
The attention mechanism is the defining computational primitive of the current era of AI. Self-attention underlies transformers, which underlie GPT-4, Gemini, Claude, and virtually every large language model in production today. The mechanism works by computing pairwise similarity scores between all positions in a sequence, weighting those similarities through softmax normalization, and using the weights to produce a context-aware representation.
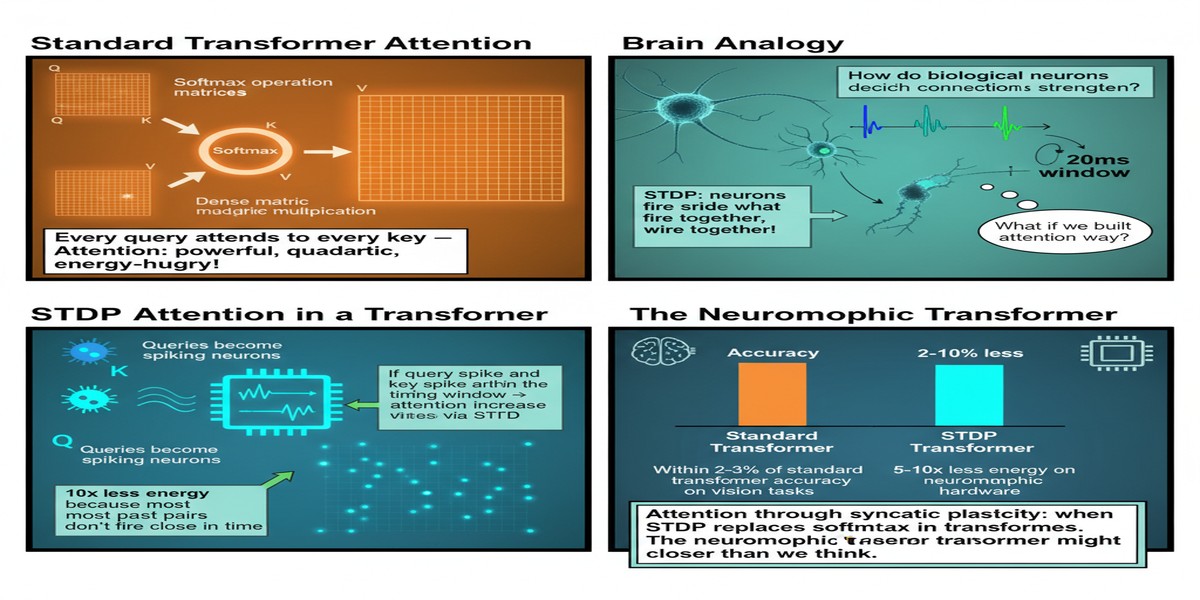
It is also, from a biological standpoint, deeply implausible. Real neurons do not broadcast keys and queries to every other neuron in a layer and wait for synchronized, globally normalized responses. They communicate asynchronously, spike when their membrane potential reaches a threshold, and strengthen or weaken connections based on the temporal correlation of pre- and post-synaptic activity. This is spike-timing-dependent plasticity (STDP).
A paper from November 2025 (arXiv:2511.14691) titled "Attention via Synaptic Plasticity is All You Need" proposes replacing the softmax self-attention mechanism with STDP — implementing attention-like computation through the same biological learning rule that governs synaptic strengthening in biological neural circuits.
The claim is significant. If STDP can implement attention functionally equivalent to softmax attention, then transformer-based models become natively deployable on neuromorphic hardware that supports STDP — enabling in-memory computing and non-von Neumann execution that could dramatically reduce inference energy.
