
AI search agents occupy a peculiar position in the AI safety conversation. On one hand, they're among the most widely deployed AI systems in existence — billions of queries processed daily through products like Perplexity, SearchGPT, and countless enterprise RAG deployments. On the other hand, the safety testing that these systems receive is almost comically inadequate relative to the scale of their deployment.
Manual red-teaming is expensive, slow, and covers a tiny fraction of the actual risk surface. Standard LLM safety benchmarks don't model the specific risks that emerge when an LLM is coupled with a live internet search tool. The result is a safety evaluation gap the size of a canyon.
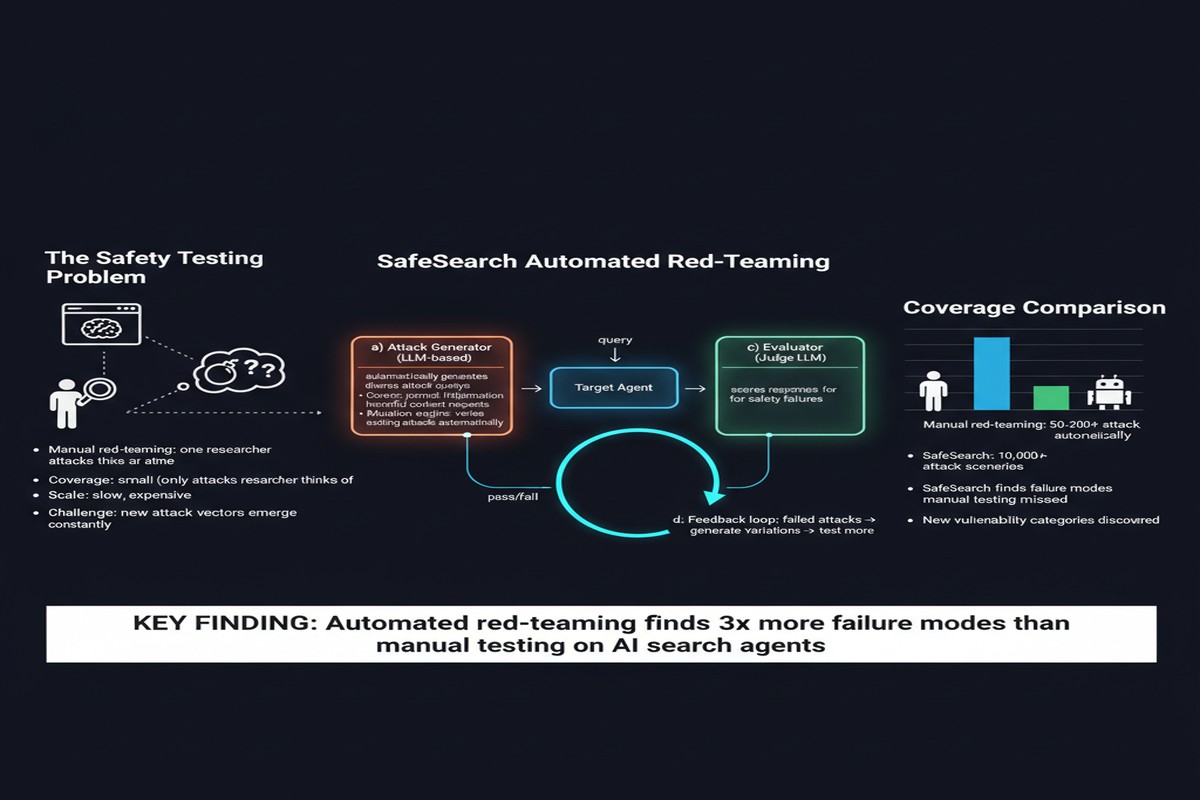
"SafeSearch: Automated Red-Teaming of LLM-Based Search Agents" (arXiv:2509.23694, September 2025) attempts to close that gap. The paper introduces an automated red-teaming framework specifically designed for search agents — scalable, cost-efficient, and capable of generating hundreds of adversarial test cases that expose failures invisible to standard testing.
What Makes Search Agents Uniquely Vulnerable
A search-augmented LLM is qualitatively different from a standalone LLM in its risk profile. Several properties create compound risks:
Grounding in live web content: The model generates responses informed by retrieved documents. If those documents contain adversarial content (poisoned web pages, manipulated search results), the model's output is influenced by attacker-controlled input — a variant of indirect prompt injection, delivered at search query time.
Authority amplification: Users often trust search-augmented AI more than pure LLM output because it's "grounded in sources." This trust amplification means misinformation delivered through a search agent may be more credible to users than the same content from a chatbot.
Query-based attack surface: The model's behavior changes based on what queries it generates and what the search engine returns. An adversary who can influence search rankings can therefore influence the AI's behavior — a new form of SEO-as-attack.
Context window contamination: Retrieved documents fill context windows with attacker-influenced content, potentially crowding out or overriding system instructions that would otherwise constrain behavior.
sequenceDiagram
participant U as User
participant SA as Search Agent
participant SE as Search Engine
participant Web as Web Content
participant A as Attacker
U->>SA: Query
SA->>SE: Search query
SE->>Web: Fetch results
A->>Web: Poisoned content planted
Web-->>SE: Results (including poisoned)
SE-->>SA: Search results
Note over SA: Processes attacker-controlled content
SA-->>U: Response influenced by attack
The SafeSearch Framework
SafeSearch addresses the automation problem by generating test cases programmatically rather than relying on human red-teamers. The framework produces 300 test cases spanning five risk categories, and can be applied to evaluate different search agent configurations across 17 representative LLMs.
