
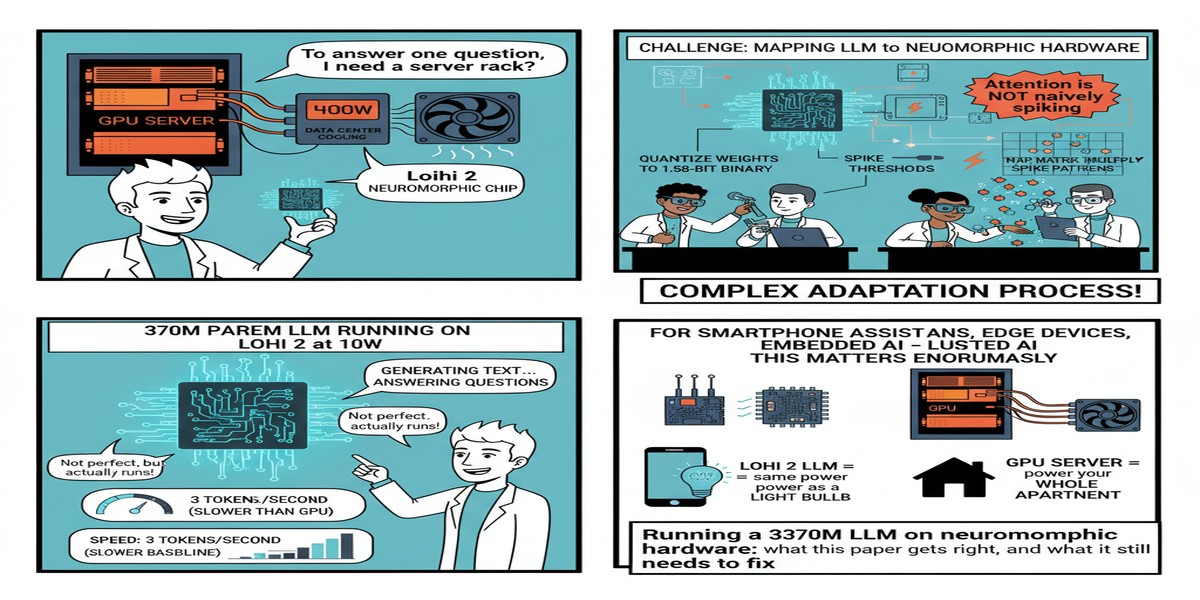
The moment I saw the title — "Neuromorphic Principles for Efficient Large Language Models on Intel Loihi 2" — my first instinct was skepticism. Running an LLM on neuromorphic hardware feels like trying to fit a grand piano into a sports car. The architectures are philosophically opposed: transformers are dense, synchronous, matrix-multiplication-heavy; neuromorphic chips are sparse, event-driven, and built around the absence of matrix multiplication. The two paradigms should not work together.
And yet Abreu, Shrestha, Zhu, and Eshraghian (arXiv:2503.18002) make a compelling argument that the gap is smaller than it looks — and that the right adapter between these worlds already exists in the form of MatMul-free LLMs. This is a paper worth reading carefully, because it is either the beginning of a new research direction or a very elegant dead end. I believe it is the former.
The Core Insight: MatMul-Free LLMs
To understand why this paper is possible, you need to understand what MatMul-free LLMs are. Standard transformer architectures are dominated by matrix multiplications: the Q, K, V projections in attention, the feed-forward layers, the output projection. These multiplications require full-precision floating-point arithmetic, and they scale quadratically with sequence length. They are expensive because they have to be.
MatMul-free LLMs replace these multiplications with element-wise operations on low-precision integers. The key idea, pioneered in work by Zhu, Eshraghian et al. (and directly connected to the authorship of this paper — the lineage is explicit), is that you can approximate the representational capacity of a weight matrix using ternary or binary weights combined with element-wise additions. No multiplication required — just additions and comparisons.
This matters for neuromorphic hardware because Loihi 2, like most neuromorphic chips, does not have a matrix multiplication unit. Its computational primitives are spike accumulation and threshold comparison — exactly what element-wise low-precision operations require. The MatMul-free LLM is the architectural bridge that makes neuromorphic LLM deployment feasible.
