
Let me make a claim that will irritate some of my computer vision colleagues: frame-based cameras are the wrong sensor for the majority of high-speed robotic perception tasks. They are temporally aliased, they blow out in high-dynamic-range scenes, they waste power on redundant pixel reads, and they force every downstream algorithm to pretend that 30 or 60 snapshots per second is a reasonable model of a continuous physical world. The only reason we keep using them is inertia and tooling maturity.
Neuromorphic vision sensors — event cameras — do not have these problems. They report changes in log-luminance per pixel, asynchronously, with microsecond-level timing resolution and a dynamic range that exceeds 120 dB. The question is not whether they are physically superior for motion and edge detection tasks. They are. The question is why adoption remains so slow.
The review paper "Hardware, Algorithms, and Applications of the Neuromorphic Vision Sensor: A Review" by Cimarelli, Millan Romera, Voos, and Sanchez-Lopez (University of Luxembourg; arXiv:2504.08588, April 2025; also published in MDPI Sensors 25(19):6208) is the most comprehensive account I have read of the current state of this field. It organizes the landscape across three axes — hardware evolution, event-based algorithms, and real-world applications — and it is admirably honest about where the gaps are. Reading it as a practitioner, those gaps explain a lot about why event cameras are still niche.
How Neuromorphic Vision Sensors Work
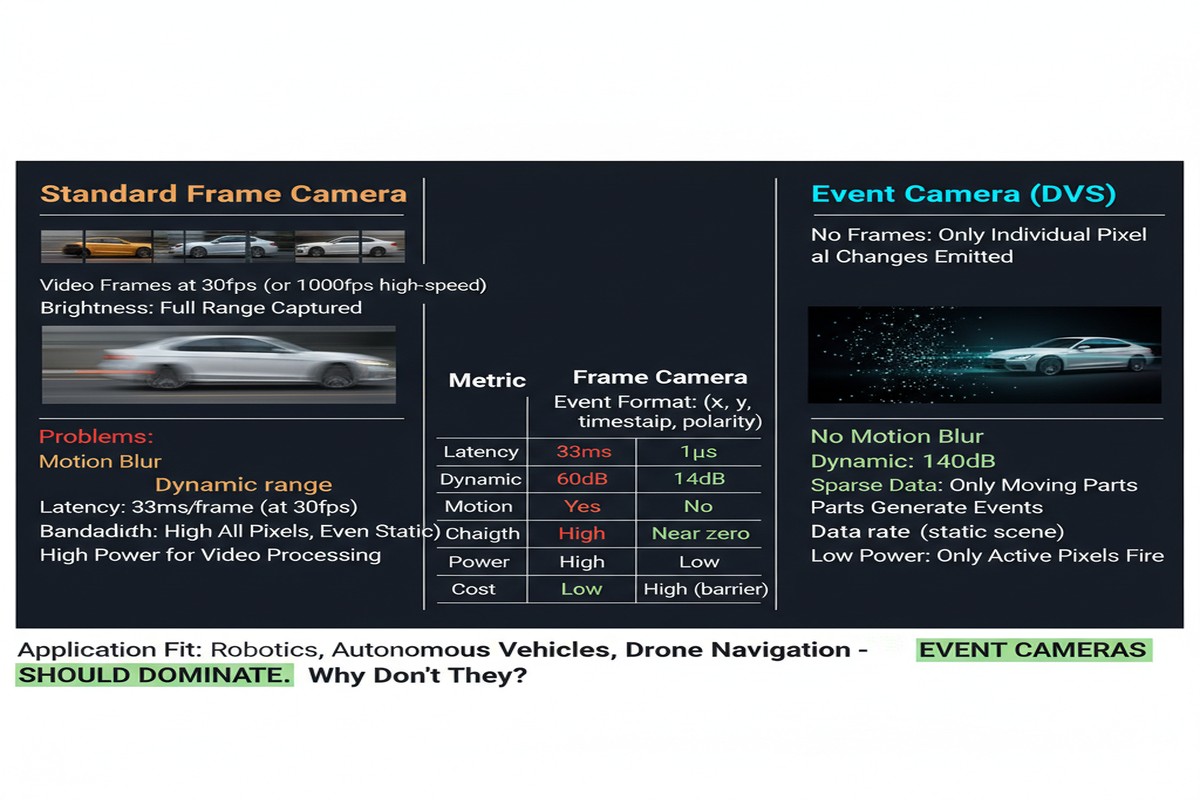
The fundamental operating principle is worth restating because it is genuinely different from anything in conventional imaging. In a frame-based camera, every pixel is read out at a fixed clock rate regardless of whether anything in the scene changed. In a dynamic vision sensor (DVS), each pixel operates independently. When the log-luminance at a pixel changes by more than a threshold (positive or negative), that pixel fires an event — a tuple of (x, y, timestamp, polarity) — and remains silent otherwise.
