
Paper: Scaling Test-Time Compute to Achieve IOI Gold Medal with Open-Weight Models arXiv: 2510.14232 | October 2025 Authors: Samadi, Ficek, Narenthiran, Jain, Ahmad, Majumdar, Noroozi, Ginsburg (NVIDIA)
The International Olympiad in Informatics is the most demanding algorithmic programming competition in the world. The problems require not just coding proficiency but deep algorithmic insight — often involving obscure mathematical structures, intricate graph algorithms, or dynamic programming formulations that only emerge after hours of careful analysis. Even the best competitive programmers in the world fail on multiple problems.
In October 2025, a team from NVIDIA published a paper showing that an open-weight model with no special training — just a 120B parameter base model with the right inference-time framework — achieved a gold medal at IOI 2025. Final score: 446.75. Gold medal threshold: 438.3.
This result matters far beyond competitive programming. It's a proof-of-concept for what inference-time scaling can accomplish when done systematically.
What GenCluster Does
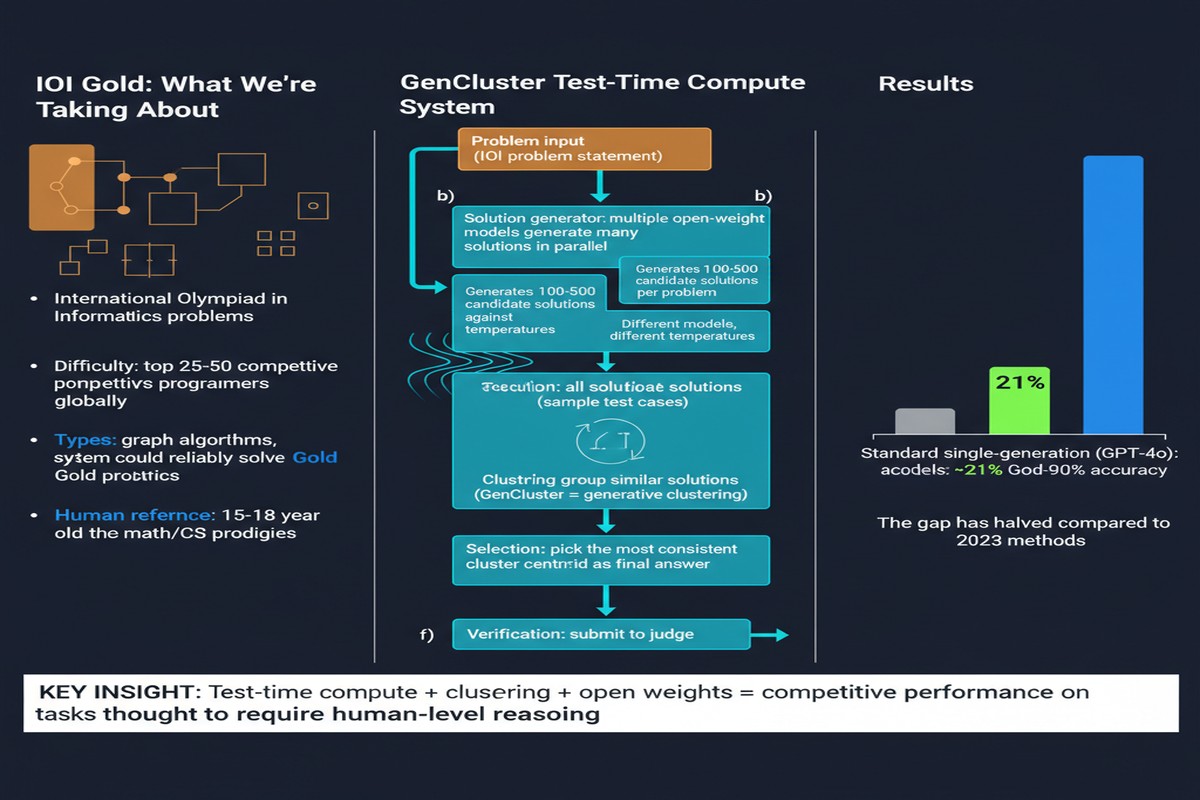
The paper's contribution is a framework called GenCluster. The core insight is to reframe solution search as a statistical sampling problem rather than a single-attempt generation task.
Here's the mental model: instead of asking "can the model produce the correct solution?" you ask "if I generate thousands of candidate solutions, is the probability that at least one is correct high enough?" Then you use the structure of those candidates to identify which ones are most likely to be correct.
