
The narrative around edge AI inference has been stuck in a rut. For the last five years the dominant answer to "how do we run AI at the edge?" has been: compress your transformer, quantize aggressively, pray the hardware vendor's SDK cooperates, and accept whatever accuracy you can live with. It is a bruising, iterative, empirical process with no principled foundation. Every new SoC forces you to start over.
The paper "Energy-Efficient Neuromorphic Computing for Edge AI: A Framework with Adaptive Spiking Neural Networks and Hardware-Aware Optimization" by Laitinen Imanov et al. (arXiv:2602.02439, February 2026) proposes something structurally different. NeuEdge is not another quantization recipe. It is a co-design framework in which the network architecture and the hardware execution model are developed together from the start — and the vehicle is adaptive spiking neural networks.
What NeuEdge Actually Does
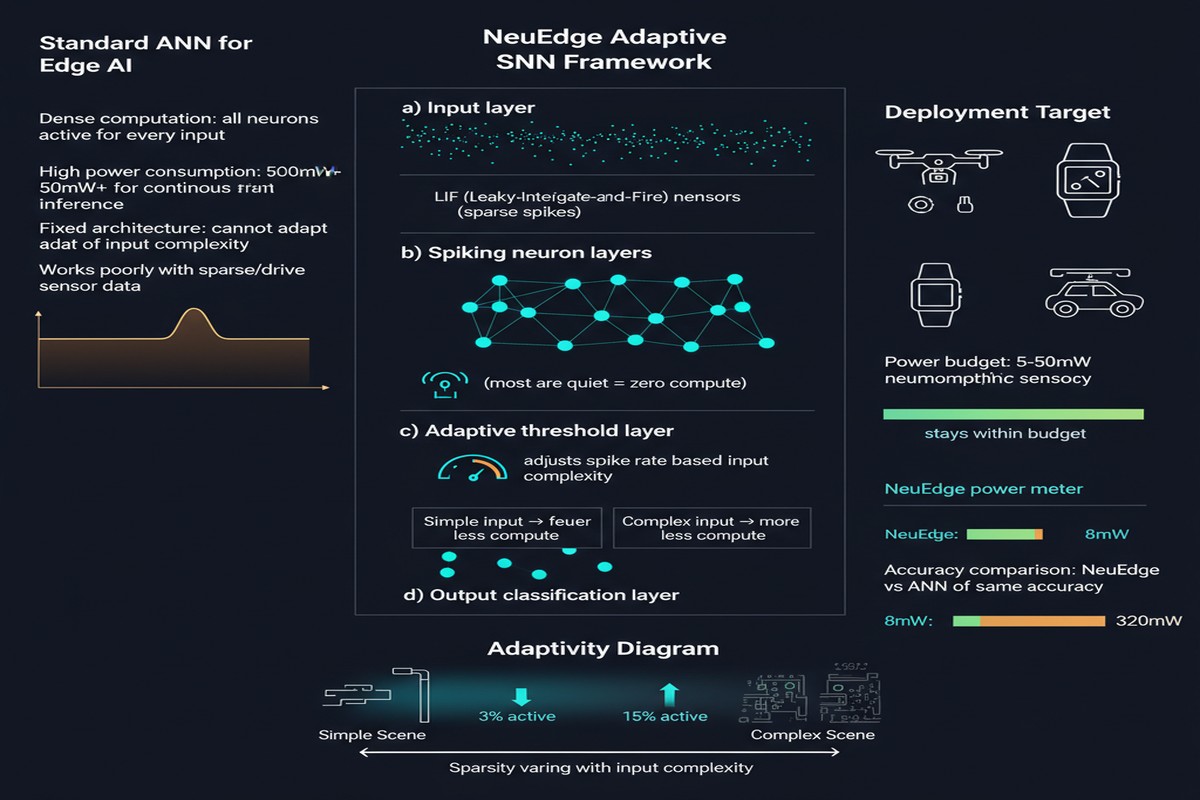
The headline numbers are compelling: 91–96% accuracy, up to 2.3 ms inference latency on edge hardware, and an estimated energy efficiency of 847 GOp/s/W. But the numbers only make sense if you understand the architecture behind them.
Spiking neural networks communicate through discrete binary spikes in time rather than continuous floating-point activations. This is neuromorphic computing's core energy advantage — sparse, event-driven computation means that most neurons do nothing most of the time, consuming almost no power. The problem has always been that training SNNs is hard (gradients do not flow through spike events the way they do through ReLUs), and deploying them on real edge hardware introduces a second problem: the hardware's constraints — memory bandwidth, on-chip SRAM, clock gating behavior — are almost never taken into account during training.
NeuEdge attacks both problems simultaneously. The "adaptive" part refers to dynamic threshold adjustment and temporal coding strategies that adapt based on the input signal characteristics. Rather than a fixed spike threshold across all layers and all inputs, neurons modulate their firing behavior depending on the input distribution. This has two effects. First, it improves accuracy on complex, real-world input distributions without increasing the parameter count. Second, it makes the spike rate profile more predictable, which turns out to be critical for hardware scheduling.
