
Here's a thought experiment. Your company has been running a Python codebase for four years. It has accumulated technical debt, version-specific quirks, and interdependencies that no single engineer fully understands. You need to migrate it from one major dependency version to another — say, from SQLAlchemy 1.x to 2.x. This involves 47 files, 200+ code changes, and a test suite with 874 tests that all need to pass.
Now ask: what percentage of current AI coding agents can do this?
The answer, according to SWE-EVO, is roughly 21% when using GPT-5 with OpenHands. On simpler, isolated issue-resolution tasks, the same setup achieves 65%. The gap between those numbers is the gap between what AI coding demos show you and what AI coding agents can actually do in production.
Paper: SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios Authors: Minh V. T. Thai, Tue Le, Dung Nguyen Manh, Huy Phan Nhat, Nghi D. Q. Bui Published: arXiv:2512.18470, December 2025 (revised January 2026)
What Software Evolution Actually Looks Like
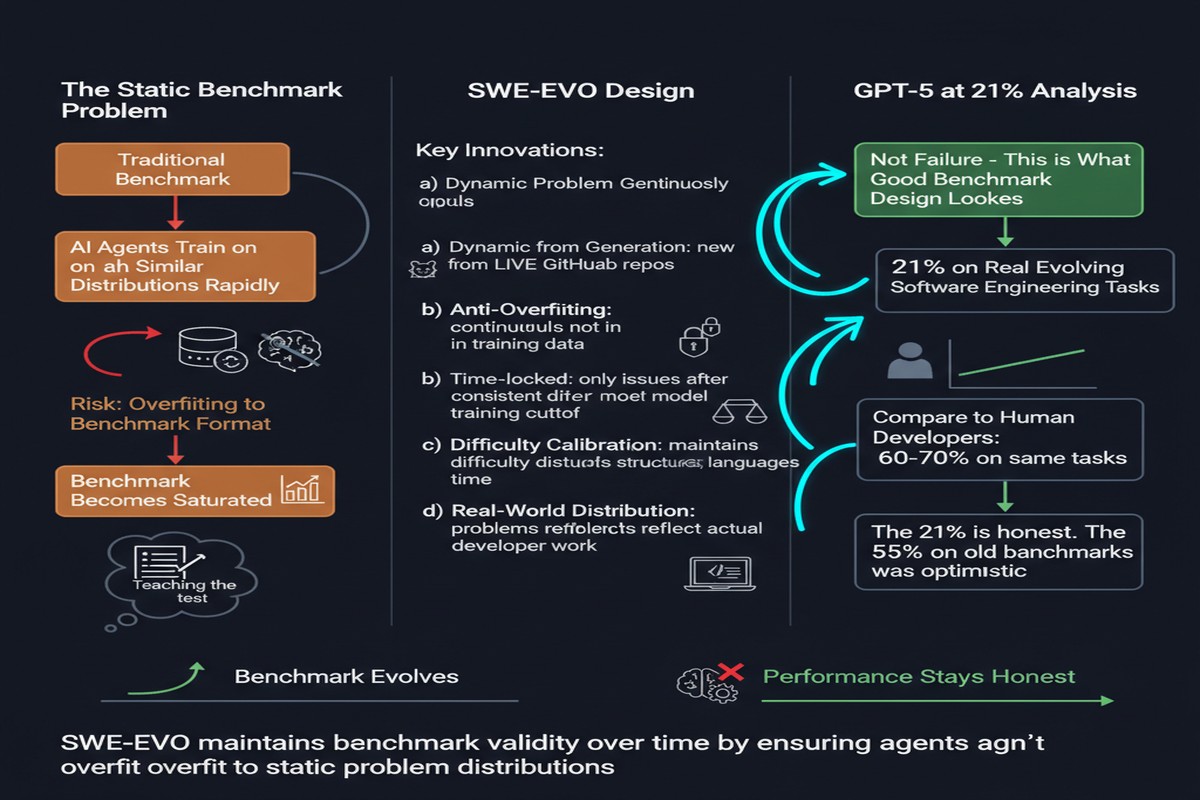
SWE-EVO makes a distinction that should be obvious but has been largely missing from agent benchmarks: the difference between issue resolution and software evolution.
Issue resolution is what SWE-Bench and its successors measure. A user reports a bug or requests a feature. An agent investigates, writes a patch, runs tests, submits. This is a real and important task, and it's good that we benchmark it. But it's a single, bounded event.
Software evolution is different. It happens over time, across versions, in response to accumulating requirements and constraints. A dependency upgrade. A major API redesign. A migration to a new architectural pattern. These involve:
- Understanding the history of design decisions, not just the current state
- Modifying code that was written with different assumptions
- Maintaining compatibility across a multi-version transition period
- Coordinating changes across dozens of files simultaneously
- Running against test suites large enough to catch subtle regressions
flowchart TD
subgraph Issue Resolution Task
IR1[Single bug report] --> IR2[Find the file]
IR2 --> IR3[Write the fix]
IR3 --> IR4[Run tests - usually a small subset]
IR4 --> IR5[Done - 1-3 files typically]
end
subgraph Software Evolution Task
SE1[Version upgrade / major refactor] --> SE2[Understand change scope across codebase]
SE2 --> SE3[Plan multi-file modification strategy]
SE3 --> SE4[Implement changes across avg 21 files]
SE4 --> SE5[Run full test suite - avg 874 tests]
SE5 --> SE6{All pass?}
SE6 -- No --> SE7[Diagnose regressions, revise strategy]
SE7 --> SE3
SE6 -- Yes --> SE8[Done]
end
The benchmark is built from 48 tasks derived from real release notes and version histories of seven Python projects. This grounds it in authentic software evolution work, not synthetic scenarios.
