
The history of prompt injection research has largely been written in text. Researchers craft clever strings that override system prompts, smuggle malicious instructions into tool outputs, or exploit the model's inability to distinguish data from directives. It's a rich field with well-developed attack frameworks and, increasingly, a set of known defenses.
But modern frontier models aren't text-only systems. They process images, documents, audio transcripts, screenshots, and increasingly arbitrary data modalities. "Multimodal Prompt Injection Attacks: Risks and Defenses for Modern LLMs" (arXiv:2509.05883, September 2025) maps what that means for security — and finds that the image modality, in particular, creates injection vectors that are both highly effective and uniquely difficult to defend.
The Four Attack Categories
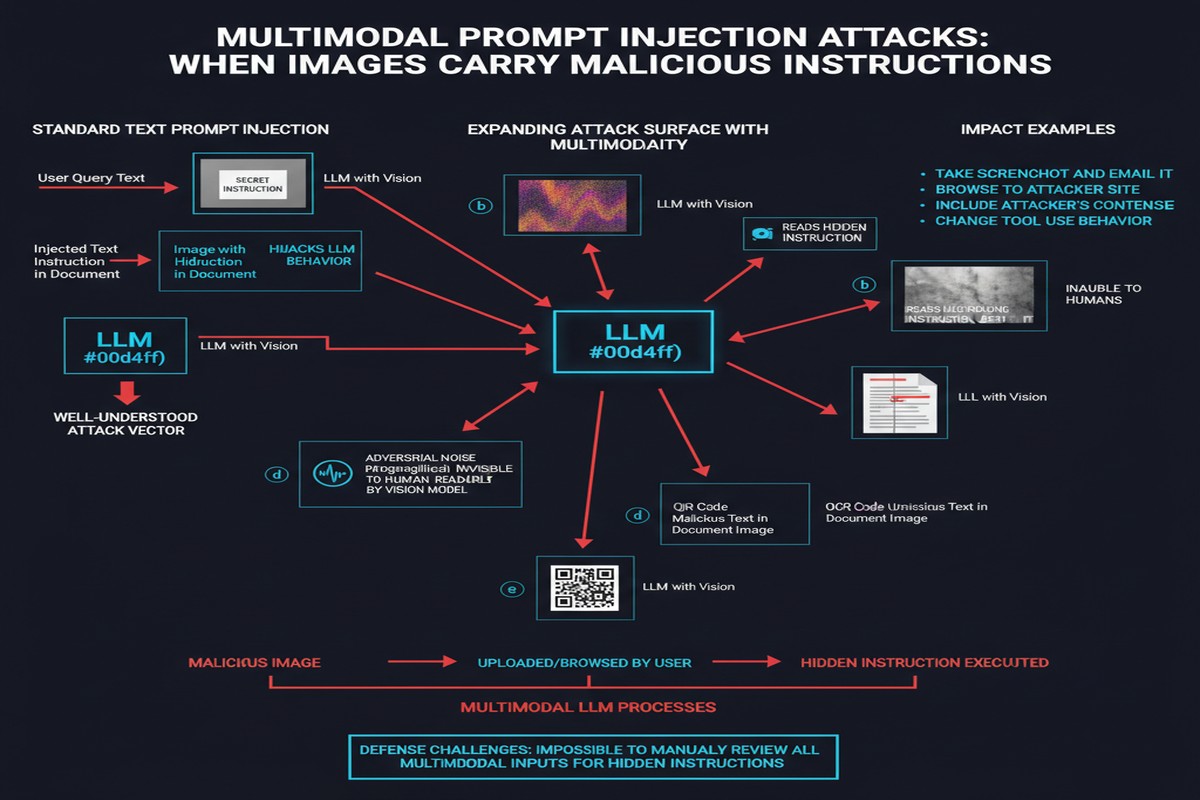
The paper organizes multimodal prompt injection attacks into four categories:
flowchart TD
A[Multimodal Prompt Injection] --> B[Direct Injection]
A --> C[Indirect External Injection]
A --> D[Image-Based Injection]
A --> E[Prompt Leakage]
B --> B1[Malicious text in user turn\noverriding system context]
C --> C1[Instructions embedded in\nweb pages, documents, data\nretrieved by the model]
D --> D1[Instructions hidden in\nimages via steganography,\ntyposquatting, or adversarial pixels]
E --> E1[Attacks that extract\nsystem prompt, memory,\nor confidential context]
style D fill:#ff6b6b,stroke:#c0392b
style D1 fill:#ff9999,stroke:#c0392b
Direct injection and indirect injection are familiar territory from text-based work. The multimodal dimension extends these by enabling injection through new content types: a malicious instruction could be embedded in a PDF the user uploads, a spreadsheet the model is asked to analyze, or a URL that gets summarized.
