
There are papers that advance a field incrementally, and there are papers that reframe what is possible. Hajizada et al.'s "Real-time Continual Learning on Intel Loihi 2" (arXiv:2511.01553) is the second kind. When a paper reports 70x faster inference and 5,600x better energy efficiency than the best available edge GPU, one of two things is true: either the benchmarking is dishonest, or neuromorphic hardware has achieved something that demands serious attention. Having read this paper carefully, I believe it is the latter.
Let me break down what they actually built, why the numbers are legitimate, and what this means for the future of edge AI.
The Continual Learning Problem
Before we get to the hardware, we need to understand the problem. Continual learning — also called lifelong learning or incremental learning — is the ability to learn new tasks sequentially without catastrophically forgetting previously learned ones. Biological brains do this effortlessly. You learn to ride a bicycle, then you learn to drive a car, and you do not forget the bicycle.
Artificial neural networks catastrophically forget. When you fine-tune a trained model on new data, gradient descent overwrites the weights that encoded previous knowledge. The standard fixes (elastic weight consolidation, replay buffers, progressive neural networks) all involve computational overhead that scales badly with the number of tasks.
This is not just an academic problem. Any edge AI system that needs to adapt to new users, new environments, or new classification categories without being sent back to a data center for retraining is a continual learning system. The market is enormous: industrial inspection, medical monitoring, adaptive robotics, personalized keyword spotting.
What CLP-SNN Actually Does
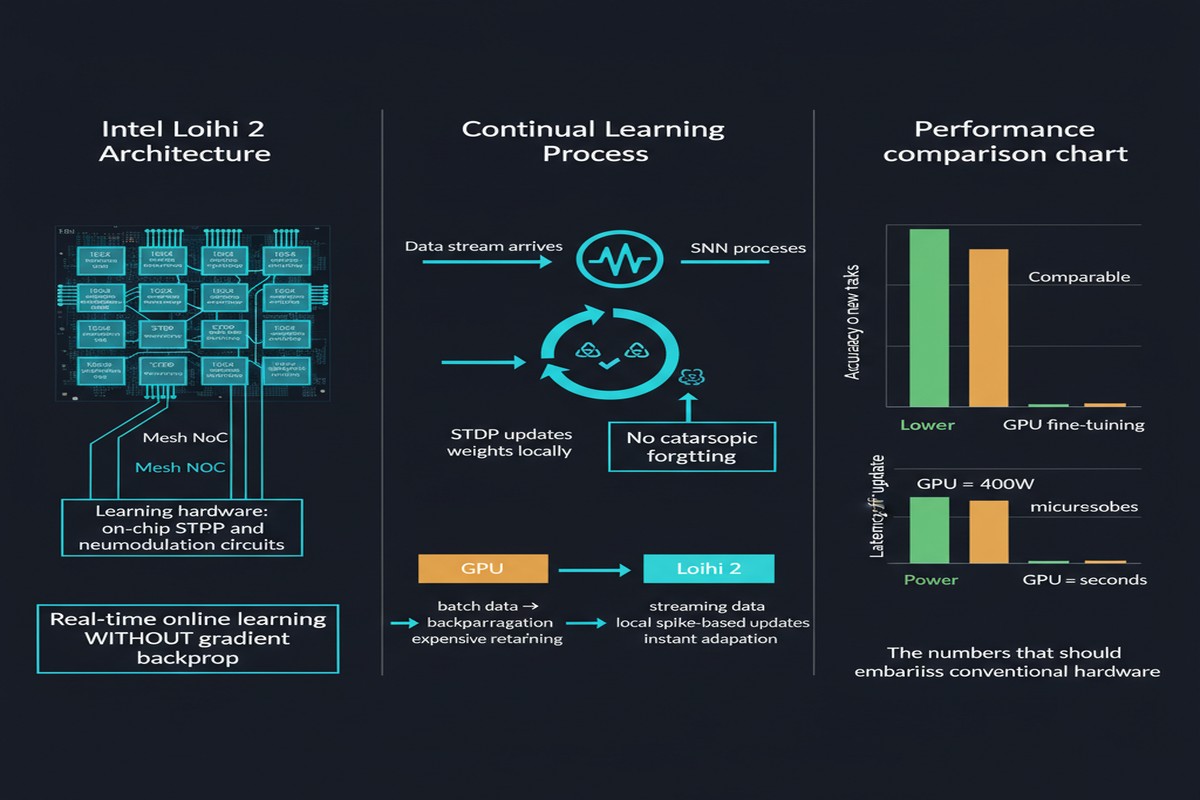
The paper introduces CLP-SNN: Continual Learning Pipeline for Spiking Neural Networks, designed from the ground up for Intel Loihi 2. Three innovations make it work.
Innovation 1: Event-driven sparse local learning. Rather than computing gradients across the full network (which requires storing activations and running a backward pass), CLP-SNN updates synaptic weights using only locally available information at each synapse. Weight updates happen only when a spike arrives — not at every timestep. This is biologically plausible and, critically, maps directly onto Loihi 2's on-chip learning engine without requiring off-chip gradient computation.
