
There is a recurring pattern in computing history: we build systems that approximate nature, and then we discover that nature was right all along. Spiking Neural Networks (SNNs) are that reckoning for machine learning. For two decades, they were dismissed as too hard to train, too niche to matter. The 2025 survey paper by Sales G. Aribe Jr. (arXiv:2510.27379) makes a compelling case that we have crossed a threshold. SNNs are no longer a curiosity — they are a credible alternative to the deep learning stack we have all been building on.
Let me tell you why I think this paper matters, what it actually says, and where I think the field goes from here.
What the Paper Does
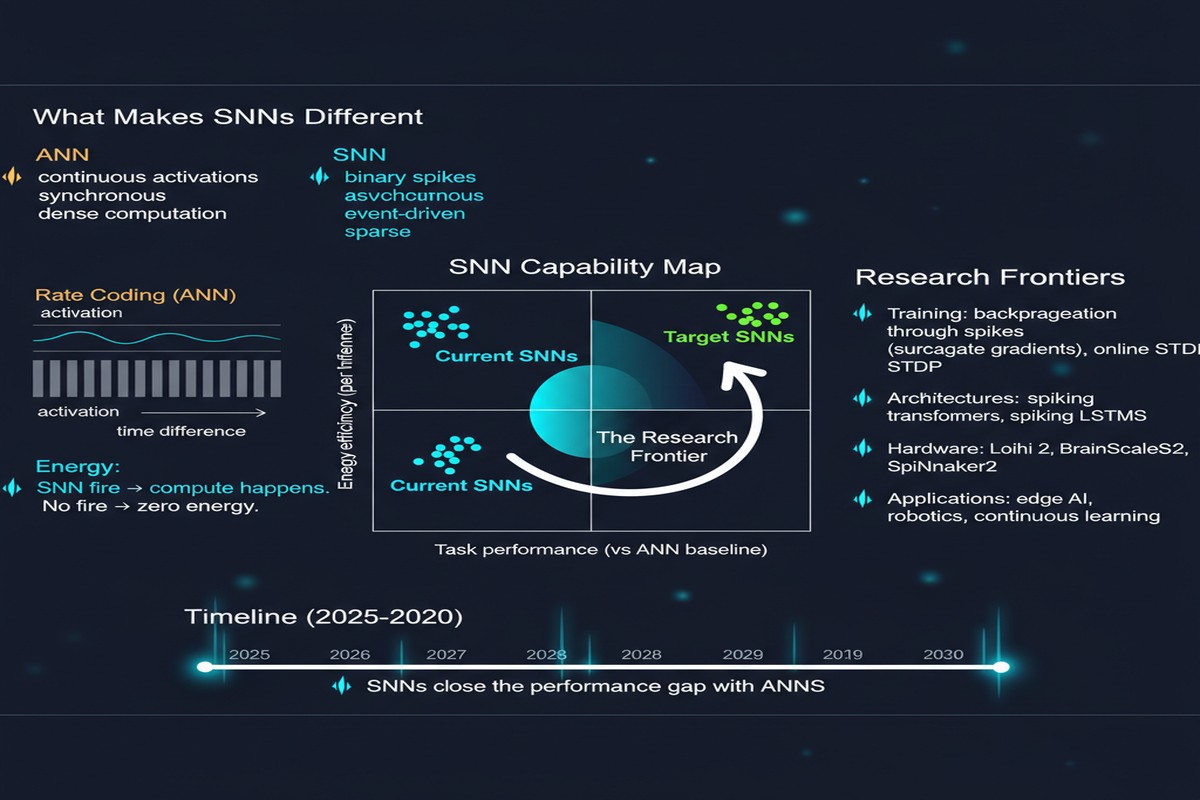
Aribe Jr.'s survey is a comprehensive taxonomy of the SNN design space: neuron models (LIF, Izhikevich, AdEx), encoding schemes (rate, temporal, population), training paradigms (STDP, surrogate gradients, conversion from ANNs), and hardware implications. It synthesizes work across simulation frameworks — NEST, Brian2, SpikingJelly — and benchmarks on standard datasets like CIFAR-10, ImageNet subsets, and DVS gesture.
