
Every few months, a benchmark emerges that forces the field to confront an uncomfortable truth. SWE-Bench Pro is that benchmark for 2025. If you've been nodding along to demos of AI agents "autonomously solving GitHub issues" and thinking we're close to replacing engineering teams, this paper should give you pause — not because progress isn't real, but because the goalposts were in the wrong place.
Paper: SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks? Authors: Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, et al. (20+ authors across multiple institutions) Published: arXiv:2509.16941, September 2025 (revised November 2025)
What the Original SWE-Bench Was Getting Wrong
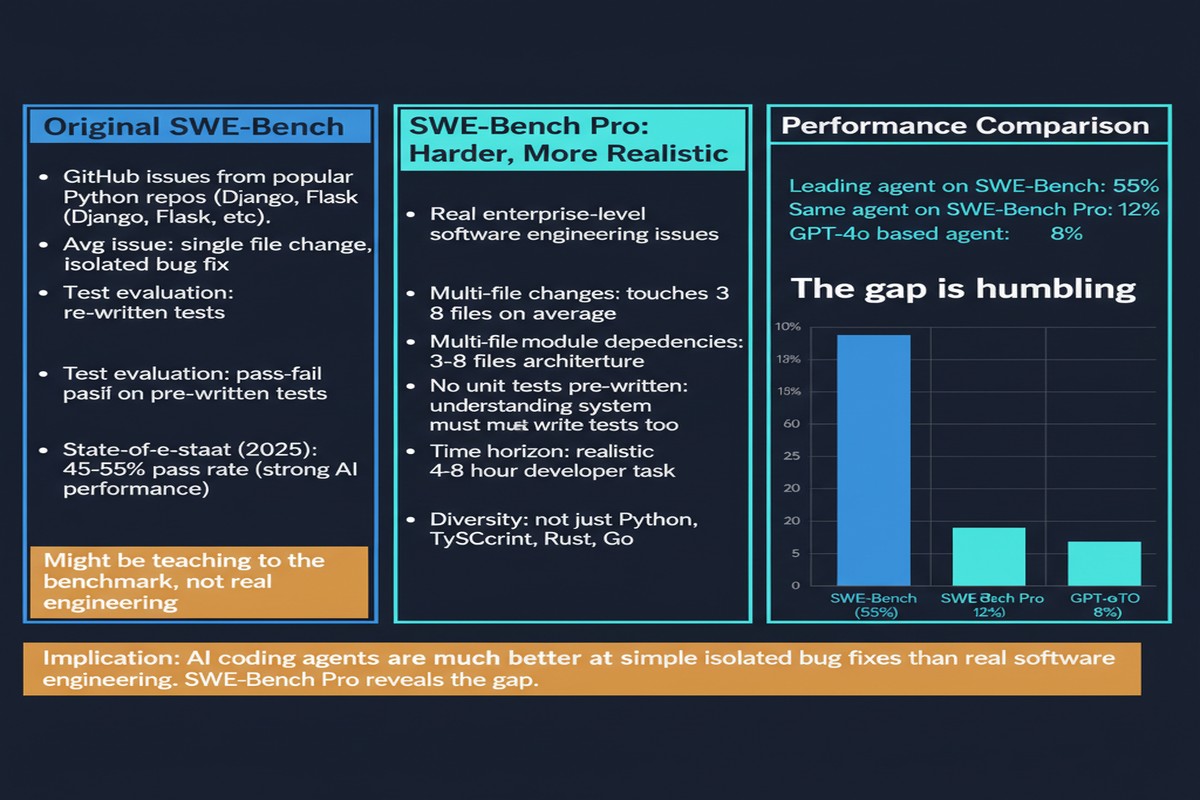
The original SWE-Bench was a genuine achievement when it launched. Real GitHub issues, real codebases, real tests. Watching scores climb from 4% to 50% to 70%+ felt like watching history being made. The problem was the tasks themselves.
Most SWE-Bench Verified problems are what I'd call "isolated issue resolution" — a specific bug, a well-scoped feature, a localized fix. A good human engineer could knock many of these out in under an hour. The benchmark was measuring a real capability, but it wasn't measuring the capability enterprises actually need.
SWE-Bench Pro fixes this. The dataset contains 1,865 tasks sourced from 41 actively maintained repositories, with a strong bias toward enterprise software: business applications, B2B services, developer tools. Crucially, the tasks are explicitly "long-horizon" — the kind that "may require hours to days for a professional software engineer to complete." We're talking about patches that span multiple files, substantial code modifications, and complex interdependencies.
The benchmark is also divided into public, held-out, and proprietary commercial sets, making contamination much harder. That alone should make you skeptical of models that score suspiciously high on public test sets.