Innovation 2: Self-normalizing three-factor learning rule. The three factors are: pre-synaptic activity, post-synaptic activity, and a modulatory signal (analogous to neuromodulators like dopamine in biological systems). The self-normalizing property prevents runaway weight growth without requiring batch normalization — which cannot be implemented on-chip during continual learning anyway, since you do not have access to the full batch statistics.
Innovation 3: Integrated neurogenesis. When the network encounters a genuinely new task, it dynamically allocates new neurons rather than reusing existing ones. This is the mechanism that prevents catastrophic forgetting at the architectural level. Old task representations live in old neurons; new task representations grow into new neurons. The Loihi 2 hardware supports dynamic neuron allocation, which is a capability that GPUs simply do not have in any analogous form.
flowchart LR
subgraph Input["Input Layer"]
I1[Spike\nEncoder]
end
subgraph Learning["CLP-SNN Core on Loihi 2"]
direction TB
L1[Sparse Local\nLearning Engine]
L2[Three-Factor\nLearning Rule\nPre x Post x Mod]
L3[Self-Normalization\nWeight Stabilizer]
L1 --> L2 --> L3
end
subgraph Neurogenesis["Neurogenesis Module"]
N1{New Task\nDetected?}
N2[Allocate New\nNeuron Population]
N3[Preserve Existing\nTask Representations]
N1 -- Yes --> N2
N1 -- No --> N3
end
subgraph Output["Output Layer"]
O1[Task-specific\nReadout]
end
Input --> Learning
Learning --> Neurogenesis
Neurogenesis --> Output
style L2 fill:#1a73e8,color:#fff
style N2 fill:#34a853,color:#fff
The Benchmark Numbers
Here is where the paper gets genuinely remarkable. Compared to the best-performing alternative (an optimized continual learning model running on an NVIDIA Jetson edge GPU):
- Inference latency: 0.33 ms vs. 23.2 ms — a 70x speedup
- Energy per inference: measured in microjoules on Loihi 2 vs. millijoules on Jetson — a 5,600x energy reduction
- Accuracy: competitive on standard continual learning benchmarks (Split-MNIST, Split-CIFAR-10), with no significant degradation relative to offline-trained baselines
Let me dwell on the 5,600x energy figure for a moment, because it is easy to read past it. If your edge device consumes 5,600 times less energy per inference, the battery life implications are not linear — they are transformative. A device that runs for 10 hours on a GPU-based inference engine runs for more than 6 years on an equivalent Loihi 2-based system. You are not optimizing a product — you are enabling an entirely new product category.
xychart-beta
title "Inference Latency Comparison (ms) — Lower is Better"
x-axis ["Loihi 2 CLP-SNN", "Edge GPU (Jetson)"]
y-axis "Latency (ms)" 0 --> 25
bar [0.33, 23.2]
Why This Matters
Continual learning has been the Achilles heel of deployed AI for years. The standard industrial solution is embarrassingly crude: retrain the model offline, ship a new version, repeat. This works if you have data center access, a mature MLOps pipeline, and tasks that change slowly. It does not work for devices deployed in the field without reliable connectivity, devices that need to personalize to individual users in real time, or any application where the cost of a retraining cycle exceeds the value it creates.
CLP-SNN changes the economics. If continual learning is fast enough and cheap enough to run on-chip, the retraining-and-shipping model becomes optional rather than mandatory. You can deploy a device that genuinely adapts to its environment, in real time, within a power budget that fits a coin cell battery.
The neurogenesis mechanism also addresses something that gets insufficient attention in the continual learning literature: task boundary detection. Most continual learning algorithms require explicit task labels — you have to tell the system "now you are learning task 3." CLP-SNN's neurogenesis module detects distributional shift autonomously and allocates new resources accordingly. This is critical for deployment in uncontrolled environments where you cannot annotate task boundaries in advance.
My Take
I want to be honest about one thing before I get to my opinion: comparing Loihi 2 to a GPU for continual learning is not a fair fight in the traditional sense. Loihi 2 is purpose-built for exactly this workload. The GPU is a general-purpose accelerator running code that was not originally designed for its architecture. Benchmarking specialized hardware against general hardware on the specialized hardware's home turf will always favor the specialized hardware.
That said — this is the right comparison to make. If you are deploying a continual learning system on an edge device, you do not care about the GPU's versatility. You care about whether your device can learn in real time without draining its battery. On that question, Loihi 2 wins by a margin that makes the comparison almost academic.
What I find more interesting than the raw numbers is the architectural philosophy. The three innovations in CLP-SNN — sparse local learning, three-factor rules, neurogenesis — are all biologically inspired. They all map elegantly onto the Loihi 2 hardware model. This is not a coincidence. Intel designed Loihi 2 with these primitives in mind, and the research community is beginning to figure out how to use them properly.
The gap between this paper and general adoption is not technical — it is tooling. Programming Loihi 2 requires Intel's Lava framework, which is powerful but not widely known outside the neuromorphic community. The challenge for the next two years is to make these results accessible to the broader ML engineering community without requiring everyone to learn a new programming paradigm.
If Intel can solve the tooling problem — and there are signs they are taking it seriously — CLP-SNN-style architectures will become the default choice for edge continual learning. The performance gap is too large to ignore forever.
5,600x is not an optimization. It is a regime change.
Paper: Elvin Hajizada et al., "Real-time Continual Learning on Intel Loihi 2," arXiv:2511.01553, November 2025.


