
Most discussions of Spiking Neural Networks focus on the neuron model: how the membrane potential integrates, when the spike fires, how the potential resets. Far less attention goes to synaptic delays — the time it takes for a spike to travel from one neuron to another. This is a significant omission, because synaptic delays are where temporal structure lives. They are what allow biological neural circuits to compute with time, not just in time.
The paper by Mészáros, Knight, Timcheck, and Nowotny (arXiv:2510.13757) is important precisely because it takes synaptic delays seriously. They build a complete end-to-end pipeline: train SNNs with heterogeneous synaptic delays on GPU, then deploy them on Intel Loihi 2. The results — 18x faster and 250x more energy efficient than NVIDIA GPU for keyword recognition — are impressive. But the architecture of the pipeline itself is, I think, the more lasting contribution.
Why Synaptic Delays Matter
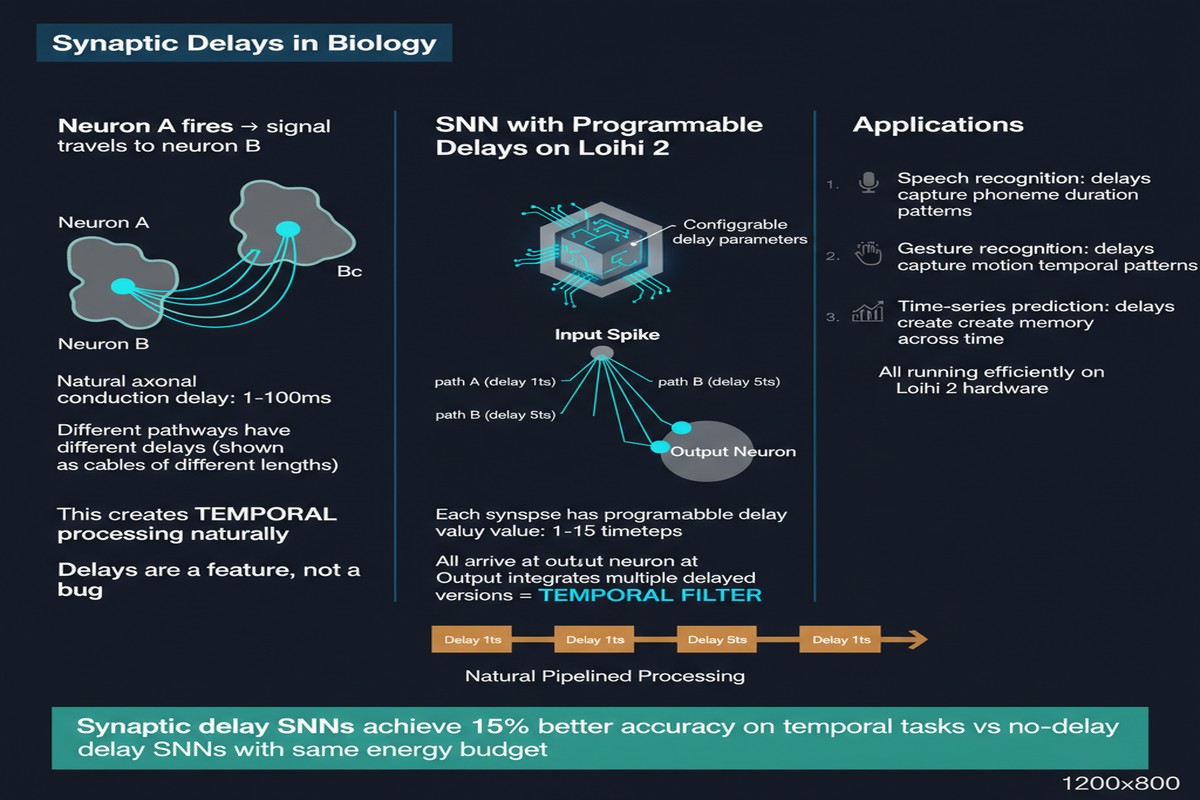
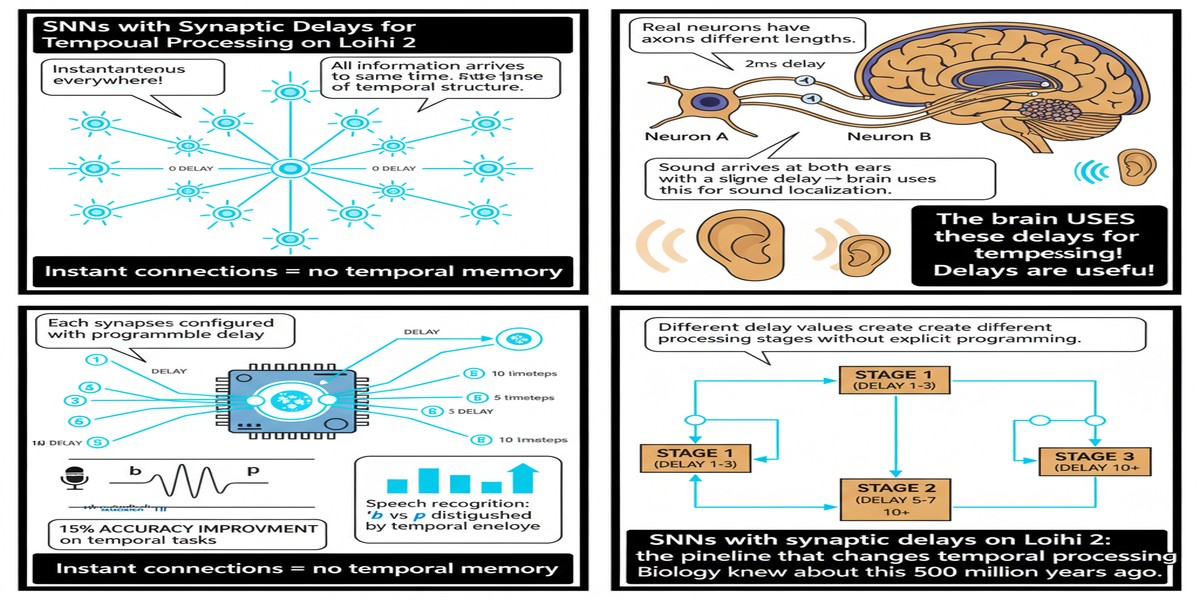
To understand why this paper is interesting, consider the standard SNN model without delays. At each timestep, every spike propagates instantaneously to all downstream neurons. The network computes in discrete time, but all neurons within a layer process the same timestep simultaneously. This is synchronous even when it claims to be asynchronous.
Biological neurons do not work this way. Axons have finite conduction velocity. Dendritic trees introduce processing delays. The same spike can arrive at different downstream targets with delays that differ by milliseconds — and those milliseconds carry information. The hippocampus uses delay lines to compute phase relationships between oscillating circuits. The auditory brainstem uses precisely calibrated synaptic delays to compute the microsecond timing differences between your two ears that tell you where a sound comes from.
When you add heterogeneous synaptic delays to an SNN, you give it the ability to learn temporal patterns — not just the presence of features, but their timing relationships. This is particularly valuable for sequential data: speech, audio events, time-series anomalies, anything where what happened is inseparable from when it happened.
flowchart TD
subgraph NeuronA["Pre-synaptic Neuron A\n(fires at t=0)"]
