When teams first deploy a language model in production, training cost is usually their primary mental model of expense. This is understandable — a frontier model training run can cost millions of dollars and occupies a lot of attention. But for any successful application, inference cost quickly dominates. If you are serving a million queries per day, the per-query inference cost — multiplied by volume — becomes the number that keeps engineering leaders up at night.
The good news is that there is a rich and rapidly evolving toolkit for making inference substantially cheaper without unacceptable quality loss. The techniques — quantization, knowledge distillation, speculative decoding, and their combinations — are now mature enough that production teams can systematically apply them. Understanding what each technique does, where it helps, and where it hurts is essential knowledge for anyone building LLM applications at scale.
The Inference Cost Problem
Language model inference has a fundamental bottleneck: memory bandwidth. During autoregressive generation, the model generates one token at a time. Each token generation requires loading the model's weights from GPU memory (or CPU memory for smaller systems) through the compute units. For a 70B parameter model in float16, the weights alone require 140GB of memory. Generating each token requires reading all of that.
This is an IO-bound problem, not a compute-bound one. The GPU could perform many more floating-point operations per second than it is actually doing during inference; the bottleneck is how fast it can read the weight matrices from memory. This changes the optimization strategy compared to training, where full parallelism over large batches makes the problem compute-bound.
The implication is that techniques which reduce the memory footprint of the model — and therefore the amount of data that needs to be read per token generated — can dramatically improve inference throughput without requiring more powerful hardware.
Quantization: Trading Precision for Size
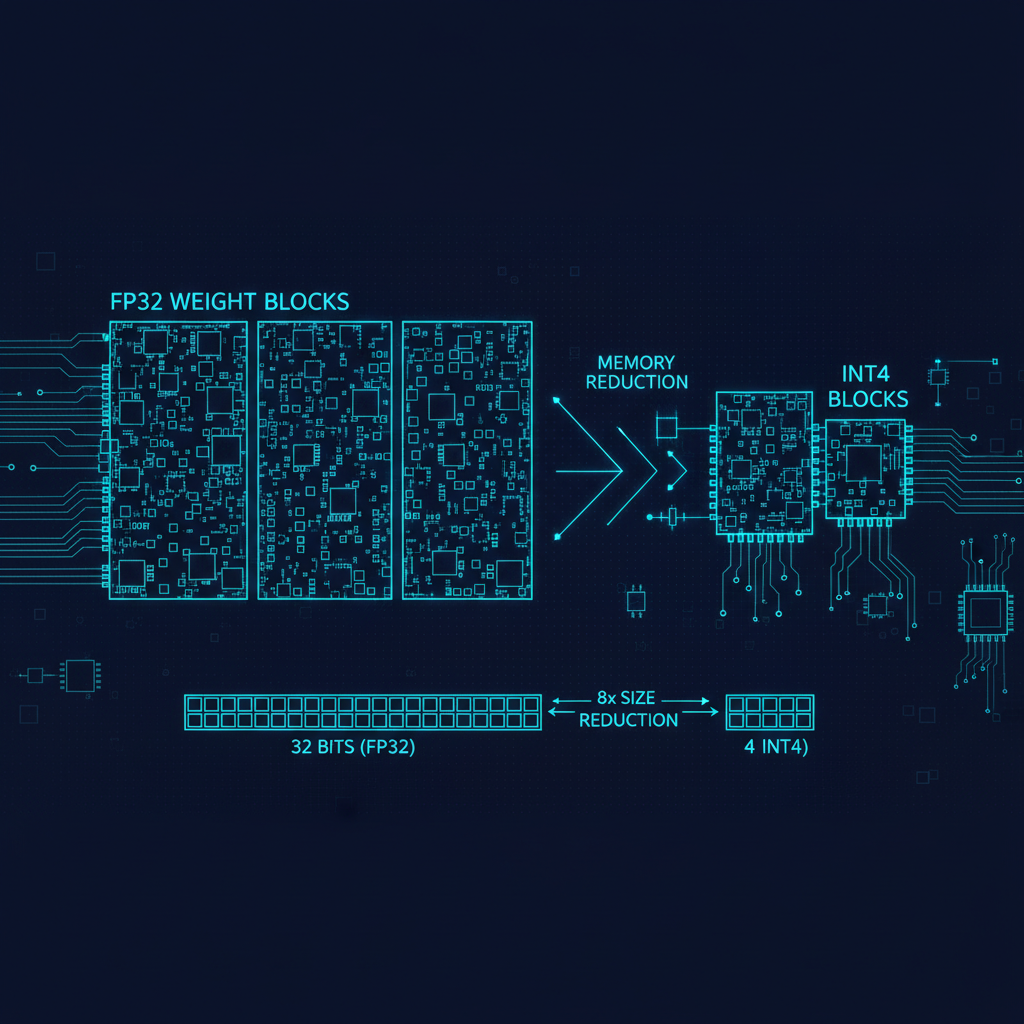
Quantization reduces the numerical precision used to represent model weights. Standard training uses 32-bit floating point (float32) or 16-bit (float16 or bfloat16). Inference can often use 8-bit integers (INT8) or even 4-bit integers (INT4) with acceptable quality loss.
The math is straightforward: a 70B parameter model in float16 requires 140GB. In INT8, it requires 70GB. In INT4, it requires 35GB. For deployment on commodity hardware — or even on devices — this matters enormously. A model that requires four A100 GPUs to serve in float16 can run on a single A100 in INT4.
The quality question is whether the quantization introduces meaningful degradation. For INT8 quantization of large models, the answer is generally no — the performance gap is within measurement noise on most benchmarks. This is essentially free. For INT4 quantization, there is a measurable but often tolerable degradation, especially for the most capable models where there is some margin to absorb.