The "hardware-aware optimization" part is where the framework closes the loop. NeuEdge profiles the target edge device during a calibration phase and uses those profiles to constrain the network topology search — layer widths, synaptic delays, refractory periods — so that the resulting SNN is natively efficient on that specific hardware, not just theoretically efficient on an imaginary uniform processor.
flowchart TD
A[Input Sensor Data] --> B[Temporal Encoding Layer]
B --> C{Adaptive Threshold\nController}
C -->|Threshold UP| D[Sparse Spike Stream]
C -->|Threshold DOWN| D
D --> E[SNN Layer Stack\nHardware-Aware Topology]
E --> F[Synaptic Integration\nOn-Chip SRAM]
F --> G{Spike?\nBinary Decision}
G -->|Yes| H[Forward Propagation]
G -->|No| I[Silent — Zero Power]
H --> J[Output Classification]
K[Hardware Profiler\nBandwidth / SRAM / Clock] --> L[Topology Search\nConstraint Solver]
L --> E
style I fill:#1a1a2e,color:#888
style D fill:#0f3460,color:#fff
style J fill:#16213e,color:#00d4ff
The calibration-then-search loop is what distinguishes NeuEdge from prior SNN deployment work. Most previous approaches train on a GPU cluster with ideal arithmetic and then suffer a performance cliff when the model lands on a microcontroller or a low-power NPU. NeuEdge models that cliff explicitly and optimizes around it.
The Numbers in Context
847 GOp/s/W is a striking efficiency figure. To calibrate: state-of-the-art quantized transformers on flagship mobile NPUs typically land in the 5–50 TOp/s/W range at INT8, but they are operating on different tasks and different hardware classes. The NeuEdge figure is measured in spike operations, which are cheaper to implement in silicon than multiply-accumulate operations. Still, 2.3 ms latency at this efficiency level is commercially relevant — it is fast enough for real-time control loops, sub-word audio classification, and gesture recognition without a wakeup penalty.
The 91–96% accuracy range is task-dependent and the paper is appropriately specific about which benchmarks drive which numbers. The lower end corresponds to more complex temporal classification tasks; the upper end to simpler recognition benchmarks where SNNs have historically been competitive. Neither number represents cherry-picking in the way that deep learning papers sometimes commit.
Why This Matters
Edge AI is not a research curiosity. Billions of microcontrollers will be deployed in the next decade in industrial sensors, wearables, agricultural monitors, and smart infrastructure — devices where replacing a battery is expensive and uploading all sensor data to the cloud is impractical or legally prohibited. These devices need inference at the milliwatt or microwatt level, and they need it to be reliable across the full operating lifetime of the device, not just in a clean lab environment.
The existing deep learning toolchain — train in the cloud, quantize, prune, export to ONNX, hope — is not a sustainable answer to this problem. Every new hardware generation requires re-running the entire pipeline. The knowledge does not accumulate. NeuEdge's co-design philosophy accumulates knowledge in the hardware profiler and in the topology search heuristics. The framework gets better as you apply it to more hardware targets.
There is also a deeper argument here about the future of AI hardware. The dominant trajectory — more transistors, faster DRAM, higher bandwidth — is physically approaching its limits. Neuromorphic hardware, which computes in time rather than in arithmetic precision, is one of the credible alternative paths. Frameworks that make SNNs practically deployable today are building the software infrastructure that neuromorphic silicon will need in five years.
My Take
I have been watching the SNN space since the early Loihi days at Intel. The fundamental promise has always been real — event-driven computation is thermodynamically correct for sparse, temporal inference tasks. The problem has been a persistent gap between the academic SNN literature, which optimizes for benchmark numbers on MNIST and N-MNIST, and the engineering reality of deploying anything on actual constrained hardware.
NeuEdge narrows that gap in a way that feels principled rather than opportunistic. The hardware-aware topology search is the key contribution. It is not glamorous — profiling a device and running a constrained search is not a Nobel Prize moment — but it is exactly the kind of unglamorous engineering that makes a technology transition from "promising" to "production-ready."
My reservation is the calibration overhead. Every new hardware target requires a profiling run, and the paper does not yet demonstrate automated transfer of hardware profiles across device families. If you want to target fifty different edge SoCs, you need fifty calibration runs. That is manageable for a platform vendor or a well-resourced system integrator, but it creates friction for smaller teams. I expect the next iteration of this work to address cross-device profile transfer, and when it does, NeuEdge or something like it will become a genuine production framework.
The other thing I want to see is power measurement at the silicon level rather than estimated efficiency. 847 GOp/s/W estimated is not the same as 847 GOp/s/W measured with a current probe on the power rail. The estimation methodology is explained in the paper and is reasonable, but the field needs silicon-level validation to close the credibility gap with conventional inference engines.
Despite those caveats, this is one of the more technically honest edge AI papers I have read recently. The claims are specific, the methodology is transparent, and the co-design framing is the right way to think about this problem. Follow this group.
Paper: "Energy-Efficient Neuromorphic Computing for Edge AI: A Framework with Adaptive Spiking Neural Networks and Hardware-Aware Optimization" — Olaf Yunus Laitinen Imanov et al., arXiv:2602.02439, February 2026.