The organizing insight is that the SNN design space has two distinct regimes, and conflating them has caused enormous confusion in the literature.
Regime 1: Supervised SNNs with surrogate gradients. These networks are trained end-to-end using differentiable approximations to the spike function. They are essentially ANNs with a different activation. The paper reports that state-of-the-art surrogate gradient SNNs match ANN accuracy within 1–2% on standard benchmarks, with convergence typically achieved by epoch 20 and inference latency as low as 10 ms on neuromorphic hardware.
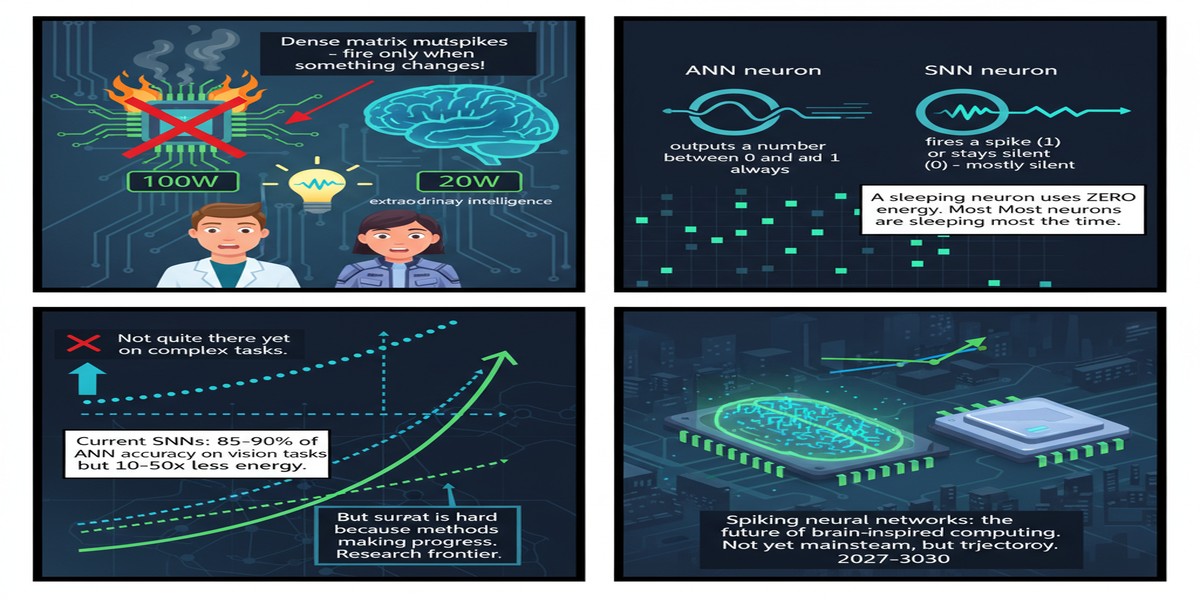
Regime 2: Unsupervised SNNs with STDP. Spike-Timing Dependent Plasticity is the biologically plausible local learning rule that has fascinated computational neuroscientists for thirty years. These networks do not converge to ANN-level accuracy on complex tasks, but they achieve something else entirely: energy consumption as low as 5 mJ per inference — roughly two orders of magnitude below what a GPU requires. For low-power edge tasks where you do not need ImageNet-level discrimination, this is not a consolation prize. It is a decisive advantage.
The Architecture of a Spiking Neural Network
Understanding why SNNs are different requires understanding what happens inside a single neuron. A conventional ReLU neuron computes a weighted sum and fires a continuous value every time it is queried. A leaky integrate-and-fire (LIF) neuron accumulates membrane potential over time and fires a discrete spike only when a threshold is crossed — then resets.
flowchart TD
A[Input Spikes from Upstream Neurons] --> B[Synaptic Integration\nWeighted sum of incoming spikes]
B --> C{Membrane Potential\nV_m > V_threshold?}
C -- No --> D[Leak: V_m decays toward rest\nNo output spike]
C -- Yes --> E[Fire: Output spike emitted\nV_m reset to V_reset]
D --> F[Wait for next timestep]
E --> G[Refractory period\nNeuron silenced briefly]
G --> F
F --> A
style E fill:#1a73e8,color:#fff
style C fill:#fbbc04,color:#000
The key insight here is sparsity. In a well-designed SNN, most neurons are silent at most timesteps. You do not pay the compute cost of a multiplication unless a spike actually arrives. On dedicated neuromorphic silicon, this translates directly to energy savings. On a GPU, it does not — which is why SNN benchmarks on GPUs look unimpressive. The hardware must match the computation model.