A[Spike at t=0]
end
subgraph Synapses["Heterogeneous Synaptic Delays"]
D1[Delay = 1ms\nFast pathway]
D2[Delay = 5ms\nMedium pathway]
D3[Delay = 15ms\nSlow pathway]
D4[Delay = 30ms\nLong-range pathway]
end
subgraph NeuronB["Post-synaptic Neuron B\n(integrates across time)"]
B1[Receives at t=1ms]
B2[Receives at t=5ms]
B3[Receives at t=15ms]
B4[Receives at t=30ms]
B5{Threshold\ncrossed?}
B1 --> B5
B2 --> B5
B3 --> B5
B4 --> B5
end
A --> D1 --> B1
A --> D2 --> B2
A --> D3 --> B3
A --> D4 --> B4
style D1 fill:#34a853,color:#fff
style D4 fill:#ea4335,color:#fff
style B5 fill:#1a73e8,color:#fff
The challenge is that synaptic delays dramatically increase the state space of the network. A network with 1,000 neurons and maximum delay of 30 timesteps has 30,000 distinct states to track (one per neuron per delay slot). Training this efficiently on GPU requires careful memory management and a differentiable formulation of the delay mechanism.
The Pipeline Architecture
Mészáros et al.'s contribution is a complete toolchain that handles this complexity from end to end.
Stage 1: Event-Based Training on GPU. The training framework extends standard surrogate gradient training to support heterogeneous synaptic delays. Each synapse has a learned delay parameter in addition to its weight. The delay is represented as a differentiable variable; the surrogate gradient flows through both weight and delay. The implementation uses efficient sparse tensor operations to manage the expanded state space without blowing up GPU memory.
The training is event-based: rather than simulating the full network state at every timestep, the system only updates neurons that receive at least one spike. This is important for efficiency — a network with long delays and sparse inputs spends most of its time doing nothing, and the event-based implementation correctly accounts for this.
Stage 2: Compilation to Loihi 2. The trained model is compiled for Intel Loihi 2 using a custom backend that maps the delay parameters onto the chip's multi-compartment neuron model. Loihi 2 supports programmable synaptic delays natively — this is one of its key advantages over earlier neuromorphic chips. The compiler assigns each delay value to the appropriate chip resource, checks for resource constraints, and generates the Lava program that runs on-chip.
