
Paper: Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls arXiv: 2510.01631 | October 2025 Authors: Research team at scale (large empirical study)
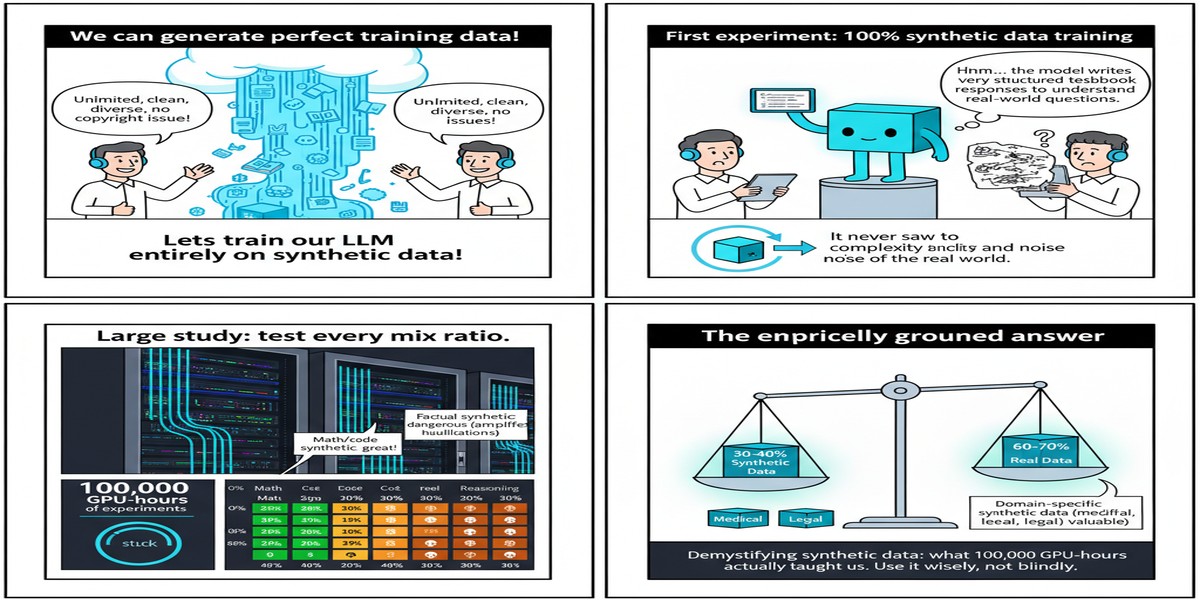
The synthetic data debate in pre-training has been running for years with more heat than light. The proponents argue that generated data can close distribution gaps, provide domain coverage, and scale without annotation cost. The skeptics counter that synthetic data introduces subtle distributional artifacts, risks model collapse, and ultimately can't substitute for the diversity of the real web. Both camps have had cherry-picked results supporting their views.
This paper is different. The authors committed to doing the empirical work that the field has been avoiding: over 1,000 LLMs trained, more than 100,000 GPU-hours burned, across systematic comparisons of natural web data versus diverse synthetic types and their mixtures. This is the kind of study that ends debates — or at least shifts them onto more productive ground.
