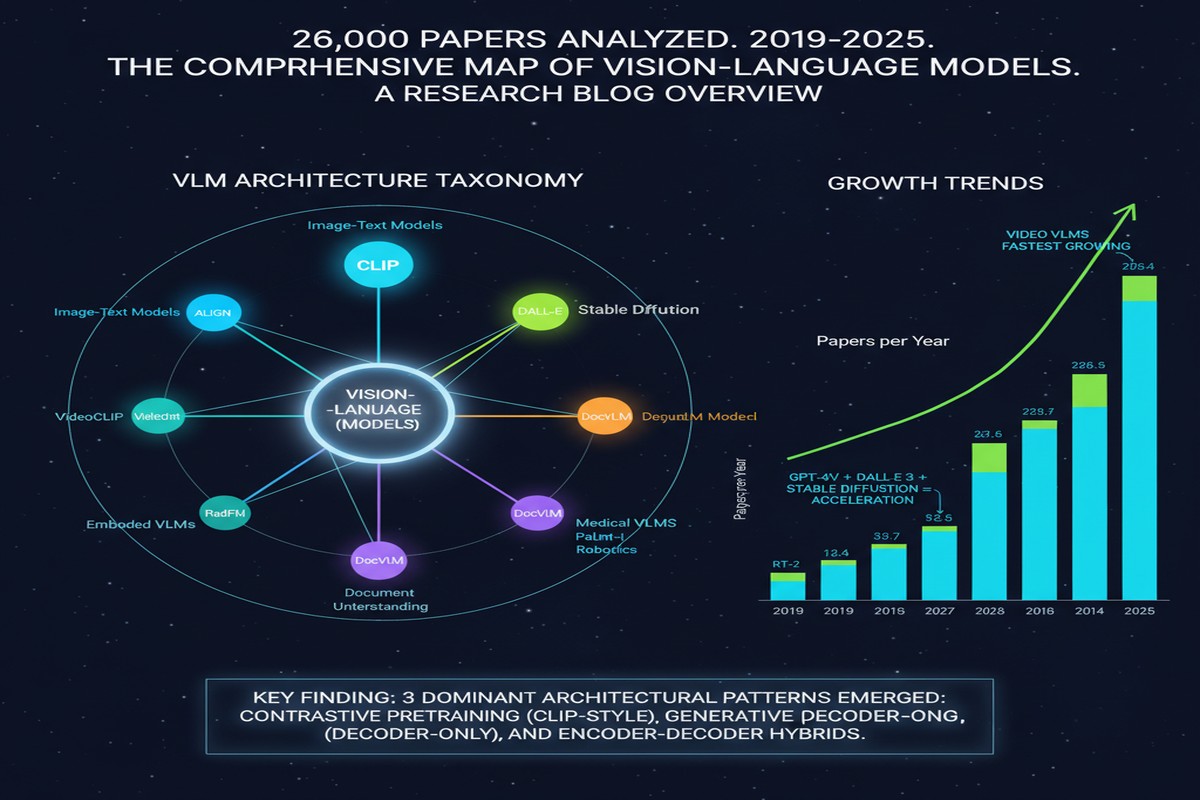
Paper: Vision Language Models: A Survey of 26K Papers arXiv: 2510.09586 | October 2025 Authors: Comprehensive survey team (CVPR, ICLR, NeurIPS meta-analysis)
There is no shortage of survey papers in AI. What there is a shortage of is surveys that actually synthesize at the right level of abstraction — that identify macro shifts rather than just cataloging techniques. The VLM Survey of 26K Papers is one of those rare surveys that earns its length.
Published in October 2025, the paper systematically analyzes 26,104 papers submitted to or published at CVPR, ICLR, and NeurIPS spanning 2023 through 2025. The methodology is rigorous: topic modeling, citation network analysis, and trend identification across one of the densest bodies of research the field has produced. The result is a snapshot of where computer vision and multimodal learning actually are — not where the Twitter discourse says they are.
The three macro shifts it identifies should recalibrate how you think about the field.
The Three Macro Shifts
Shift 1: Vision is being reframed as instruction following
The first and most consequential shift: traditional vision tasks — detection, segmentation, classification — are increasingly being solved not with specialized architectures but as instances of instruction-conditioned generation. The dominant paradigm in 2023 was still specialized backbone + task head. By 2025, the dominant paradigm is multimodal LLM + instruction prompt.
This is not an incremental change. It represents a fundamental reorganization of what a vision "model" is. In the old paradigm, you had a YOLO for detection, a SAM for segmentation, a CLIP for image-text alignment — separate systems for separate tasks. In the new paradigm, you have a single multimodal model that interprets instructions like "find all the cars in this image and describe their relative positions" without task-specific training.
The practical implications are enormous. It means that the skills for building vision systems are converging with the skills for building language systems. It means that the benchmark ecosystem is fragmenting — standard vision benchmarks like COCO and ImageNet measure the wrong things for instruction-following models. And it means that the dataset question has shifted: you don't need labeled bounding boxes anymore; you need instruction-following pairs.