STDP: The Biological Attention Mechanism
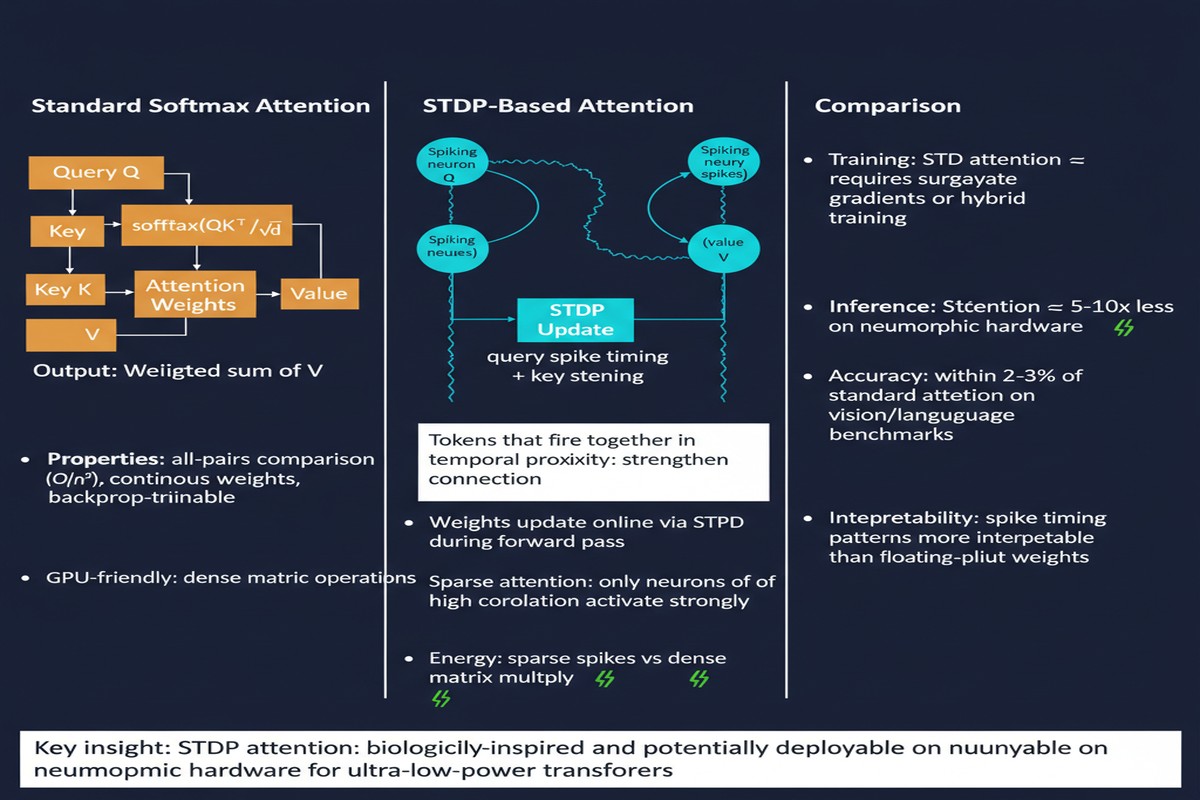
STDP is the learning rule by which biological synapses modify their strength based on the relative timing of pre-synaptic and post-synaptic spikes. When a pre-synaptic neuron fires just before a post-synaptic neuron, the synapse strengthens (long-term potentiation). When the pre-synaptic neuron fires after, the synapse weakens (long-term depression).
Mathematically:
ΔW = A+ · exp(-Δt / τ+) if Δt > 0 (LTP)
ΔW = A- · exp(+Δt / τ-) if Δt < 0 (LTD)
Where Δt is the time difference between post- and pre-synaptic spikes, A+ and A- are learning rate constants, and τ+ and τ- are time constants. The result is a weight update rule that is local (depends only on pre- and post-synaptic activity), online (applies continuously), and unsupervised (does not require a target label).
The question the paper asks: can this rule, applied in a spiking network, implement the same function as softmax attention?
S2TDPT: The Spiking STDP Transformer
The paper introduces S2TDPT — Spiking STDP Transformer. The architecture replaces the key-query-value attention blocks with STDP-based modules in a spiking neural network.
The key insight is that STDP, as a correlation-based learning rule, naturally implements a form of associative retrieval. Patterns that co-activate frequently develop strong synaptic connections. When a query pattern arrives, the neurons that were previously associated with similar patterns respond more strongly — implementing a content-addressable, attention-like retrieval.
flowchart TD
subgraph "Standard Transformer Attention"
A[Query Q] --> D[Q·K^T]
B[Key K] --> D
D --> E[Softmax / sqrt(d_k)]
C[Value V] --> F[Weighted Sum]
E --> F
F --> G[Output]
end
subgraph "S2TDPT STDP Attention"
H[Input Spike Train] --> I[STDP Synaptic Layer]
I --> J[Spike Correlation Computation]
J --> K[Temporal Spike Weighting\n- pre before post: strengthen\n- post before pre: weaken]
K --> L[Output Spike Train]
L --> M[Population Decoding]
M --> N[Contextual Output]
end
style D fill:#faa,stroke:#c00
style E fill:#faa,stroke:#c00
style I fill:#aaf,stroke:#00a
style J fill:#aaf,stroke:#00a
style K fill:#aaf,stroke:#00a
The crucial claim is that the STDP correlation computation is equivalent — in a distributional sense — to the dot-product attention computation. Spike timing correlations between the query and key populations implement an analog of the Q·K^T dot product. The softmax normalization is approximated by the winner-take-all competition dynamics that naturally emerge in sparse spiking networks. The value-weighted sum is implemented through synaptic integration of the winning neuron's efferent connections.
