slower than expected. The reasons are practical:
Model pairs are hard to maintain. If you update your 70B model, you need to either retrain your draft model or accept degraded acceptance rates.
Memory pressure. Running both draft and target models requires more GPU memory — not always available in tight deployment environments.
Speculative overhead in high-concurrency settings. As batch sizes grow, the marginal benefit of speculation decreases while overhead stays constant.
The most production-friendly variants are self-speculative methods (medusa heads, draft using early exit layers) because they avoid the two-model deployment problem. Retrieval-based drafting is compelling for specific use cases (document QA, code completion over known repos).
Why This Matters
Inference costs are the silent budget killer for LLM applications. While the world fixates on training costs, production deployments spend the majority of their compute budget serving requests. Any technique that reduces per-token inference cost by 2-4x is economically transformative at scale.
Speculative decoding does this. It's not vaporware — frameworks like vLLM, TGI, and TensorRT-LLM all support it in production. Understanding the trade-offs is now a prerequisite skill for ML engineers deploying LLMs.
My Take
The survey is comprehensive and useful — exactly what the field needed to consolidate two years of fragmented research. But I want to push back on one narrative: speculative decoding is not a silver bullet.
The academic community tends to benchmark at batch size 1, which is the ideal scenario for speculation. Production inference at scale looks different. When you're serving 1,000 concurrent users, you're not latency-bound on a single sequence — you're throughput-bound across a batch. Speculative decoding provides minimal benefit here and can actively hurt throughput by consuming compute that could go to batch parallelism.
The right mental model: speculative decoding is a latency optimization, not a throughput optimization. Use it when individual request latency matters more than aggregate throughput. Don't use it when you're trying to maximize tokens-per-second across a large workload.
The future frontier is learned draft models that specialize per-task or per-user, adapting acceptance rates dynamically. That's a harder problem but the right direction.
Paper: "Speculative Decoding and Beyond: An In-Depth Survey of Techniques", arXiv: 2502.19732, Feb 2025.