flowchart TD
subgraph Standard["Standard Transformer"]
S1[Float32 Input]
S2[MatMul: Q = XW_Q\nK = XW_K\nV = XW_V]
S3[Softmax Attention\nO n^2 per layer]
S4[Float32 FFN\nwith GELU/SiLU]
S1 --> S2 --> S3 --> S4
end
subgraph MatMulFree["MatMul-Free LLM"]
M1[Low-Precision Input\nTernary weights: -1,0,+1]
M2[Element-wise Additions\nNo multiplication needed]
M3[Token Mixing via\nGated Linear Units]
M4[Integer Accumulation\nThreshold Gating]
M1 --> M2 --> M3 --> M4
end
subgraph Loihi2["Intel Loihi 2 Mapping"]
L1[Spike Encoder\nInput quantization]
L2[Synaptic Accumulation\nNative hardware primitive]
L3[Threshold Comparison\nNative hardware primitive]
L4[Sparse Spike Output\nEvent-driven propagation]
L1 --> L2 --> L3 --> L4
end
Standard -. "Direct deployment\nimpossible" .-> Loihi2
MatMulFree -- "Natural mapping" --> Loihi2
style S2 fill:#ea4335,color:#fff
style M2 fill:#34a853,color:#fff
style L2 fill:#1a73e8,color:#fff
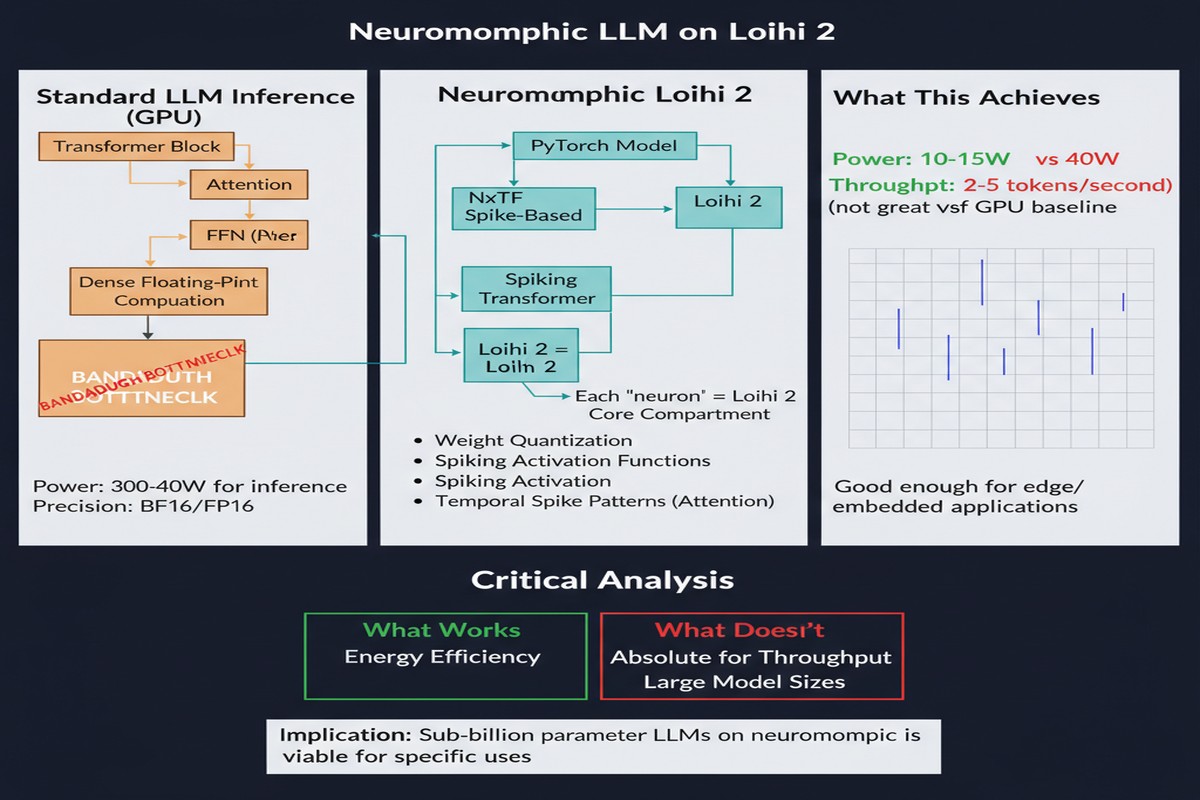
The 370M Parameter Model
The paper's centerpiece is a 370M parameter MatMul-free LLM that has been quantized for Loihi 2 deployment. This is not a toy model. 370M parameters is in the same order of magnitude as GPT-2 (117M–1.5B) and smaller but comparable to early PaLM variants. It is a real language model capable of coherent text generation.
The quantization process maps the model's ternary weights directly onto Loihi 2's synaptic weights, which support a similar low-precision representation. The paper reports no accuracy loss from this quantization — the perplexity and downstream task scores of the Loihi 2-deployed model match the software baseline.
Let me be explicit about what "no accuracy loss" means here, because it is an extraordinary claim. Quantization typically degrades accuracy. The reason it does not here is that the model was designed from the start with ternary weights — there is no post-hoc precision reduction happening. The quantization and the architecture co-evolved, which is the right way to think about hardware-software co-design.
