
Paper: The Rapid Growth of AI Foundation Model Usage in Science arXiv: 2511.21739 | November 2025 Authors: Trišović, Fogelson, Sivaloganathan, Thompson (MIT Future Tech)
Most papers about AI adoption in science are written by AI researchers. They count citations to foundation model papers, track benchmark scores, and interview labs that are doing exciting AI-assisted research. The picture they produce is biased toward the frontier — toward the most sophisticated, best-resourced adopters.
This paper does something different. It measures actual usage of foundation models in science: not citations, not surveys, but direct evidence of foundation model deployment in scientific code, pipelines, and research outputs. The result is a significantly more nuanced picture than any narrative I've read from either the AI enthusiasm camp or the AI skepticism camp.
The paper was submitted to MIT Future Tech in November 2025 and represents what I believe is the first systematic empirical attempt to measure the breadth of foundation model adoption across scientific disciplines. It deserves careful reading.
What Was Measured and How
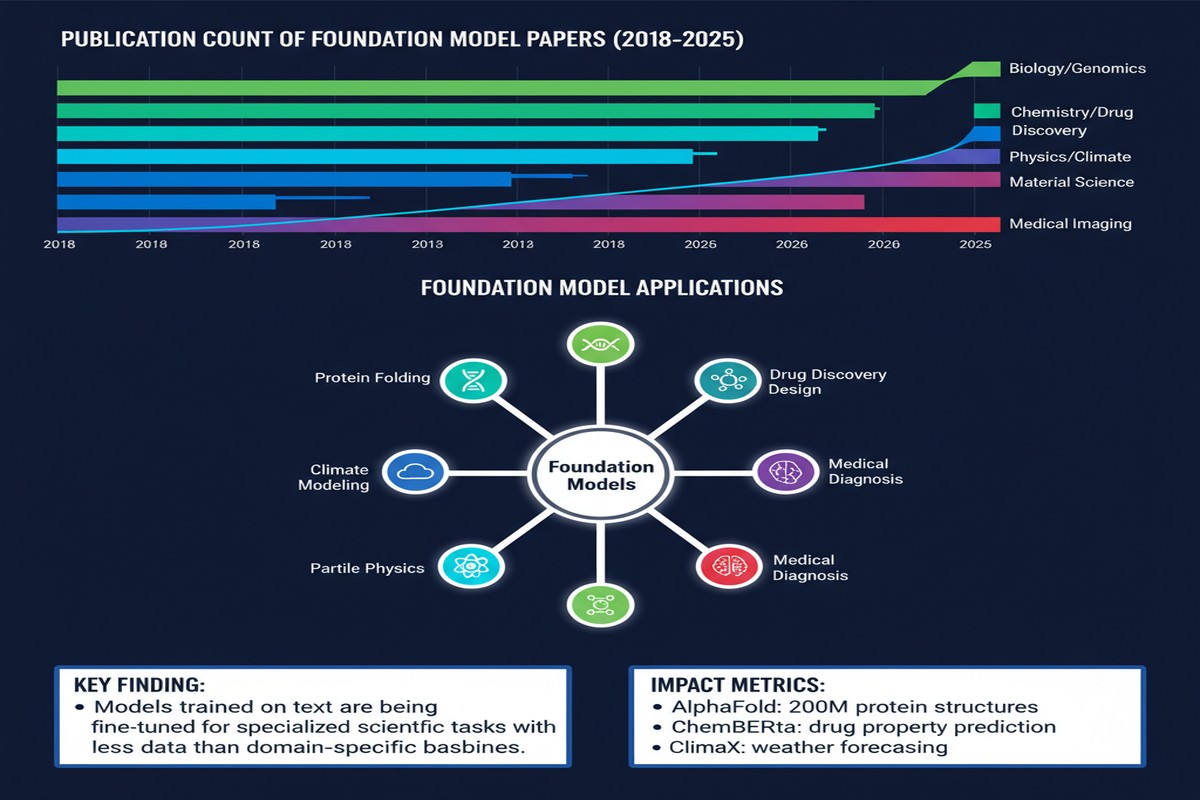
The methodology is worth understanding before diving into the findings, because it shapes how to interpret them. The authors analyzed code repositories, data pipelines, and research artifacts across multiple scientific disciplines — extracting evidence of foundation model usage from actual implementation artifacts rather than self-reported surveys.
This is significantly harder than citation counting but significantly more reliable. A paper that cites CLIP doesn't necessarily use CLIP in the research. A GitHub repository that imports CLIP and calls it with domain-specific data most likely does. The empirical grounding is the paper's key strength.
The coverage spans Linguistics, Computer Science, Engineering, Biology, Physics, Materials Science, Climate Modeling, and adjacent fields.
The Key Findings
Finding 1: Adoption has grown at nearly-exponential rates.
The growth curve is steeper than most people expect. Foundation model usage in science was negligible before 2020, modest in 2021-2022, and exploded from 2023 onwards. The authors describe the growth as "nearly-exponential" — not metaphorically, but based on curve-fitting to the empirical data.