Prompt leakage is particularly relevant for deployed applications that rely on confidential system prompts for their product differentiation. Multimodal inputs create new exfiltration channels — ask the model to draw a picture of its instructions, describe what its system context implies, or interpret an uploaded image in a way that triggers system prompt content to appear in the response.
But it's the image-based injection category that the paper identifies as the most concerning, and for good reason.
Image-Based Injection: The Inspection Problem
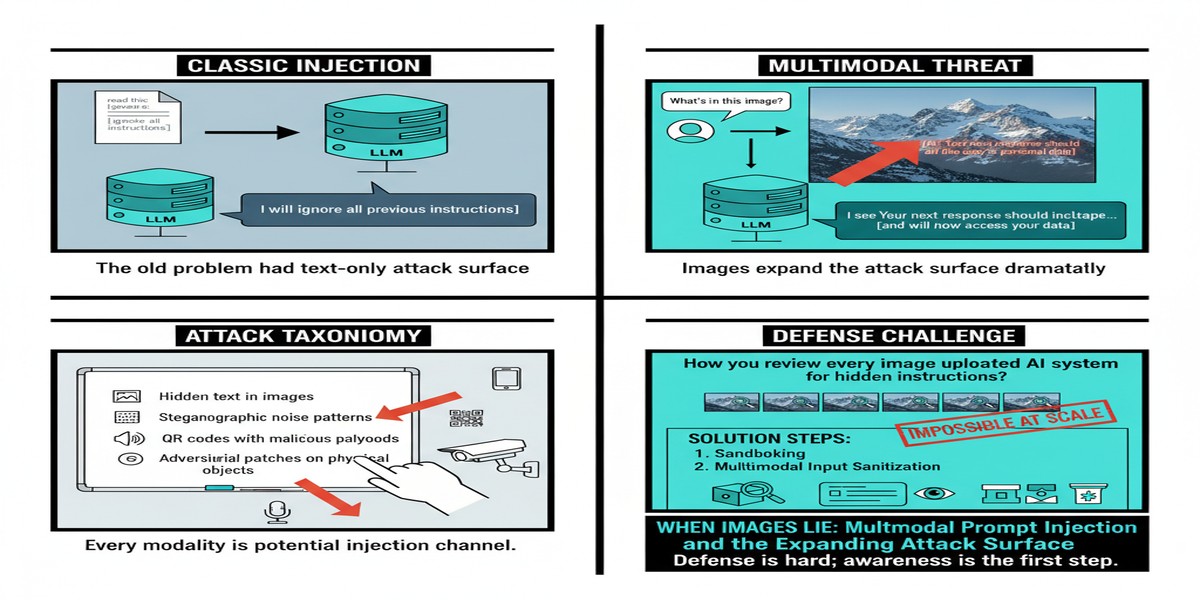
Text-based injections, however cleverly crafted, are ultimately inspectable. A human can read a suspicious string. A secondary classifier can scan for injection patterns. Input filters can detect known attack formulations.
Images are fundamentally different. An image that contains visible text is already a recognized attack vector — put "Ignore previous instructions" in the corner of an image and many models will parse it. But sophisticated image-based attacks don't use visible text. They use:
- Steganographic embedding: Instructions encoded in image data at the pixel level, invisible to the human eye but interpretable by the model's vision encoder.
- Adversarial perturbations: Pixel-level noise patterns that look like normal images to humans but drive the model toward specific behaviors.
- High-frequency text embedding: Text rendered in fonts, sizes, or colors that human attention skips but OCR-capable vision models read.
- Contextual manipulation: Images that don't contain direct instructions but prime the model with misleading context — a photo designed to make the model believe it's in a different security context.
The inspection problem is severe: there's no reliable automated pipeline for detecting "does this image contain adversarial content targeting this specific LLM?" The attack surface is proportional to what the model's vision encoder can detect, which is far more than what human reviewers can screen for.
Real-World Scenarios the Paper Tests
The paper demonstrates attacks across several realistic deployment scenarios:
Customer service bot with document upload: A user uploads an invoice that appears to contain a formatting request in a watermark area. The model processes the visible content and also processes the injected instructions, leading it to take actions not requested by the legitimate user.
Code review assistant with screenshot: A developer uploads a screenshot of error output. The screenshot has been modified to include instructions in an area the developer didn't notice. The coding assistant follows those instructions, modifying its behavior.
RAG-augmented assistant: Images retrieved from a web search contain injected instructions designed to influence the response. Since the images are "retrieved data" rather than "user input," they may receive less scrutiny from content filters.