The Numbers That Matter
The headline number: top-tier models (the paper mentions Opus-level and GPT-5-class models) achieve roughly 23% on SWE-Bench Pro, compared to 65–70%+ on simpler benchmarks.
That's not a rounding error. That's a different capability class entirely.
graph LR
subgraph Benchmark Comparison
A["SWE-Bench Verified\n(isolated tasks)"] -- "65-70%+ solve rate" --> B["Top AI Agents"]
C["SWE-Bench Pro\n(long-horizon tasks)"] -- "~23% solve rate" --> B
end
B --> D["What the gap reveals"]
D --> E["Multi-file reasoning"]
D --> F["Long-horizon planning"]
D --> G["Sustained context management"]
D --> H["Understanding legacy codebases"]
What's causing the 50-point drop? The paper's failure analysis is worth reading carefully. A few patterns emerge:
Context loss over long trajectories. Agents that maintain state well over 10 steps struggle badly over 50–100 steps. The error compounds.
Multi-file reasoning. Real enterprise tasks touch interconnected modules. Agents trained to find and fix a localized issue often miss cross-cutting concerns.
Ambiguity handling. Production bugs are rarely as cleanly specified as GitHub issues written for a benchmark. Real tasks require inference about intent.
Regression avoidance. Changing one thing and breaking three others is a classic engineering failure. Agents are particularly bad at this.
Why This Matters
I've been saying for two years that the software engineering agent conversation is conflating capability with maturity. SWE-Bench Pro provides the clearest empirical evidence yet for this distinction.
The original benchmark measured whether agents could solve isolated, well-scoped tasks. Impressive, yes. But what enterprises actually need is an agent that can:
- Investigate an intermittent production bug across a 200KLOC codebase
- Implement a feature that touches authentication, billing, and API layers simultaneously
- Refactor a module while maintaining backward compatibility with six consumers
- Add observability to a system without understanding the original architect's intent
These are hours-to-days problems, not hours problems. And at 23%, we're nowhere near production deployment for these use cases without significant human oversight.
The contamination-resistant design also matters enormously. When models are trained on public GitHub data, and your benchmark is sourced from public GitHub repos, you have a leakage problem. The proprietary commercial set in SWE-Bench Pro specifically addresses this.
The Architecture Gap
What's interesting is that the failure modes suggest the problem isn't just model capability — it's agent architecture. The best code agents today are built around fairly simple loop patterns:
flowchart TD
A[Receive task] --> B[Explore codebase]
B --> C[Form hypothesis]
C --> D[Write patch]
D --> E[Run tests]
E --> F{Pass?}
F -- Yes --> G[Submit]
F -- No --> H[Revise hypothesis]
H --> C
G --> I[Done]
This works for isolated tasks. It breaks down for long-horizon tasks because:
- The "explore" phase doesn't build a sufficiently deep mental model of the codebase
- Hypotheses formed early don't account for cascading effects
- The revision loop doesn't capture "what did I learn from this failure?"
What long-horizon software engineering actually requires is something closer to how a senior engineer works: building a rich, persistent model of the codebase that evolves as you learn more, explicitly reasoning about risk and side effects, and maintaining awareness of the full scope of changes needed.
The paper implicitly points at this gap without fully solving it — which is honest. They're measuring a problem, not claiming to have fixed it.
My Take
I'll be direct: I think the 23% number is correct but slightly misleading because it invites the wrong response. The wrong response is "AI coding agents aren't ready." The right response is "AI coding agents are ready for a specific class of tasks, and we need to be rigorous about which class."
A 23% solve rate on hard tasks doesn't mean agents are useless. It means they're roughly at the level of a competent junior engineer on genuinely complex tasks — useful as a first pass, not reliable as an autonomous system. That's still enormously valuable if you structure workflows around that capability level.
What bothers me more than the number is the industry narrative. We have a habit of declaring victory based on benchmark scores that don't represent production conditions, then being surprised when real-world deployment is hard. SWE-Bench Pro is a useful corrective to that.
The paper is also important because it will anchor the next generation of agent architectures. If you're building a code agent, you need to be evaluated on long-horizon tasks, not just isolated issue resolution. The teams working on this benchmark have done the field a genuine service by defining what "hard" actually looks like.
My prediction: the teams that crack 50%+ on SWE-Bench Pro won't do it by making better models — they'll do it by building fundamentally different agent architectures with better codebase modeling, planning, and persistent state. The model is increasingly not the bottleneck. The architecture is.

Further Reading
- arXiv: 2509.16941
- Related: SWE-agent (2405.15793) for the original agent-computer interface work
- Related: Confucius Code Agent (2512.10398) for a system claiming 59% on SWE-Bench Pro