This growth is not evenly distributed. The highest adoption rates are in:
- Linguistics and NLP (unsurprisingly)
- Computer Science (also unsurprising)
- Engineering (the most interesting finding — particularly software engineering research, robotics, and materials engineering)
The lowest adoption is in fields with the most established computational traditions: physics and chemistry. Physicists have their own simulation frameworks (LAMMPS, VASP, Quantum ESPRESSO) that work well and don't obviously benefit from foundation model integration. Chemistry is slightly ahead of physics but still lags the software-adjacent fields dramatically.
Finding 2: Vision models dominate, but language models are catching up fast.
Across all scientific disciplines, vision foundation models (CLIP, ViT variants, DINOv2) are more widely deployed than language foundation models. This is counterintuitive if you follow the popular AI press, which has been fixated on LLMs, but makes sense when you consider that many scientific fields have rich image data — microscopy, satellite imagery, medical imaging, materials characterization — and language processing is less central.
The trajectory matters: language model share is growing fast. The 2025 data shows LLMs closing the gap substantially, driven by adoption in literature review, hypothesis generation, and code generation for scientific pipelines.
Finding 3: Open-weight models dominate over proprietary API access.
Scientists are using open-weight models far more than they're using GPT-4, Claude, or Gemini via API. The reasons are predictable: data sensitivity (you can't send proprietary experimental data to a third-party API), cost (running fine-tuned open models on lab compute is cheaper for high-volume processing), and reproducibility (a hosted model can change; a fixed-weight local model is stable).
The 7B-13B parameter range is the sweet spot for scientific deployment. These models are large enough to be useful, small enough to run on the GPU clusters that research labs actually have.
Finding 4: The parameter gap between frontier and deployed models is growing.
This is the finding I find most interesting and most underreported. In 2013, the median foundation model being built by AI labs was 7.7x larger than the median model being adopted in science. By 2024, this gap had grown to 26x.
xychart-beta
title "Parameter Gap: Frontier vs Scientific Deployment"
x-axis ["2013", "2015", "2017", "2019", "2021", "2023", "2024"]
y-axis "Ratio (frontier/scientific)" 0 --> 30
line [7.7, 8.2, 9.1, 11.3, 15.6, 22.4, 26.0]
The frontier is moving faster than scientific adoption. Labs are building 100B+ parameter models; scientists are deploying 7B-13B models. The gap is not closing — it's widening. This means that the most powerful AI capabilities are not flowing into science as fast as the absolute model capability is growing.
Why This Matters
The adoption data validates the research direction. If you're building AI tools for science — agents, analysis pipelines, literature systems — this paper confirms that your target market is real and growing. Scientists are not resistant to foundation model adoption; they're adopting at near-exponential rates. The question is not whether, but how.
The parameter gap is a product opportunity. The 26x gap between frontier capabilities and scientific deployment represents compressible value. Models that can run on typical research lab hardware (2-4x A100s, not 8x H100 clusters) while capturing meaningful fractions of frontier performance are commercially valuable. Efficient fine-tuning methods (LoRA, QLoRA, adapter-based tuning) are the bridge, and the teams building them for scientific domains have clear addressable markets.
The open-weight dominance is a community responsibility. If scientists are primarily using open-weight models, then the open-source AI community's decisions about what to release, how to license it, and what safety evaluations to publish have direct consequences for scientific practice. Meta's Llama releases, Mistral's model family, and the various LoRA-tuned scientific specializations are not just interesting research — they're infrastructure for global scientific practice.
The field coverage gap is an opportunity. Physics and chemistry are underserved. These are not small, niche fields — they underpin drug discovery, materials science, energy research, and climate science. The gap exists partly because the existing computational ecosystems are mature and foundation model integration is genuinely harder. But the opportunity for someone who can bridge these worlds is substantial.
My Take
This paper is a reality check for both AI enthusiasts and AI skeptics on the science adoption question.
For enthusiasts: the adoption is real, but it's not what the press releases suggest. Scientists are not using GPT-5 to design experiments and write papers. They're using ViT-based models to classify microscopy images and Llama-2-7B to generate code for data processing pipelines. The usage is practical, narrow, and empirically useful — but it's not the AGI-accelerated scientific revolution the breathless coverage implies.
For skeptics: the growth rate is real and it's accelerating. Dismissing foundation model usage in science as "just hype" is contradicted by this data. The adoption is happening at near-exponential rates in field after field, driven by genuine utility — not novelty.
The finding I keep coming back to is the parameter gap. The most capable models available are not the ones being deployed in science. This is partly infrastructure (research labs don't have the compute for 100B+ model inference), partly cost, and partly trust (scientists are appropriately cautious about using black-box proprietary models for research that will be published and need to be reproduced).
If you want to know what "AI for science" actually looks like in practice in 2025 — as opposed to what it looks like in press releases and keynotes — read this paper. The picture is less dramatic and more interesting than the narrative.
arXiv:2511.21739 — read the full paper at arxiv.org/abs/2511.21739
Explore more from Dr. Jyothi