GPTQ (Frantar et al., 2022) was a landmark paper that demonstrated high-quality weight-only quantization to INT4 for large language models by solving a layer-wise quantization problem that minimized output distortion. This made 4-bit quantization of frontier models practical for the first time. GPTQ-quantized models of Llama 2 and similar open models enabled researchers and developers to run 70B class models on consumer hardware that would previously have been impossible.
AWQ (Activation-aware Weight Quantization) followed shortly after, improving quality by identifying and protecting the most salient weights from aggressive quantization — specifically, the weights that have the largest impact on activations and therefore on output quality. AWQ typically outperforms GPTQ at the same bit width.
GGUF (a file format popularized by llama.cpp) brought efficient quantization to CPU inference, enabling models to run — slowly, but functionally — on laptops and even mobile devices. The llama.cpp project and its derivatives have been enormously important for democratizing access to capable language models outside of cloud GPU environments.
More recent work has pushed to 2-bit and even 1-bit quantization. The BitNet and 1-bit LLM papers explored training models with 1-bit weights from scratch (rather than quantizing post-hoc), demonstrating that models can learn effectively under this extreme compression constraint. While these are not yet competitive with full-precision models at the same parameter count, the direction is promising for edge and on-device deployment.
Knowledge Distillation: Learning from a Larger Teacher
Quantization makes a given model smaller and faster. Distillation changes the problem: instead of compressing a large model, you train a smaller model to mimic the behavior of a larger one.
The core insight (Hinton et al., 2015) is that a large model's output distribution contains more information than just the hard label. When a large model assigns 70% probability to "cat," 20% to "dog," and 10% to "fox" for an image of a cat, those soft probabilities reveal something about the model's learned representation — that cats and dogs are more similar than cats and foxes. A small model trained to match these soft distributions learns more efficiently than one trained only to predict the right label.
For language models, distillation typically works at the level of token probability distributions, next-token prediction distributions, or (in newer approaches) intermediate layer representations. The large "teacher" model generates supervision signals that the smaller "student" model learns to match. The student ends up with capabilities that transfer from the teacher far more efficiently than training from scratch on the same data.
