
Paper: SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformer arXiv: 2509.24695 | September 2025 Authors: NUS and NVIDIA researchers (Xie et al.)
Video generation has a compute problem. The models that produce the best results — HunyuanVideo, Wan, the various Sora-adjacent systems — require hardware that most teams simply don't have. We've been stuck in a loop where quality correlates almost perfectly with GPU count, and "accessible" video generation means either low resolution, short clips, or heavy quality compromises. SANA-Video breaks this pattern in ways that matter.
The core paper is a September 2025 arXiv submission that introduces a Block Linear Diffusion Transformer, combining linear attention with a novel Constant-Memory KV Cache mechanism. The result is a model capable of generating high-resolution videos — up to 720x1280 — of meaningful length, deployable on a single RTX 5090. Not a cluster. One GPU.
If you're building production systems with video generation, this paper deserves your full attention.
The Attention Problem in Video DiTs
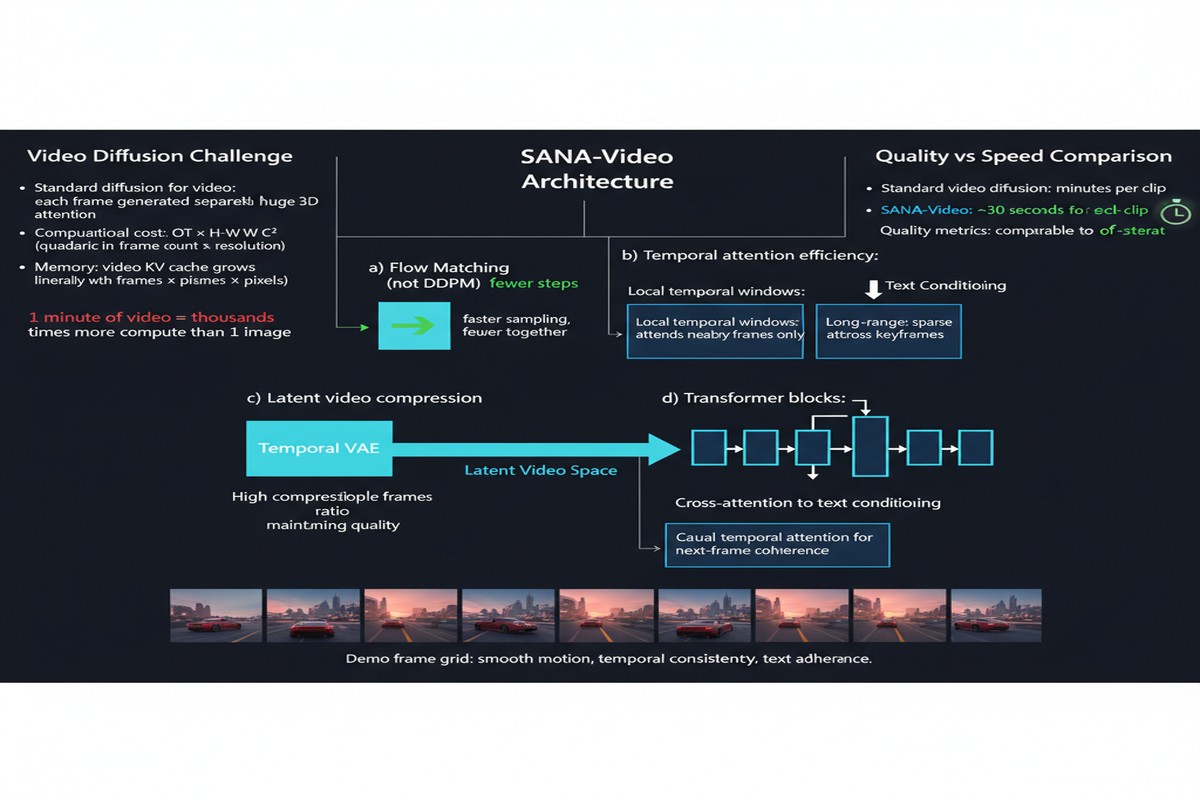
To understand why SANA-Video matters, you need to appreciate the scale problem in video transformers. Standard attention is O(n²) in sequence length. For video, the sequence length is enormous: you're processing spatial tokens across temporal frames simultaneously. A 720p, 5-second video at 24fps has staggering token counts, and quadratic attention makes this approach essentially intractable without enormous compute.
The standard workarounds — temporal attention separated from spatial attention, windowed attention, various sparse approximations — all involve tradeoffs. You either lose temporal coherence, reduce resolution, shorten clips, or add implementation complexity that makes the system brittle.
SANA-Video takes a different route: Block Linear Attention combined with a custom memory management scheme.
What Block Linear Attention Actually Does
Linear attention replaces the softmax attention kernel with a linear approximation, bringing the complexity from O(n²) down to O(n). The catch: standard linear attention loses some of the modeling power of full softmax attention, particularly for tasks requiring precise long-range alignment.