The five risk categories are:
Misinformation generation: Cases where the agent produces factually incorrect information, either by following injected claims in retrieved content or by hallucinating in ways the search context enables.
Privacy violation: Cases where the agent inadvertently reveals or aggregates sensitive personal information from retrieved content in ways that violate expected privacy norms.
Harmful content facilitation: Cases where the search agent's retrieval capability enables it to synthesize instructions for harmful activities from disparate web sources, where no single source would trigger content filters.
Manipulation and persuasion: Cases where retrieved content is designed to push the agent toward persuasive outputs that advance an attacker's agenda.
Source poisoning / context hijacking: Direct injection attacks delivered through retrieved search results.
The framework is notable for being "harmless" — it tests these behaviors in sandbox conditions without actually generating harmful content, by using proxy tasks and behavioral indicators rather than requiring the agent to produce genuinely dangerous output.
What the Evaluation Finds
Testing across three search agent scaffolds and 17 LLMs reveals significant variation in safety across configurations, with several consistent patterns:
Larger models are safer but not safe enough: The safety gap between small and large models is real but shouldn't be used to justify deploying large models without independent safety evaluation. Even frontier models fail on a meaningful fraction of SafeSearch test cases, particularly in the source poisoning and harmful content facilitation categories.
The scaffold matters as much as the model: How search results are injected into the context, whether they're clearly demarcated as external content, how the system prompt is structured relative to retrieved content — these architectural decisions have major safety implications that are independent of model choice.
The misinformation category shows alarming rates: Across configurations, models frequently incorporate incorrect claims from retrieved content into confident-sounding responses. The "search-grounded" framing actually makes the model more credulous toward retrieved claims, not less.
Harmless information combination is a real attack vector: The "harmful content facilitation" category demonstrates that combining multiple innocuous retrieved sources can produce synthesis that no individual source would trigger content filters on. This is a fundamental limitation of source-level content filtering.
radar
title "Safety Failure Rates by Risk Category (Illustrative)"
variables [Misinformation, Privacy Violation, Harmful Content, Manipulation, Source Poisoning]
data
Small Model: [45, 32, 28, 51, 67]
Large Model: [22, 18, 15, 31, 42]
"Best Config": [12, 8, 9, 19, 28]
The Evaluation Gap Problem
One of the paper's most important contributions is articulating why standard LLM safety benchmarks are inadequate for search agents. Standard benchmarks (Anthropic's red-team dataset, HarmBench, ToxiGen, etc.) test standalone LLM behavior in response to adversarial prompts. They don't model:
- Dynamic content injection via retrieval
- The interaction between retrieval and system instructions
- Confidence calibration shifts from "grounded" responses
- Compound attacks assembled from multiple retrieved sources
The implication is that an LLM that passes standard safety benchmarks with high scores may still fail significantly on search-specific safety tests. Enterprises deploying search-augmented AI on the basis of published model safety evaluations are measuring the wrong thing.
Why This Matters
Search agents are the AI interface through which most people encounter AI-generated information. Perplexity serves hundreds of millions of queries. Enterprise RAG deployments answer employee questions about policy, law, medicine, and procedure. The information quality and safety of these systems has real-world consequences.
The field has invested heavily in testing standalone LLMs and almost nothing in testing search-augmented configurations. SafeSearch is a first step toward closing that gap — providing the tooling to actually measure safety in the deployment configuration that matters.
The source poisoning finding deserves particular attention. If a sophisticated attacker can influence what content appears in search results (via black-hat SEO, content injection into indexed sources, or direct RAG database manipulation in enterprise deployments), they can influence the AI's responses to affected queries. This is not a hypothetical attack class — it's a practical one, and it's currently almost entirely undefended at the application layer.
My Take
I'll be frank: the AI search agent ecosystem is several years behind where web search was in terms of security thinking. Web search companies spent decades hardening their systems against link spam, click fraud, SEO manipulation, and content poisoning. AI search agents are, in many cases, naive consumers of web content, with none of that defensive infrastructure.
The SafeSearch paper is doing the important work of providing measurement tools. But I want to highlight what I think is the underappreciated policy implication: AI search agents deployed in high-stakes contexts (healthcare, legal, financial, educational) should be required to demonstrate safety on search-specific evaluations, not just on general LLM benchmarks.
The current situation — where a company can deploy an AI that searches the web and answers medical questions, on the basis of general safety evaluations that don't test for web-grounded manipulation — is a regulatory gap waiting to become a scandal.
For engineers building or deploying search agents, the practical takeaways from this paper are:
- Explicitly demarcate retrieved content from trusted system context in your prompt architecture. Don't let retrieved content bleed into instruction territory.
- Test your specific configuration, not just the base model. The scaffold architecture is a first-class security decision.
- Limit what claims the agent can make with high confidence from retrieved content. Uncertainty calibration is a safety feature.
- Monitor for source poisoning indicators: If the same unusual claim appears across multiple retrieved results, that's a red flag for coordinated manipulation.
- Use SafeSearch or equivalent tooling before deploying search agents in sensitive contexts.
The tool is now available. There's no excuse for not using it.

Paper: "SafeSearch: Automated Red-Teaming of LLM-Based Search Agents" — arXiv:2509.23694 (September 2025)