DeepSeek's work on distillation for reasoning models is a compelling recent example. Their R1-Distill series trains Llama and Qwen base models on synthetic reasoning traces generated by DeepSeek-R1. The result is that a Llama 3.1 8B model trained on these traces dramatically outperforms the base model on math and reasoning benchmarks — approaching the performance of models ten times its size. This is a powerful template: use a large reasoning model to generate high-quality training data, then distill that capability into a much smaller, cheaper model for deployment.
The limits of distillation are also worth noting. A student model cannot exceed its teacher on capabilities that require more capacity than the student architecture can support. Very complex multi-step reasoning, broad encyclopedic knowledge, and nuanced judgment are harder to distill than specific structured capabilities like following a particular output format or solving a defined class of math problems.
Speculative Decoding: Using Small Models to Speed Up Big Ones
Speculative decoding is an elegant technique that addresses a different bottleneck: the sequential nature of autoregressive generation. Because each token depends on all previous tokens, standard generation cannot be parallelized across the sequence dimension.
Speculative decoding exploits the observation that a small, fast "draft" model can predict multiple candidate tokens ahead, and a large "target" model can then verify these candidates in parallel (since verification is a single forward pass over the full proposed sequence). If the draft model's predictions match what the target model would have generated, you accept them without cost; if they diverge, you reject from the first divergence and fall back.
The key insight is that the verification step is cheap relative to independent generation by the target model, because it is a parallel forward pass rather than sequential token generation. If the small model gets the next 4-5 tokens right most of the time (which it does for common continuations), you effectively generate 4-5 tokens in the time it would take to generate one from the large model alone.
Google's "Fast Inference from Transformers via Speculative Decoding" (Leviathan et al., 2023) and related work demonstrated 2-3x speedups on large language models with no quality loss whatsoever — the outputs are theoretically identical to what the large model would have generated alone. This is unusually clean: a free speedup with no quality tradeoff.
The practical requirements are a good draft model and careful implementation. The draft model should be the same model family as the target (so its distribution closely matches), but small enough to generate tokens significantly faster. Quantized versions of the target model, purpose-trained draft models, and n-gram based lookup tables have all been used as draft models in different contexts.
Batching, KV Cache Optimization, and System-Level Tricks
Beyond these three headline techniques, a cluster of systems-level optimizations further improve inference efficiency.
Continuous batching allows a server to process multiple requests simultaneously, filling GPU compute with work from many users rather than waiting for one request to complete before starting the next. This substantially improves throughput for API providers handling mixed-length requests.
KV cache compression and management reduces the memory cost of storing the key-value pairs from the attention mechanism, which grow linearly with context length. PagedAttention (vLLM) manages the KV cache with memory allocation strategies borrowed from operating systems, dramatically reducing memory waste and enabling higher concurrency.
Flash Attention during inference (not just training) reduces attention memory consumption, enabling longer contexts without proportional memory increases.
Tensor parallelism and pipeline parallelism distribute model weights across multiple GPUs in ways that improve throughput for large models that do not fit on a single device.
Putting It Together
For a production team, the practical strategy often looks like this: start with a quantized model (INT8 or AWQ INT4 depending on quality requirements), deploy with a system that supports continuous batching and efficient KV cache management, and explore distillation into a smaller model once you have enough traffic to justify the data collection and training cost.
Speculative decoding is particularly valuable for latency-sensitive applications where you care about time-to-first-token and generation speed for interactive use cases. For batch processing where throughput matters more than latency, it is less necessary.
The inference efficiency landscape moves fast — new quantization methods, new speculative decoding variants, and new hardware capabilities emerge constantly. But the underlying principles — reducing memory bandwidth requirements, exploiting parallelism, leveraging smaller models to accelerate larger ones — are durable and worth understanding deeply.