The Numbers in Context
The headline comparison:
- 65% resolution rate on single-issue tasks (GPT-5 + OpenHands)
- 21% resolution rate on software evolution tasks (same setup)
That 44-point gap isn't explained by model capability. GPT-5 hasn't gotten weaker. What's changed is the task structure:
Scale. Evolution tasks involve an average of 21 files, versus 1-3 for typical issue resolution. Agents struggle to maintain coherent reasoning across a change of this scope.
Test coverage. Evolution tasks are validated against test suites averaging 874 tests. Passing 874 tests while modifying 21 files requires a level of systematic verification that current agents lack.
Temporal context. Understanding why code was written a certain way — the historical reasoning behind design decisions — matters enormously for evolution tasks. Agents have no access to this context beyond comments and commit messages.
Cascading effects. Changing a core module affects its consumers in ways that aren't always predictable from static analysis. Agents currently lack the ability to model these cascade effects systematically.
The Fix Rate Metric
One of SWE-EVO's methodological contributions is introducing a Fix Rate metric that measures partial progress. Binary resolution rate (pass/fail) is too coarse for long-horizon tasks: an agent that fixes 18 of 21 files correctly and gets the last 3 wrong achieves 0% by binary resolution but has done substantial useful work.
Fix Rate captures this. It measures the fraction of test cases that pass as a result of the agent's changes, even if the overall task isn't fully resolved. This matters for two reasons:
Research signal. A metric that distinguishes 10% partial success from 90% partial success helps researchers understand what's actually improving.
Production usefulness. In real deployments, an agent that gets you 80% of the way there and hands off a well-documented partial solution is often more valuable than an agent that either completes the task perfectly or fails entirely.
What This Means for the "AI Will Replace Engineers" Narrative
I'm going to be blunt: SWE-EVO should significantly temper the "AI is about to replace software engineers" discourse.
Not because the progress isn't real — it absolutely is. But because the most durable value that engineers create isn't fixing isolated bugs. It's participating in software evolution: making architectural decisions, managing technical debt, navigating version migrations, maintaining codebases that accumulate history.
An agent that can resolve 65% of isolated issues autonomously is useful — genuinely, meaningfully useful for accelerating engineering work. An agent that can participate in software evolution at 21% is a research benchmark result, not a production tool.
The tasks that resist automation longest are the tasks that require understanding context over time: why was this designed this way? What were the constraints that led to this decision? What changed in the world that makes this decision need revisiting? These questions require a form of institutional knowledge that current agents simply don't possess.
Why This Matters
SWE-EVO matters because it's one of the first benchmarks that honestly characterizes what software development actually requires at scale. The field has been measuring the wrong thing — or rather, measuring one slice of a much larger task space.
The paper also highlights something important about the evaluation strategy for coding agents: you need to test against full test suites, not just cherry-picked test cases. An agent that patches code to pass a small number of targeted tests while breaking hundreds of others is not solving the problem; it's gaming the metric. SWE-EVO's 874-test average makes this much harder to game.
The release notes / version history sourcing is particularly clever. It means the tasks are derived from real engineering decisions, not synthetic problems designed to be solvable by agents. That authenticity is what makes the 21% number meaningful and concerning.
My Take
I have genuine respect for this paper's honesty. It would have been easy to design a slightly softer benchmark that produced more impressive numbers. Instead, the authors constructed tasks that reflect what software evolution actually looks like — messy, multi-file, multi-step, with large test coverage — and reported what happened.
What happened is that our best current agents struggle. That's important to know.
The 21% number will improve. The architectural advances needed to crack software evolution tasks — persistent codebase modeling, long-horizon planning with rollback, systematic regression awareness — are well-understood as goals. Papers like this one set the target clearly.
My criticism of the paper is its relatively small benchmark size (48 tasks). Statistical confidence gets shaky with small N, and 48 tasks isn't enough to draw fine-grained conclusions about which task characteristics drive failure. A follow-up with 500+ tasks would be much more useful for understanding failure modes.
But as a directional statement — "here is what software evolution requires, and here is how far current agents are from meeting that bar" — SWE-EVO is invaluable.
If you're building coding agents for production use, test them on evolution scenarios, not just issue resolution. Your users live in the world SWE-EVO is measuring.

Further Reading
- arXiv: 2512.18470
- Related: SWE-Bench Pro (2509.16941) for another hard coding benchmark
- Related: Live-SWE-agent: Can Software Engineering Agents Self-Evolve? (2511.13646)