GenCluster's pipeline has four stages:
flowchart LR
A[IOI Problem Statement] --> B[Massive Parallel Generation\n1000s of candidate solutions]
B --> C[LLM-Generated Test Cases\nBehavioral test suite]
C --> D[Behavioral Clustering\nGroup by output equivalence]
D --> E[Ranking\nScore clusters by test performance]
E --> F[Round-Robin Submission\nStrategic submission order]
F --> G[IOI Score\n446.75 / 600]
subgraph Clustering Logic
D1[Solution A → Output distribution]
D2[Solution B → Output distribution]
D3[Solutions with same output distribution = same cluster]
D1 --> D3
D2 --> D3
end
Stage 1: Massive parallel generation. For each IOI problem, the model generates thousands of candidate solutions in parallel. Not 10, not 100 — thousands. This is only feasible if you have the inference infrastructure to support it (NVIDIA does), but the principle is hardware-agnostic.
Stage 2: Behavioral test suite generation. The model also generates LLM-created test cases. These are not the official judge's tests — they're synthetic tests created to probe different edge cases of the problem. The quality of these tests is imperfect, but they don't need to be perfect; they need to provide signal that differentiates correct solutions from incorrect ones.
Stage 3: Behavioral clustering. Solutions are run against the synthetic test suite and grouped by their output patterns. Two solutions that produce identical outputs across all test inputs are clustered together, regardless of whether their implementations differ. This is a powerful abstraction: instead of reasoning about code structure (hard), you reason about behavioral equivalence (tractable).
Stage 4: Round-robin submission strategy. IOI allows multiple submissions. GenCluster uses the cluster ranking to select which representatives to submit, optimizing for the maximum expected score under the submission budget. The round-robin strategy ensures coverage across diverse behavioral clusters rather than betting everything on the top-ranked cluster.
The Model: gpt-oss-120b
The base model is an open-weight 120B parameter model (referred to as gpt-oss-120b in the paper — consistent with OpenAI's open model releases). No special fine-tuning for competitive programming. No retrieval augmentation. No chain-of-thought prompting beyond standard instruction formatting.
The point is that the intelligence is in the inference framework, not the model's special training. GenCluster makes a standard strong model into an IOI gold medalist through the way it uses that model at test time.
Why This Matters
Test-time compute is now proven at the hardest verified reasoning task available. IOI is about as hard a verification benchmark as exists. The problems have unambiguous correct answers, multiple approaches are valid, and the difficulty is calibrated to elite human performance. If GenCluster can achieve gold-medal performance here, the principle of inference-time scaling is validated at its most challenging application.
The behavioral clustering idea generalizes. The key insight — group solutions by behavioral outputs rather than code structure — is applicable to any domain where you can generate test cases and run solutions. This includes software engineering, mathematical proof verification, and scientific simulation. The paper focuses on competitive programming but the framework is much broader.
Open-weight models are gold-medal capable. The AI community has sometimes assumed that closed frontier models (GPT-5, Gemini Ultra, Claude Opus) have some qualitative capability advantage on hard reasoning tasks that can't be bridged by architectural or inference-framework improvements. This result complicates that narrative. The bottleneck was not the model's intrinsic capability — it was the inference strategy.
The compute cost is real and must be discussed honestly. Generating thousands of solutions per problem requires substantial inference compute. IOI has 6 problems over two days. Even with efficient batching, this framework requires GPU resources that are not accessible to individuals. This doesn't diminish the result, but the "open-weight democratization" narrative needs to acknowledge that inference efficiency is the next frontier.
My Take
This paper is genuinely exciting, and I'll tell you exactly why I think it's more important than the competitive programming application suggests.
The assumption embedded in most LLM product development is that a model's performance on a task is approximately determined at inference time by the model's weights — that a single forward pass or a short chain-of-thought gives you roughly the maximum quality you'll get from that model. GenCluster demonstrates that this assumption is wrong for hard reasoning tasks. With the right inference strategy, you can extract dramatically more performance from the same underlying weights.
This has direct implications for how I think about building systems. When I advise engineering teams on LLM deployments, I increasingly push them to think about inference strategies, not just model selection. Do you have the infrastructure to run parallel generations and select the best one? Do you have a good way to evaluate candidate outputs automatically? Can you afford the compute cost of sampling more aggressively? These questions should be part of the architecture conversation.
The behavioral clustering methodology is the part I find most reusable. The idea that you can group solutions by input-output behavior rather than code structure is conceptually clean and sidesteps the hardest parts of automated code evaluation. I'd love to see this applied to production debugging scenarios — generating many candidate fixes for a failing test suite and clustering by which test cases they pass.
What I find slightly frustrating is the paper's silence on the energy cost. Generating thousands of solutions per problem on a GPU cluster has a carbon footprint that's worth acknowledging. Inference-time scaling is powerful, but it's not free — the compute is just deferred from training time to inference time. As the community scales these frameworks, we need honest accounting of the tradeoffs.
Still: IOI gold medal with an open-weight model using pure inference scaling. A year ago this would have seemed implausible. Now it's a published result. Pay attention to what that trajectory implies for the next two years.

arXiv:2510.14232 — read the full paper at arxiv.org/abs/2510.14232
Explore more from Dr. Jyothi


