
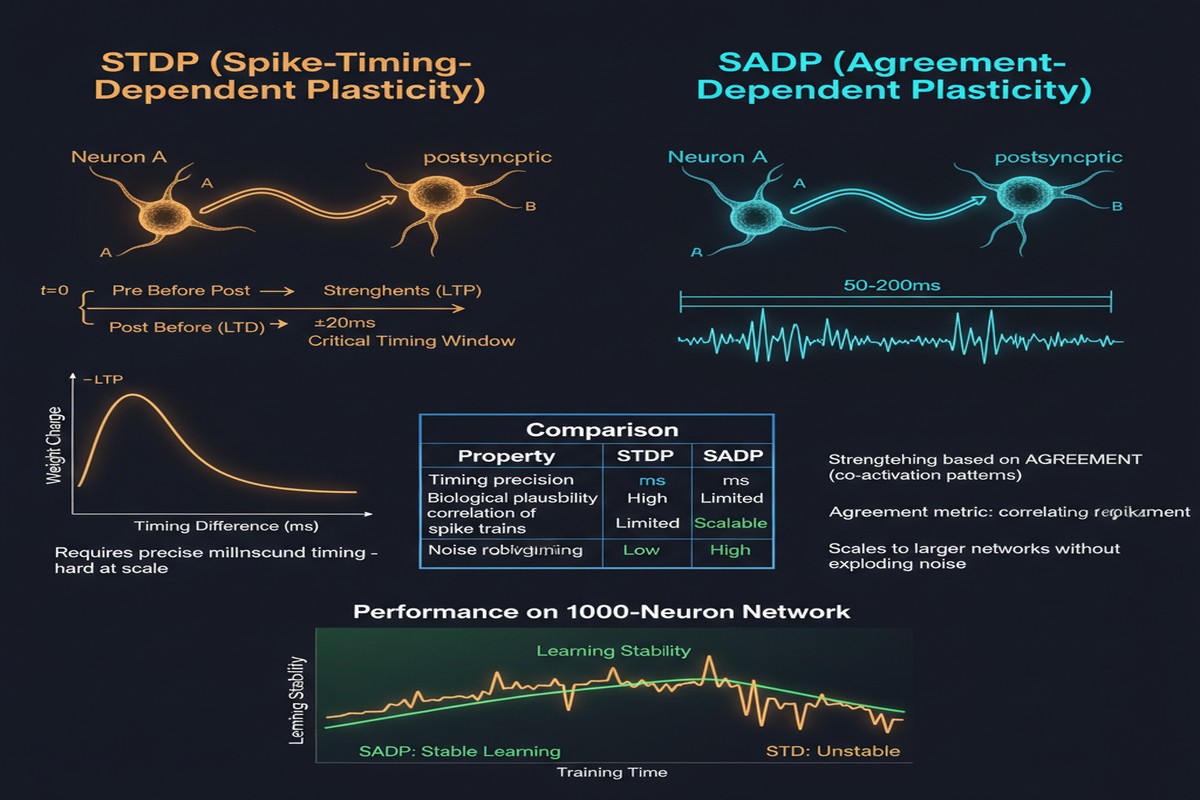
Spike-timing-dependent plasticity is one of the most celebrated ideas in computational neuroscience. The principle that synapses strengthen when pre-synaptic activity precedes post-synaptic activity, and weaken in the reverse case, offers an elegant biological learning mechanism that requires only local information. It is also, in its classical form, nearly impossible to scale.