The consequences cascade through the entire signal processing pipeline:
- Temporal resolution: Events are timestamped in microseconds, not milliseconds. A 1 kHz spinning propeller is not a blur — it is a resolvable temporal structure.
- Dynamic range: Because the sensor responds to log-luminance ratios rather than absolute intensity, it handles scenes that would saturate a conventional sensor. 120 dB versus 60 dB for a good frame-based CMOS.
- Bandwidth efficiency: A static scene produces almost no output. A moving scene produces events only at motion boundaries. In many real environments the effective data rate is orders of magnitude lower than the equivalent frame stream.
- Latency: There is no frame accumulation period. The latency from physical event to sensor output is bounded by the pixel's reset time, not by a frame rate.
flowchart LR
subgraph FrameCamera["Frame-Based Camera"]
direction TB
F1[Global Shutter\nat 30fps] --> F2[Full Frame\n8MP pixels]
F2 --> F3[Compress &\nTransmit Frame]
F3 --> F4[Decode &\nProcess Frame]
end
subgraph EventCamera["Neuromorphic Vision Sensor"]
direction TB
E1[Per-Pixel\nLog-Luminance Monitor] --> E2{Change >\nThreshold?}
E2 -->|Yes| E3[Fire Event\nx, y, t, polarity]
E2 -->|No| E4[Silent\nZero Bandwidth]
E3 --> E5[Asynchronous\nEvent Stream]
end
subgraph Comparison["Key Metrics"]
direction TB
M1["Dynamic Range\nFrame: ~60dB\nEvent: ~120dB"]
M2["Latency\nFrame: 1/fps\nEvent: microseconds"]
M3["Data Rate\nFrame: constant\nEvent: scene-adaptive"]
end
FrameCamera --- Comparison
EventCamera --- Comparison
style E4 fill:#1a1a2e,color:#555
style E3 fill:#0f3460,color:#fff
style M1 fill:#16213e,color:#00d4ff
style M2 fill:#16213e,color:#00d4ff
style M3 fill:#16213e,color:#00d4ff
What the Review Covers
The paper organizes its survey into three layers, which is the right decomposition for a field where hardware constraints, algorithmic choices, and application requirements are deeply entangled.
Hardware evolution traces the progression from the original DVS128 (128×128 pixels, 2008) through the DAVIS sensors that combine events and frames, up to current high-resolution sensors like the Prophesee Metavision series and the Sony IMX636. The trajectory is clear: resolution is increasing (640×480 and beyond), pixel pitch is shrinking, and on-chip processing capabilities are appearing. The review is honest that manufacturing complexity and yield challenges keep prices high relative to frame-based sensors of equivalent resolution.
Event-based algorithms is where the paper earns its keep. The three canonical problem classes are optical flow estimation, depth estimation (stereo or monocular), and object recognition. For each, the review traces algorithm families — classical event-to-frame accumulation methods, graph neural network approaches, spiking neural network decoders, and hybrid architectures — and evaluates their performance on standard benchmarks. The finding that struck me most: graph-based methods that treat event streams as point clouds have shown the strongest generalization properties, but they carry significant computational overhead that limits real-time deployment on embedded hardware. SNNs are the natural architectural match for event data but remain harder to train competitively.