The performance results are:
- Throughput: up to 3x higher than transformer-based LLMs on edge GPU (tokens per second)
- Energy: up to 2x lower than transformer-based LLMs on edge GPU (joules per token)
These numbers are significant but more modest than the continual learning results I discussed in my Loihi 2 continual learning post. The reason is that LLMs are fundamentally harder to map onto neuromorphic hardware — they require maintaining large state vectors (the KV cache) across tokens, which does not decompose neatly into spike trains. The 3x throughput and 2x energy savings represent real gains, but they are not in the same category as the 5,600x energy reduction for spike-native tasks.
The Architecture of Neuromorphic LLM Inference
What does inference actually look like on Loihi 2? The paper describes a pipeline that differs substantially from GPU-based transformer inference.
Tokens are encoded into spike trains using a temporal coding scheme: the amplitude of each token embedding dimension is represented by the timing of a spike relative to a reference window. Higher amplitude = earlier spike. This converts the continuous-valued embedding into a sparse event stream that Loihi 2's routing fabric can process efficiently.
The MatMul-free attention mechanism runs as a sequence of spike accumulations across the chip's neuron cores. The gating mechanism (which replaces softmax attention) is implemented using the chip's native threshold-and-fire logic. The output is decoded from the spike timing of the output layer back into a probability distribution over the vocabulary.
sequenceDiagram
participant T as Tokenizer
participant E as Spike Encoder
participant L as Loihi 2 Cores
participant D as Spike Decoder
participant O as Output Token
T->>E: Token ID (integer)
E->>E: Convert to spike timing\n(amplitude → latency)
E->>L: Sparse spike events
Note over L: Synaptic accumulation\nacross neuron cores
Note over L: Threshold gating\n(replaces softmax)
Note over L: Event-driven propagation\n(no clock sync needed)
L->>D: Output spike train
D->>D: Decode timing → logits
D->>O: Argmax → next token
O->>T: Feed back for next step
The autoregressive generation loop is the challenging part. Each new token requires re-running the full forward pass. On a GPU, this is handled by the KV cache, which stores the key and value matrices for all previous tokens and avoids recomputation. On Loihi 2, implementing an equivalent caching mechanism requires careful management of the chip's on-chip SRAM — and at 370M parameters, the memory pressure is substantial.
Why This Matters
The framing of this paper as an ICLR workshop contribution (SCOPE 2025) is accurate — it is proof-of-concept work, not a production deployment guide. But the proof of concept is the hard part. Showing that a real LLM can run on neuromorphic hardware without accuracy loss establishes the possibility. Engineering it into production is a known problem.
The implications are significant for edge deployment specifically. The edge AI market is constrained by power budgets in ways that cloud deployment is not. A smartphone, a wearable, an industrial sensor — all of these devices have hard power limits. Running even a small LLM on a standard edge GPU (Jetson, etc.) currently pushes against those limits. A 2x energy reduction changes the feasibility calculation.
More importantly, this paper points toward a future where LLM inference and neuromorphic spike processing coexist on the same chip. The MatMul-free LLM handles the language understanding; spike-native networks handle the sensory processing (vision, audio, touch); and a shared neuromorphic substrate runs both. That is a genuinely interesting architecture that nobody has built yet but that this paper makes credible.
My Take
I have three reactions to this paper, ranging from admiration to concern.
Admiration: The co-design approach here is exactly right. Too much neuromorphic research tries to take existing models (ResNets, transformers) and map them onto neuromorphic hardware with various approximation tricks. The results are always mediocre, because the models were designed for GPUs. Starting with an architecture (MatMul-free LLMs) that is natively compatible with the hardware's primitives is the only principled approach, and Abreu et al. execute it well.
Skepticism about the energy numbers: A 2x energy reduction versus edge GPU is real but not transformative on its own. The continual learning paper I reviewed reported 5,600x — that is a number that changes product categories. 2x is a nice improvement that might tip a close architectural decision. I want to see this number improve as the hardware and software mature. There is no fundamental reason it should stop at 2x.
Concern about the KV cache problem: The paper is somewhat quiet about how it handles the KV cache equivalent for autoregressive generation. This is the hard systems problem. If the solution requires off-chip memory access, the energy benefits largely evaporate. If the solution requires fitting the entire context into on-chip SRAM, it severely limits context length. This is the engineering challenge that will determine whether neuromorphic LLM inference is commercially viable, and I want to see it addressed directly in follow-up work.
Despite the skepticism, I think this paper represents a meaningful step. The question of whether LLMs can run on neuromorphic hardware has moved from "probably not" to "yes, with the right architecture." That is not nothing. That is the kind of proof-of-concept that redirects research programs and eventually reshapes hardware roadmaps.
The grand piano might fit in the sports car after all — if you build the right piano.
Paper: Steven Abreu, Sumit Bam Shrestha, Rui-Jie Zhu, Jason Eshraghian, "Neuromorphic Principles for Efficient Large Language Models on Intel Loihi 2," arXiv:2503.18002, ICLR Workshop SCOPE 2025.