Shift 2: Diffusion is consolidating around controllability, distillation, and speed
In 2023, the diffusion research frontier was about architectural improvement: better noise schedules, improved samplers, higher resolution. By 2025, the frontier has moved. The quality ceiling has been reached or approached for most standard generation tasks, and the research energy is flowing to three specific subproblems:
Controllability: Given a diffusion model that can generate arbitrary images, how do you constrain it to follow specific spatial, semantic, or stylistic constraints? ControlNet variants, adapter-based conditioning, and test-time optimization for conditioning are all active areas.
Distillation: The gap between 50-step and 4-step diffusion quality is closing fast. Consistency models, progressive distillation, and adversarial distillation are producing single-step or few-step models that were unthinkable two years ago.
Speed for deployment: Mobile and edge diffusion is now a serious research area. The paper that SANA-Video (discussed separately) represents — and its predecessors in image diffusion — are directly reflecting this trend.
Shift 3: 3D and video are resilient and Gaussian splatting is consolidating
3D vision was supposed to be disrupted by NeRF, but the disruption didn't fully materialize for production systems — NeRF's training cost and rendering speed made it impractical for most applications. Gaussian splatting has changed this. The survey identifies 3DGS and its variants as the dominant methodology for 3D reconstruction and novel view synthesis in 2025, with NeRF receding from the frontier.
For video, the trajectory is different: video generation has become a flagship application for diffusion transformers, and the research volume on temporal consistency, physics-aware generation, and long-video coherence has accelerated sharply.
graph TD
subgraph 2023 Dominant Paradigms
A1[Specialized Architectures\nYOLO, SAM, CLIP]
A2[Large NeRF Variants]
A3[50-Step Diffusion]
end
subgraph 2025 Dominant Paradigms
B1[Instruction-Following VLMs\nMultimodal LLMs]
B2[Gaussian Splatting Variants]
B3[Distilled Few-Step Diffusion]
end
subgraph Emerging Frontier 2025
C1[Video World Models]
C2[Embodied VLA Models]
C3[Multi-Modal Agents]
end
A1 -->|"Absorbed into"| B1
A2 -->|"Displaced by"| B2
A3 -->|"Distilled to"| B3
B1 --> C1
B1 --> C3
B2 --> C1
B3 --> C2
What the Survey Gets Right
The survey's greatest contribution is its methodological rigor. Analyzing 26,000 papers at a venue-stratified level (CVPR skews applied, NeurIPS skews theoretical, ICLR skews methods) gives a richer picture than any single-venue analysis. The trend identification benefits from the statistical power of the sample — small paper counts can be noise, but when 3,000 papers collectively shift toward instruction-following, that's a real movement.
The observation about benchmark fragmentation is particularly sharp. The survey notes that as vision tasks are reframed as instruction-following, the classic benchmark suite becomes partially obsolete. COCO mAP doesn't measure instruction-following quality. BLEU scores don't capture spatial reasoning. The field is in an awkward transition where researchers are being evaluated on metrics that may not capture what their models are actually good at — or bad at.
The survey also correctly identifies the emergence of Vision-Language-Action (VLA) models as a distinct and rapidly growing subfield, particularly for robotics and autonomous driving. This is an underreported trend in popular coverage but shows up clearly in the paper volume data.
What It Misses
Every survey has blind spots. This one's primary limitation is its venue constraint: CVPR, ICLR, NeurIPS capture a large fraction of the academic frontier but miss the industrial research that increasingly drives the field. The most important vision models in production — the ones powering Google Lens, Meta's AR systems, Apple Vision Pro's scene understanding — are not the subjects of CVPR papers. The academic frontier and the production frontier are diverging, and a venue-based meta-analysis can only show one of them.
The survey also underrepresents work on evaluation methodology — papers that ask "how do we actually measure whether these models are good?" This is arguably the most pressing open problem in the field and doesn't get the coverage it deserves.
My Take
I use this survey as a calibration tool for conversations with engineering teams. When someone tells me they're "getting into computer vision," I ask them which of the three paradigms they're orienting around — the specialized architecture world, the instruction-following VLM world, or the diffusion world. The answer tells me a lot about whether their mental model of the field is current.
The instruction-following shift is the one that matters most for practitioners in 2026. If you're still designing systems where vision is a preprocessing step that outputs a feature vector for a downstream model — stop. The frontier has moved. The architecture that wins across tasks is the multimodal LLM that reasons about images in natural language, not the specialized backbone that outputs bounding boxes.
This shift has a profound implication for how teams should hire and what they should build. The CV-specific skills (backbones, feature pyramids, task-specific losses) are becoming less critical. The multimodal reasoning skills (prompt engineering, instruction dataset curation, evaluation for open-ended generation) are becoming more critical. Organizations that don't recognize this transition are already falling behind.
The Gaussian splatting consolidation is also worth watching. 3DGS is genuinely fast enough for real-time applications and produces reconstruction quality that was previously only achievable with slow offline rendering. As VR, AR, and spatial computing hardware matures, 3DGS-based pipelines will be the foundation for real-world spatial understanding. I'd recommend teams working in this space get familiar with the 3DGS literature now — it moves fast and the pace of improvement is still accelerating.
A survey this comprehensive is a gift to the field. Read it.

arXiv:2510.09586 — read the full paper at arxiv.org/abs/2510.09586
Explore more from Dr. Jyothi