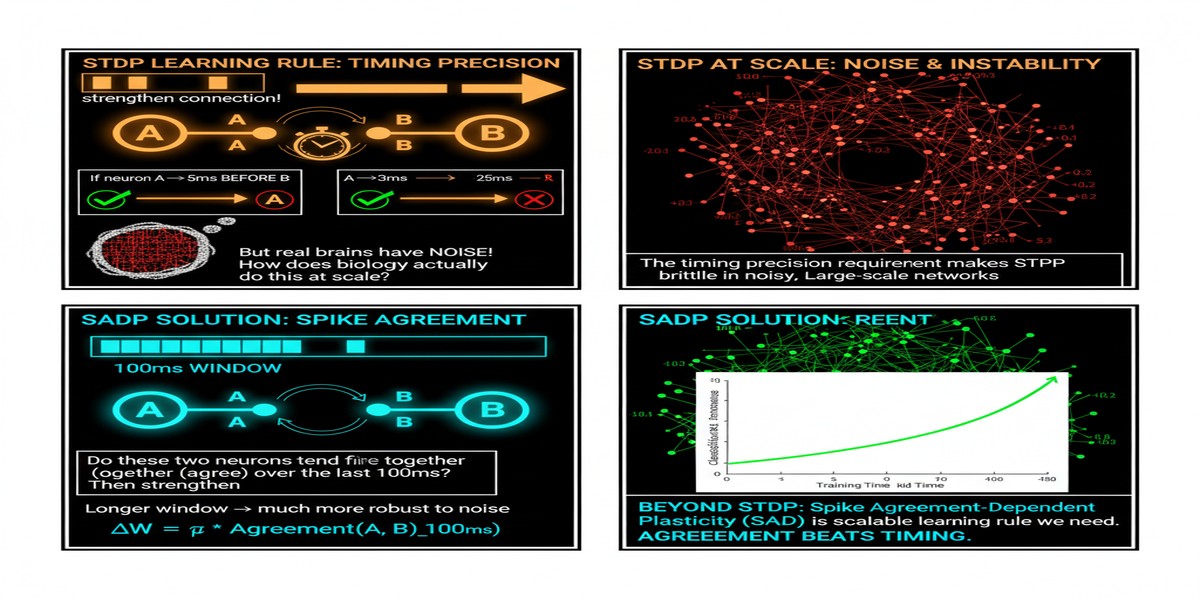
The problem is timing precision. Classical STDP requires knowing the exact millisecond at which each synapse fired — before or after its target neuron. In biological neural circuits, this precision is achieved through molecular calcium dynamics that neurons implement at negligible metabolic cost. In silicon, maintaining precise spike timing across millions of synapses in parallel requires either massive hardware resources (dedicated per-synapse timers) or serialization that destroys the parallelism advantage of neuromorphic computing.
A paper from August 2025 (arXiv:2508.16216) addresses this directly. "Spike Agreement Dependent Plasticity" (SADP) generalizes classical STDP by replacing pairwise temporal spike comparisons with population-level agreement metrics. The result is a learning rule with linear-time complexity instead of quadratic, efficient hardware implementation via bitwise logic, and performance that matches or exceeds classical STDP on standard benchmarks — without requiring millisecond timing precision.
The STDP Scaling Problem
To understand why SADP matters, it helps to quantify the STDP scaling problem precisely.
Classical STDP evaluates every spike pair: for each post-synaptic spike, you need to know when each pre-synaptic input fired relative to it. In a network with N neurons each connected to K inputs, this requires O(N·K) temporal comparisons per time step. For a network with 10,000 neurons and 1,000 inputs each, that's 10^7 comparisons per millisecond of simulated time.
graph TD
subgraph "Classical STDP Complexity"
A[N Neurons] --> B[K Inputs each]
B --> C[N × K Spike Pairs per step]
C --> D[O(N·K) Temporal Comparisons]
D --> E[Quadratic Complexity]
E --> F[Impractical for Large Networks]
end
subgraph "SADP Complexity"
G[N Neurons] --> H[Population Spike Pattern]
H --> I[Bitwise Agreement Check]
I --> J[O(N) Linear Comparisons]
J --> K[Linear Complexity]
K --> L[Scalable for Large Networks]
end
style E fill:#faa,stroke:#c00
style L fill:#afa,stroke:#090
This quadratic scaling is not merely an implementation inconvenience. It is a fundamental barrier to using STDP in large networks. The biological brain solves this problem through massive parallelism at the molecular level — each synapse independently implements its own timing mechanism. Silicon cannot replicate this architecture efficiently at scale.
SADP: Population-Level Agreement
SADP's key insight: instead of comparing individual spike times, compare population-level spike patterns. At each learning step, instead of asking "did pre-synaptic neuron i fire before post-synaptic neuron j in the last 10ms?", SADP asks "do the current spike patterns of the pre-synaptic population and the post-synaptic population agree?"
Agreement is defined using a population-level metric that can be computed as a bitwise operation on the spike activity vectors. If a group of neurons shows correlated spiking activity — the pre- and post-synaptic populations activate similar subsets of neurons — their synaptic connections strengthen. If they show anti-correlated activity, connections weaken.
Formally, the SADP update rule is:
ΔW_ij = η · agreement(pre_pattern_i, post_pattern_j)
Where agreement() is a function of population activity patterns rather than individual spike times. The paper defines multiple agreement functions, all computable in O(1) time via bitwise AND/OR/XOR operations on binary spike vectors.
flowchart LR
subgraph "Time Step t"
A[Pre-synaptic Population\nSpike Vector: 1010110101] --> B[Bitwise XOR/AND]
C[Post-synaptic Population\nSpike Vector: 1011010011] --> B
B --> D[Agreement Score]
D --> E[Weight Update: ΔW]
end
subgraph "Hardware Implementation"
F[Spike Registers: 1-bit per neuron]
G[XOR Gate Array: O(N) gates]
H[Popcount Circuit: O(log N) gates]
I[Weight Update Unit]
F --> G --> H --> I
end
The total complexity per learning step is O(N) — linear in the number of neurons, independent of the number of synapses per neuron. For a 10,000-neuron network with 1,000 inputs per neuron, SADP reduces the per-step computation from 10^7 to 10^4 operations — a 1,000x reduction.