Stage 3: Deployment and Evaluation. The deployed model runs in fully event-driven mode on Loihi 2, with no GPU involvement during inference. The chip's asynchronous routing fabric handles spike propagation across delay values.
flowchart LR
subgraph Training["GPU Training Phase"]
T1[Raw Audio\nEvent Stream]
T2[Surrogate Gradient\nTraining]
T3[Delay Learning\nDifferentiable delay params]
T4[Trained SNN\nWeights + Delays]
T1 --> T2
T2 --> T3
T3 --> T4
end
subgraph Compilation["Compilation"]
C1[Delay-Aware\nCompiler]
C2[Resource Mapping\nLoihi 2 compartments]
C3[Lava Program\nGeneration]
C1 --> C2 --> C3
end
subgraph Deployment["Loihi 2 Inference"]
D1[Event-Driven\nSpike Routing]
D2[On-Chip Delay\nBuffers]
D3[Async Neuron\nUpdates]
D4[Output\nClassification]
D1 --> D2 --> D3 --> D4
end
Training --> Compilation
Compilation --> Deployment
The Benchmark: Keyword Recognition
The paper evaluates on two standard neuromorphic audio benchmarks: Spiking Heidelberg Digits (SHD) and Spiking Speech Commands (SSC). These are event-based encodings of spoken digit and command recognition tasks, designed specifically for neuromorphic systems. They are well-regarded benchmarks because they preserve temporal structure rather than converting audio to spectrograms and treating it as an image.
The results are striking:
- Speed: Loihi 2 implementation is up to 18x faster than NVIDIA GPU (inference latency)
- Energy: Loihi 2 is up to 250x more energy efficient than NVIDIA GPU
- Accuracy: near-zero accuracy loss compared to the GPU-trained baseline
The 250x energy figure is in the same territory as the continual learning paper I reviewed earlier (which reported 5,600x for a different task type). For audio processing specifically, the combination of event-based input (audio events naturally map to spikes) and synaptic delays (audio is fundamentally temporal) creates a particularly favorable mapping onto neuromorphic hardware.
The near-zero accuracy loss is the part I find most technically significant. SNNs with synaptic delays trained on GPU and compiled to Loihi 2 do not degrade appreciably. This validates the entire pipeline — the training, the compilation, and the on-chip execution are all faithful to each other.
Why This Matters
Audio processing is one of the most compelling near-term markets for neuromorphic computing. The reasons are structural:
Always-on requirements: Keyword spotting for voice assistants must run continuously, even in standby mode. A device that wakes on "Hey Siri" runs that detection loop 24 hours a day. At current edge GPU power consumption, this is a battery killer. At Loihi 2 power consumption, it is not.
Temporal structure: Audio is inherently temporal. Synaptic delays let SNNs model the timing relationships in speech that are invisible to spatial feature extractors. This is not just an efficiency advantage — it is a representational advantage.
Microphone as event sensor: Standard microphones produce continuous waveforms. Silicon cochleae and neuromorphic microphones produce spike trains directly. The gap between sensor and processor collapses when both are spike-based. Mészáros et al.'s pipeline is designed for this future.
The paper also matters because of what it solves operationally: the gap between training and deployment. This is the unsexy but critical engineering problem in neuromorphic computing. Researchers train models in Python on GPUs and then face a painful manual translation process to get them onto neuromorphic chips. Every manual translation step introduces bugs, requires specialized knowledge, and discourages adoption. An end-to-end pipeline that automates this process is infrastructure — it is the kind of work that enables ten other research groups to build on it.
My Take
I have been watching the neuromorphic toolchain problem for years, and it frustrates me that it took this long to get a clean end-to-end pipeline for something as natural as audio processing with temporal delays. The neuroscience has known about synaptic delays for decades. The hardware has supported them (Loihi 2 natively, SpiNNaker with workarounds) for years. The gap was always the training and compilation toolchain.
Mészáros et al. close that gap for one important use case, and they do it with engineering discipline that I respect. The event-based training formulation is elegant. The delay-aware compiler is a real contribution. The zero-accuracy-loss deployment is the validation that makes the whole thing credible.
My critique is narrow but pointed: the paper evaluates on specialized neuromorphic audio benchmarks (SHD, SSC), not on standard speech recognition benchmarks (LibriSpeech, Common Voice). This is understandable — standard benchmarks use conventional acoustic features, not event streams. But the field needs to establish neuromorphic performance on the benchmarks that matter to industry, not just the benchmarks designed to make neuromorphic look good. Until we have Loihi 2 numbers on LibriSpeech, the argument for deploying this in a consumer product remains more academic than commercial.
That said, the pipeline is the thing. If I were building an edge audio processing product and power budget was my primary constraint — which it is for most wearables and IoT devices — this paper gives me a complete path from training to deployment. That is valuable regardless of which benchmark it was validated on.
Synaptic delays are not a niche feature. They are how temporal computation should work. This paper takes them from neuroscience curiosity to engineering reality.
Paper: Balázs Mészáros, James C. Knight, Jonathan Timcheck, Thomas Nowotny, "A Complete Pipeline for Deploying SNNs with Synaptic Delays on Loihi 2," arXiv:2510.13757, October 2025.