Training: The Surrogate Gradient Breakthrough
The historical obstacle to training SNNs was the non-differentiability of the spike function. A Heaviside step function has zero gradient almost everywhere, and infinite gradient at the threshold. Backpropagation through time does not work cleanly.
The surrogate gradient approach — pioneered by Neftci et al. and now standard — replaces the spike function derivative with a smooth proxy during the backward pass (typically a sigmoid or piecewise linear function) while using the true spike function in the forward pass. The paper validates that this works empirically: 1–2% accuracy gap versus ANNs is genuinely competitive.
What the paper does not say loudly enough, in my view, is that this convergence result is epochal. For years the argument against SNNs was "you cannot train them to competitive accuracy." That argument is over.
xychart-beta
title "SNN vs ANN Training Convergence (Surrogate Gradient)"
x-axis [1, 5, 10, 15, 20, 25, 30]
y-axis "Accuracy (%)" 0 --> 100
line [45, 68, 79, 85, 89, 90, 91]
line [52, 74, 84, 89, 92, 93, 93]
By epoch 20, the SNN has converged to within the 1–2% band of the equivalent ANN. After that, diminishing returns set in for both. The question shifts from "can we train SNNs?" to "should we bother?"
Why This Matters
The energy argument is the one that will ultimately win the debate in industry. Modern LLM inference is scandalously expensive. A single forward pass through a 70B parameter model consumes joules. Data centers are facing power constraints that no amount of hardware scaling will resolve. Neuromorphic computing is not a niche academic exercise — it is a thermodynamic necessity if we want to keep scaling AI.
The 5 mJ per inference figure for STDP-based SNNs is context-dependent (it applies to edge classification tasks, not large language models), but the directional claim is sound: sparse, event-driven computation is fundamentally more efficient than dense matrix multiplication. We need to stop pretending otherwise.
There is also a latency story. 10 ms end-to-end inference on neuromorphic hardware is fast enough for real-time robotics, sensory processing, and edge control loops. GPU-based inference at this scale typically requires either expensive hardware or batching tricks that destroy the latency profile.
My Take
I have watched the neuromorphic computing field for years with a mixture of admiration and frustration. The biology is beautiful. The engineering has been painfully slow. But Aribe Jr.'s survey captures a genuine inflection point, and I want to be direct about what I think it means.
The surrogate gradient result closes the accuracy argument. If you are running a production classification system and you need to hit 93% top-1 on some benchmark, SNNs can now do that. The gap is 1–2%, and in most real applications that gap is within measurement noise and dataset bias. This is not a theoretical claim — it is reproducible across multiple frameworks and datasets.
The STDP result points at a different market. Nobody is going to run STDP for ImageNet classification. But for always-on keyword spotting, anomaly detection in IoT sensors, or low-power gesture recognition, 5 mJ per inference against a battery-powered device is a game-changer. This is the market Intel, BrainChip, and SpiNNaker are fighting over, and it is larger than most people realize.
The hardware fragmentation is the real problem. The paper surveys deployment on Intel Loihi, IBM TrueNorth, SpiNNaker, and several academic chips. None of them share a programming model. Writing an SNN for Loihi requires a completely different workflow than writing one for SpiNNaker. Until there is something analogous to CUDA — a programming abstraction that works across neuromorphic backends — adoption will be limited to specialists.
My prediction: within 18 months, we will see a serious open-source neuromorphic abstraction layer that ports SNNs across at least two major commercial platforms. The pressure from the energy efficiency argument is too strong for the ecosystem to remain fragmented. This survey is one more data point pushing the field toward that consolidation.
The future of brain-inspired computing is not coming. Based on this paper, it is already here — it just needs better tooling.
Paper: Sales G. Aribe Jr., "Spiking Neural Networks: The Future of Brain-Inspired Computing," arXiv:2510.27379, October 2025.