Hardware Implementation
The bitwise nature of SADP is what makes it hardware-friendly. Binary spike vectors can be stored in compact registers. XOR and AND operations on spike vectors are basic digital logic operations. Popcounting (counting the number of 1s in a binary vector) is available as a single instruction in virtually all modern processor architectures (the popcount instruction on x86, ARM's vcnt instruction).
For dedicated neuromorphic hardware, SADP can be implemented as:
- One 1-bit register per neuron (spike state)
- XOR gate arrays for agreement computation
- Threshold logic for weight update decisions
- Standard weight memory (no dedicated per-synapse timers required)
This is qualitatively different from classical STDP, which requires per-synapse eligibility traces — continuous-valued memory elements that track recent pre- and post-synaptic activity. Eligibility traces consume area (each trace needs several bits of state) and must be updated continuously. SADP eliminates eligibility traces entirely, replacing them with the current-timestep spike pattern comparison.
The area savings are substantial. In neuromorphic hardware, synaptic state often dominates chip area. Replacing continuous eligibility trace storage with a single binary spike bit per neuron reduces the memory footprint of the learning mechanism by an order of magnitude.
Performance Results
The paper evaluates SADP on standard spiking neural network benchmarks:
- MNIST digit classification — pattern recognition with static inputs
- CIFAR-10 — visual object recognition with convolutional SNNs
- N-MNIST and N-CIFAR10 — neuromorphic sensor datasets with temporal structure
- Poisson-rate encoded temporal sequences — testing temporal learning capability
SADP matches classical STDP accuracy on all benchmarks while running in linear time. For the temporal sequence tasks — which most closely resemble the use cases where spike timing matters most — SADP shows only marginal accuracy degradation versus classical STDP, suggesting that the population-level agreement metric captures the relevant temporal structure even without millisecond-precise timing.
The benchmarks also show SADP generalization across network architectures: fully connected networks, convolutional networks, and recurrent networks all benefit from the SADP formulation.
Why This Matters
The neuromorphic hardware field has a painful gap: the learning algorithms developed in computational neuroscience (STDP, BCM, Oja's rule) are biologically inspired but hardware-impractical at scale. The algorithms that work on neuromorphic hardware (surrogate gradient descent, approximate BPTT) are effective but abandon the biological inspiration that motivated neuromorphic computing in the first place.
SADP bridges this gap. It is:
- Biologically motivated (extends STDP, captures the same correlation-based learning principle)
- Hardware-practical (linear complexity, bitwise operations, no eligibility traces)
- Performant (competitive accuracy with classical STDP on standard benchmarks)
If SADP holds up as a general learning mechanism, it enables neuromorphic hardware to support genuine online learning — updating synaptic weights during deployment, not just at training time. This is the distinguishing capability that neuromorphic hardware should offer over conventional AI accelerators, and classical STDP's impracticality has prevented it from being realizable at scale.
My Take
SADP is the right idea at the right time. The neuromorphic hardware field has been building faster and more energy-efficient inference chips without a practical learning mechanism to match. The disconnect has been frustrating: you have hardware that could theoretically support biological-style learning, but the learning rules are too expensive to run on the hardware they're designed for.
The move from pairwise temporal comparisons to population-level agreement metrics is elegant. It preserves the essential characteristic of STDP — correlation-based weight updates using only local information — while removing the dependency on precise timing that makes classical STDP impractical.
What I want to see in follow-up work: SADP applied to a production-scale neuromorphic chip (Loihi 2 or Akida), demonstrating real-time online learning on a meaningful task. The paper's evaluation is on standard benchmarks in simulation. The hardware implementation story is well-argued but not yet demonstrated in silicon. Getting from "hardware-efficient by analysis" to "actually efficient on real hardware" is a non-trivial step that requires tackling memory access patterns, clock domain issues, and physical layout constraints that simulation does not capture.
But the foundational idea is solid. Population-level agreement as a proxy for spike timing correlation is a genuine advance in neuromorphic learning theory. If followed up with hardware demonstration, this could become the standard learning rule for the next generation of neuromorphic chips.
Spike Agreement Dependent Plasticity: A scalable Bio-Inspired learning paradigm for Spiking Neural Networks — arXiv:2508.16216, August 2025.