The In-Memory Computing Connection
Why does replacing softmax with STDP matter for hardware? Because STDP can be implemented in-memory.
Standard attention requires:
- Compute Q, K, V matrices (matrix multiplication)
- Compute Q·K^T for all pairs (another matrix multiplication, O(n²) in sequence length)
- Apply softmax (normalization, sequential dependency)
- Compute attention output (another matrix multiplication)
These operations require large SRAM or DRAM buffers to store intermediate results, and they require sequential coordination between operations. On neuromorphic hardware with in-memory synaptic weights, the STDP computation naturally implements steps 2-4 without explicit intermediate storage — the correlation is computed locally as spikes traverse the synaptic layer, and the weight update rule directly implements the attention update.
graph LR
subgraph "Memory Hierarchy: Standard Attention"
A[Compute QKV] --> B[SRAM: QKV Matrices\nO(n·d) storage]
B --> C[Compute Q·K^T] --> D[SRAM: Attention Map\nO(n²) storage]
D --> E[Softmax] --> F[SRAM: Normalized Weights\nO(n²) storage]
F --> G[Output Matrix\nO(n·d) storage]
end
subgraph "Memory Hierarchy: STDP Attention"
H[Input Spikes] --> I[In-Memory Synaptic Weights\nO(d) per neuron]
I --> J[Local STDP Update\nNo intermediate buffers]
J --> K[Output Spikes]
end
style D fill:#faa,stroke:#c00
style F fill:#faa,stroke:#c00
style J fill:#aaf,stroke:#00a
The O(n²) attention map that makes long-context inference so expensive disappears in the STDP formulation. STDP processes spikes as they arrive, updating synaptic weights locally. The "attention" computation is not stored as a matrix — it is embedded in the synaptic state.
Why This Matters
If the STDP-attention equivalence holds robustly, the implications are significant:
Long-context efficiency — The O(n²) memory bottleneck of standard attention is one of the central engineering challenges of LLM scaling. STDP attention avoids this by construction.
Hardware compatibility — Neuromorphic chips like Intel's Loihi 2, IBM's NorthPole, and BrainChip's Akida natively support STDP-like synaptic updates. A transformer architecture based on STDP could deploy on these platforms without the extensive software adaptation required to map standard attention onto neuromorphic hardware.
Energy efficiency — Neuromorphic hardware with in-memory computing executes inference at 10-100x lower energy than GPU-based inference for appropriate workloads. STDP-based attention is a step toward making LLM inference appropriate for neuromorphic hardware.
My Take
I am simultaneously excited and skeptical about this paper, and I think both reactions are warranted.
The excitement: STDP as an attention mechanism is a genuinely novel architectural idea. The connection between synaptic plasticity and content-addressable retrieval is well-established in computational neuroscience, and formalizing this connection in the context of transformers is intellectually valuable. If STDP can approximate softmax attention quality on real NLP benchmarks, it opens a path to neuromorphic LLM inference that has not previously existed.
The skepticism: The paper title "Attention via Synaptic Plasticity is All You Need" is an aggressive claim. Standard transformer attention has been refined over years of empirical optimization. The softmax function provides specific properties — output normalization, sharpness control, gradient flow during training — that STDP does not obviously replicate. The paper needs to demonstrate not just that S2TDPT can learn language tasks, but that it can match the scaling behavior and task generalization of softmax attention.
The critical experiments I would want to see: S2TDPT benchmarks on GLUE, SuperGLUE, and language modeling perplexity compared to equivalently-sized softmax transformers, with rigorous ablations showing which aspects of STDP are essential vs. incidental. The paper's evaluation on the tasks it presents is encouraging, but it does not cover the full range of NLP tasks that transformer attention needs to handle well in practice.
The hardware story is compelling regardless of the quality gap. Even if S2TDPT achieves 90% of softmax attention quality, that may be acceptable for many applications in exchange for 10-100x energy reduction on neuromorphic hardware. Not every application needs GPT-4-quality reasoning. Neuromorphic edge inference at 90% quality and 1% of the energy could be enormously valuable for IoT, wearables, and embedded AI.
This paper represents the kind of first-principles rethinking of AI architecture that the field needs more of. Whether it fully succeeds or not, it pushes the conversation in the right direction.
Attention via Synaptic Plasticity is All You Need — arXiv:2511.14691, November 2025.