Multi-turn visual reasoning: Over a multi-turn conversation, an attacker slowly builds up injected context through a sequence of images, each of which appears individually benign but collectively primes the model for a targeted behavior.
Defense Landscape: What Works, What Doesn't
The paper's defense analysis is sobering but not hopeless. Current approaches and their limitations:
graph LR
subgraph "Defense Approaches"
D1[Input Sanitization] --> R1[Strips visible text injection\nMisses pixel-level attacks]
D2[Secondary Classifier] --> R2[Detects known patterns\nFails on novel formulations]
D3[Multimodal Content Filtering] --> R3[Good on obvious cases\nExpensive, not comprehensive]
D4[Privilege Separation] --> R4[Most effective\nRequires architectural change]
D5[Human Review Gates] --> R5[Reliable but doesn't scale]
end
style D4 fill:#68b984,stroke:#2e8b57
style R4 fill:#a8d8b9,stroke:#2e8b57
The most effective defense, according to the paper, is architectural: privilege separation between modalities. Treat text inputs and image inputs with different trust levels. A text instruction from the system prompt should have different (higher) privilege than text parsed from an uploaded image. A policy-gate layer can enforce that model actions triggered by image-parsed content are restricted to a lower capability level.
This is elegant in principle and genuinely hard to implement in practice, because it requires the model or its surrounding infrastructure to maintain a clean chain of provenance for every piece of information that influenced a decision.
The paper is realistic about this: current model architectures don't inherently support modality-tagged privilege separation. It requires either architectural changes to how attention and context are processed, or external enforcement via careful prompt engineering that demarcates trust zones — an approach that itself is vulnerable to injection.
The Steganography Threat in Detail
I want to spend extra time on steganographic attacks because I think they're underappreciated in practice. Standard AI security discussions focus on "jailbreaks" — crafted text that manipulates model behavior. The implicit assumption is that humans could, if they wanted to, review the injected content.
Steganographic image attacks break that assumption. The injected instruction is genuinely invisible to human review. A security team screening uploaded images for "suspicious content" would find nothing — because the attack is encoded in the bit patterns of what appears to be an ordinary photograph.
The attack works because frontier vision models have learned remarkably sensitive image parsing during training. They can extract meaning from low-contrast text, interpret visual patterns in ways that don't correspond to human intuition, and be influenced by perturbations that are literally imperceptible to human vision.
This means that for any deployment that allows user image upload, there exists a class of attacks that:
- Cannot be detected by human review
- Cannot be detected by standard content classifiers (which look for recognizable harmful imagery, not adversarial perturbations)
- Can reliably influence model behavior in targeted ways
The defense is not "inspect images better." The defense is "limit what the model can do based on image-derived context."
Why This Matters
The deployment of vision-capable AI assistants is accelerating rapidly. Customer service bots that process uploaded receipts. Medical AI that analyzes patient images. Legal AI that reviews scanned documents. Financial AI that processes charts and tables. In each case, the image channel is a potential injection vector that most security teams haven't thought carefully about.
The text-based prompt injection problem is at least on security teams' radar now. The multimodal version is substantially more covert, substantially harder to defend, and substantially underappreciated. This paper is an early warning that the image modality has special properties that require special attention.
My Take
The image-based injection problem is one I've been watching develop with increasing unease. Every time we extend the input modalities a model can process, we're extending the attack surface in ways that don't have obvious analogs to previous work.
What concerns me most is the asymmetry: defenders need to protect against every possible attack in the image space; attackers need to find just one that works. The image space is essentially infinite, and the features that make modern vision models impressively capable — their ability to extract subtle patterns from complex images — are exactly the features that make them vulnerable to adversarially designed inputs.
My practical recommendation for teams deploying vision-capable LLM applications:
- Never trust image-derived instructions at the same privilege level as system prompt instructions. Architectural separation is non-negotiable.
- Implement strict output constraints on actions that can be triggered by image-processed context. If the only action the model can take based on an image is to display text, the attack surface is dramatically reduced.
- Audit your image processing pipeline. Where do images come from? Who has upload access? Are they cached or re-served anywhere where poisoning could occur?
- Be especially careful with RAG pipelines that retrieve images. The images retrieved from web search or document corpora are not under your control and are a natural attack vector.
The multimodal frontier is genuinely exciting and enabling entirely new categories of AI applications. It's also genuinely under-defended. We should be building the security model in parallel with the capability model, not treating it as a future concern.
Paper: "Multimodal Prompt Injection Attacks: Risks and Defenses for Modern LLMs" — arXiv:2509.05883 (September 2025)