What Was Actually Tested
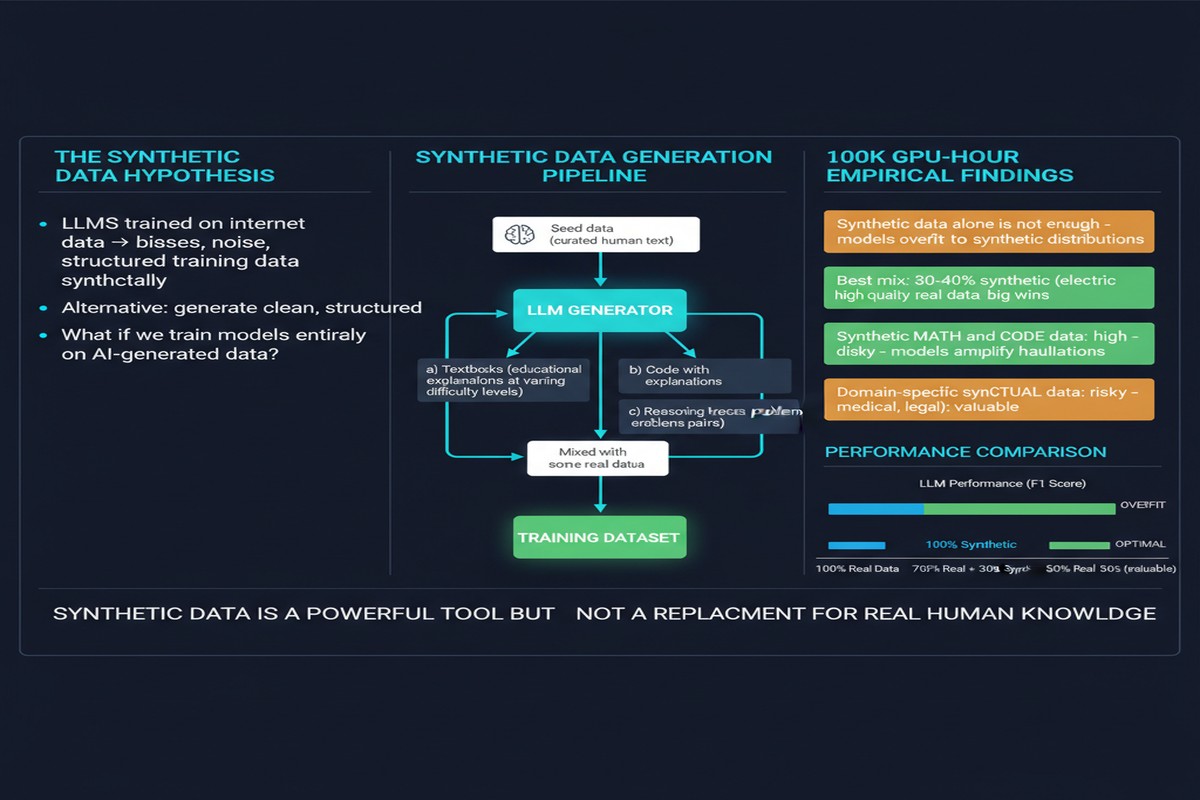
The study compares three fundamental data categories:
- Natural web data: Standard pre-training corpora (C4, CommonCrawl variants, the usual suspects)
- Synthetic data types: Specifically, rephrased text (paraphrases of natural data generated by stronger models) and generated textbooks (domain-structured synthetic text)
- Mixtures: Various ratios of synthetic-to-natural data
The key insight motivating the study is that "synthetic data" is not one thing. Rephrased text preserves the semantic content of natural data while modifying surface form. Generated textbooks are structurally different — they impose an explanatory, structured format that doesn't exist in most web text. Treating these as equivalent is the error most prior work made.
flowchart LR
subgraph Data Types
A[Natural Web Text\nCommonCrawl, C4]
B[Rephrased Text\nLLM paraphrases of web text]
C[Generated Textbooks\nStructured explanatory content]
end
subgraph Training Regimes
D[100% Natural]
E[1/3 Rephrased + 2/3 Natural]
F[1/3 Textbook + 2/3 Natural]
G[100% Synthetic]
end
subgraph Outcomes
H[Baseline Performance]
I[5-10x Faster Convergence]
J[Mixed Quality Gains]
K[Model Collapse Risk]
end
A --> D --> H
B --> E --> I
C --> F --> J
B --> G --> K
C --> G --> K
The Key Findings
Finding 1: 1/3 rephrased synthetic + 2/3 natural web data can accelerate training by 5-10x.
This is the headline result. At larger data budgets, the mixed regime reaches the same validation loss as all-natural training in a fraction of the compute. The mechanism is efficiency: rephrased text removes some of the redundancy in web text (repeated boilerplate, duplicate content, format noise) while preserving semantic diversity. You're getting more unique information per token.