Applications covers UAVs, autonomous vehicles, industrial inspection, medical imaging, and human-computer interaction. The pattern across all of these is the same: early adoption by researchers who need the dynamic range or latency properties, followed by slow migration to production because the software ecosystem is immature. The paper documents this gap explicitly, which is more intellectually honest than most survey papers, which tend to present application examples as deployment success stories when most are still lab demonstrations.
The Research Gaps the Paper Identifies
The review identifies several concrete gaps that I think deserve emphasis because they are engineering problems with known paths to solutions, not fundamental physics limitations:
Standardized benchmarks: The event camera community has not converged on a single benchmark suite the way ImageNet standardized visual recognition. Different papers evaluate on different datasets with different metrics, making comparison nearly impossible. This is a social coordination problem, not a technical one.
Noise models and calibration: DVS sensors have non-trivial noise characteristics — spurious events, threshold mismatch across pixels, temperature dependence of thresholds. The algorithms assume cleaner event streams than real hardware produces. Better noise models built into the algorithmic layer would dramatically improve real-world performance.
Fusion architectures: Combining event data with conventional frame data, IMU data, and LiDAR in a principled way is still an open problem. The temporal asynchrony of event cameras makes naive fusion approaches fail in ways that are hard to debug.
Training data scarcity: You cannot train event-based neural networks on ImageNet. Event datasets are small, expensive to collect, and not well-standardized. Simulation bridges help but introduce their own domain gap.
Why This Matters
Autonomous vehicles and drones operate in exactly the conditions where event cameras are most advantageous — fast motion, high dynamic range (think driving from a tunnel into sunlight), and hard latency requirements for collision avoidance. The fact that most commercial autonomous vehicle stacks still use frame-based cameras as the primary visual sensor is not a statement about the physics of event cameras. It is a statement about tooling maturity and the conservatism of safety-critical engineering teams.
That conservatism is rational but it has a cost. A perception system that loses 50ms to frame accumulation latency in a collision avoidance scenario is making a physical choice with life-or-death consequences. The review demonstrates that the algorithmic building blocks for event-based perception now exist for all three core problems — optical flow, depth, and recognition. The remaining work is engineering: standardization, noise handling, and fusion.
My Take
I have been making the case for event cameras in technical talks for years and I consistently get the same objection: "the software isn't ready." This review both validates and challenges that position. The software is further along than most practitioners realize. There are production-grade optical flow algorithms for event data. There are object recognition pipelines that run at real-time rates on embedded hardware. The benchmark coverage is not yet at the level of frame-based vision, but it is not as primitive as the skeptics assume.
What is genuinely missing is system-level integration. Individual algorithmic components exist but connecting them into a robust perception stack — with proper uncertainty quantification, calibration pipelines, failure mode handling, and safety validation — has not been done in a publicly documented way for a non-trivial robotic platform. That is the work that converts a promising sensor into a deployed technology.
My practical recommendation for any team building high-speed robotic systems right now: run an event camera in parallel with your conventional imaging pipeline. Do not replace your existing stack — the risk is too high. But instrument the event data, build the intuition for what it shows you in your specific operating environment, and start developing the fusion architecture. The teams that have this operational familiarity will have a significant advantage when the software ecosystem matures enough that switching becomes low-risk.
The review from Luxembourg is the best single-document starting point I can point you to for understanding where the field is. It is rigorous, comprehensive, and unusually honest about the gap between published results and deployable systems. Required reading.

Paper: "Hardware, Algorithms, and Applications of the Neuromorphic Vision Sensor: A Review" — Claudio Cimarelli, Jose Andres Millan Romera, Holger Voos, Jose Luis Sanchez-Lopez, arXiv:2504.08588, April 2025. Also published in MDPI Sensors 25(19):6208.