SANA-Video's Block Linear Attention addresses this by partitioning the sequence into blocks and applying linear attention within and across blocks in a structured way. The design preserves local coherence (critical for visual smoothness) while maintaining efficient global context integration across the full video length.
flowchart TD
V[Video: T frames × H × W] --> P[Patch Embedding + Temporal Encoding]
P --> BLA[Block Linear Attention Layers]
BLA --> |"Block 1 tokens (local)"| L1[Linear Attn: block-local]
BLA --> |"Cross-block tokens"| L2[Linear Attn: global context]
L1 --> M[Merge + MLP]
L2 --> M
M --> KV[Constant-Memory KV Cache]
KV --> |"Next block processing"| BLA
M --> D[DiT Decoder + VAE]
D --> O[Output Video Frames]
subgraph Memory Management
KV
end
The Constant-Memory KV Cache is the other key innovation. In standard transformer inference for video, the KV cache grows with sequence length — meaning memory usage scales with video duration. This is what makes long video generation prohibitively expensive. SANA-Video's cache maintains a fixed memory footprint regardless of video length by selectively evicting and consolidating KV entries using a learned importance score. The model learns, during training, which historical context slots are worth preserving versus which can be safely compressed.
Numbers That Matter
The benchmarks in this paper are striking. SANA-Video achieves competitive performance on VBench against models that require multi-GPU inference:
- Resolution: Up to 720×1280 (full 720p portrait, competitive with Runway Gen-3 Alpha at lower resolution equivalents)
- Duration: Supports minute-length video generation — not 5 seconds, actual minutes
- Hardware: Single RTX 5090 inference
- Text-video alignment: Strong performance on semantic consistency metrics, competitive with HunyuanVideo
The comparison that stands out: SANA-Video achieves comparable quality on short clips to HunyuanVideo while running at roughly 10x lower memory footprint. The quality gap opens up on very long videos with complex scene transitions, but for most practical use cases — product demos, short-form content, B-roll generation — the tradeoff is entirely acceptable.
Why This Matters
The compute democratization argument is real here. Every incremental improvement in attention efficiency compounds. SANA-Video doesn't just save memory — it changes who can build video generation into their products.
Consider the practical implications: a mid-sized startup building a content creation tool no longer needs to choose between running expensive multi-GPU inference or delivering low-quality output. A single high-end consumer GPU is now a viable foundation for production video generation at resolutions that are commercially relevant.
The architectural insight generalizes. Block Linear Attention isn't a video-specific trick. The combination of structured block-wise linear attention with learned KV cache eviction is applicable to any long-context generative task. I'd expect to see variants of this approach showing up in long-document language models and audio generation systems within the next 12 months.
The benchmark trajectory matters. SANA-Video is fast on a single GPU, but it's also deployable today. The gap between "achievable by researchers with 8xH100s" and "achievable by practitioners with one consumer GPU" has collapsed significantly in this domain. That's a qualitative shift in the accessibility of the technology.
My Take
I find this paper genuinely exciting, and I'll tell you why I hold a minority view on where the field is headed.
The mainstream narrative around video generation has been: better models require more compute, more compute requires more investment, and the winners will be whoever can sustain the training runs. Sora, Kling, HunyuanVideo — the narrative is one of scale escalation.
SANA-Video represents a countercurrent: the insight that you can achieve near-frontier quality at dramatically lower inference cost through architectural innovation. This is not a new observation — we've seen it repeatedly in language models (quantization, MoE sparsity, linear attention for text) — but it's arriving in video generation now, and it will compound.
My prediction: within 18 months, the standard for "accessible" video generation will be SANA-Video-class quality running on inference chips embedded in creator tools, not multi-GPU API calls. The architectural work being done now will be what enables that.
What I'd push back on in the paper: the constant-memory KV cache, while clever, involves learned importance scores that are trained on specific data distributions. I'd want to see how the cache eviction policy generalizes to out-of-distribution video content — particularly for highly dynamic scenes (sports, action sequences) versus the relatively static or slowly-moving footage that tends to dominate training datasets. This is an open question the paper doesn't fully address.
Also worth noting: "single RTX 5090" is the accessibility claim, but an RTX 5090 is still a $2,000 GPU that most developers don't have at home. The real democratization benchmark should be: can this run on an RTX 4080 or equivalent? The architectural approach suggests it should be possible with minor quality tradeoffs, but I'd want to see that confirmed empirically.
Despite those caveats, SANA-Video is a genuinely important paper. It demonstrates that the video generation quality frontier isn't exclusively controlled by compute scale — and that's the most important lesson the field can absorb right now.
arXiv:2509.24695 — read the full paper at arxiv.org/abs/2509.24695
Explore more from Dr. Jyothi