The 5-10x figure is the range across different model sizes and data scales. Smaller models and smaller data budgets see less speedup. The gains compound at scale — which is where it matters most.
Finding 2: Rephrased and textbook synthetics behave very differently.
Generated textbooks improve performance on structured reasoning tasks — math, code, multi-step inference — but the gains don't generalize to general language understanding. You're essentially trading breadth for depth. The model gets better at textbook-like tasks and marginally worse at everything else.
Rephrased text, by contrast, improves broadly without the domain narrowing. This makes it the more versatile synthetic type for general-purpose pre-training.
Finding 3: 100% synthetic training risks model collapse at larger scales.
The study confirms what the theoretical work on model collapse predicted: when models train on their own outputs (or outputs of similar models), the tails of the distribution gradually collapse. The model becomes more confident but less calibrated, and rare patterns in language disappear from the training distribution.
The critical observation: collapse is a large-scale phenomenon. At smaller model sizes and shorter training runs, all-synthetic training can look fine. The degradation is subtle and emerges primarily at scale — which is exactly when it's hardest to detect and most expensive to reverse.
Finding 4: The benefits are data-budget-dependent.
At low data budgets (< 10B tokens), synthetic data provides modest benefits at best. The efficiency gains kick in primarily at larger data scales. This is an important caveat for teams running smaller training runs — synthetic data mixing might not be worth the engineering overhead.
Why This Matters
This paper should change how data strategy conversations happen at AI labs and teams building fine-tuned systems:
The era of "just add more web data" is ending. At the compute scales required for frontier models, the quality of raw web data becomes a bottleneck. Every additional token of cleaned, filtered web text is harder and more expensive to source than the last. Synthetic data — specifically rephrased text at the right mixture ratio — is now a proven tool for compressing that compute cost.
Data curation is becoming ML research. The finding that 1/3 rephrased data is near-optimal is not something you'd derive from first principles. It required systematic empirical work at scale. This suggests that optimal data mixing is a non-obvious, empirically-determined parameter — and teams that don't study it will be at a disadvantage.
The model collapse risk is real and insidious. The collapse behavior appearing at scale is particularly concerning because it creates a false sense of security at smaller scales. Teams running ablations on 7B or 13B models may not see the degradation that emerges at 70B+. This should change how you design data experiments.
My Take
I've been watching the synthetic data discourse for two years, and what frustrates me is how much of it has been conducted at toy scale with results that don't transfer. This paper is the corrective. 1,000+ LLMs and 100k GPU-hours is not a toy study — it's the kind of empirical commitment that the community should have demanded before adopting strong priors either way.
The 1/3 rephrased / 2/3 natural finding is the most actionable result, but I'd urge caution about treating it as a universal constant. The study was conducted on specific base models and data mixtures. The optimal ratio is likely model-family-dependent and may shift with different natural data quality levels. What's transferable is the methodology, not the specific hyperparameter.
The model collapse finding deserves more attention than it's received in coverage of this paper. If you're building training pipelines that generate synthetic data from your own models and then train on those outputs in subsequent generations — a practice that's becoming common in instruction-tuning and alignment pipelines — you're at risk of the very collapse dynamic this paper documents. The mitigations are clear (maintain natural data fraction, monitor tail distribution statistics) but require deliberate engineering.
What I find most valuable about this paper is its honesty about what synthetic data isn't. It's not a free lunch. It doesn't substitute for data diversity. It doesn't solve the domain coverage problem. What it does is compress compute costs for equivalent performance — and at the compute scales being run today, that compression is worth billions of dollars in training cost.
That's a legitimate, important contribution to know precisely. The field owes this paper's authors for doing the study that settles the question — at least for now.
arXiv:2510.01631 — read the full paper at arxiv.org/abs/2510.01631
Explore more from Dr. Jyothi


