
When I review production agentic systems, the question that most often goes unanswered is: "How do you know this is working?" Not "does it sometimes produce impressive outputs" — of course it does — but "do you have a rigorous, quantitative understanding of where it succeeds, where it fails, and whether changes you make are improvements or regressions?"
Evaluation is the unglamorous foundation of reliable AI systems. For agents specifically, it is also genuinely hard. Let me explain why, and then offer a framework that actually works.
Why Agent Evaluation is Harder than Model Evaluation
For a classification model, evaluation is conceptually simple: held-out test set, ground truth labels, accuracy/F1/AUC. The model takes an input and produces a single output. You compare the output to the label.
Agents operate differently in ways that break this simple paradigm:
Sequential decision-making: an agent makes many decisions to complete a single task. A wrong decision at step 3 in a 10-step sequence might not manifest as a visible failure until step 7. Traditional accuracy metrics cannot capture this.
Interaction with external systems: agents call tools, retrieve information, and modify external state. The "correct" answer may depend on the current state of these external systems, which changes between evaluation runs.
Long time horizons: some agentic tasks take minutes or hours of compute time and hundreds of tool calls. Evaluating at scale requires efficient infrastructure, not just good metrics.
Sparse feedback: in many agentic tasks, success is binary and feedback is delayed. The agent completes a research report — was it good? You will not know until a human reads it, which may be hours after the run completes.
Distribution shift: agents interact with the world, and the world changes. A tool API changes its response format; a web page is restructured; a database schema is updated. Evaluation sets that were valid last month may not reflect current conditions.
The Evaluation Hierarchy
I think about agent evaluation as a hierarchy with four levels:
Level 1: Unit Tests for Tools and Components
Before evaluating the full agent, test its components in isolation. Every tool should have unit tests that verify:
- The tool produces correct output for valid inputs
- The tool handles invalid inputs gracefully
- The tool's latency is within acceptable bounds
This is basic software engineering, but it is frequently skipped in the rush to get agents working end-to-end. A failing tool is a failing agent. Test your tools.
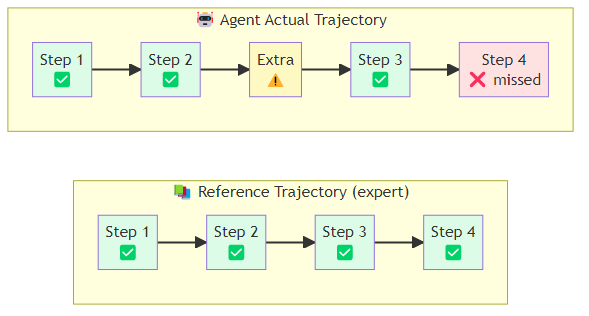
Level 2: Trajectory Evaluation
A trajectory is the sequence of decisions an agent makes to complete a task: the thoughts it generates, the tools it calls, the observations it receives. Trajectory evaluation assesses the quality of this sequence, not just the final output.
Metrics:
- Step efficiency: did the agent complete the task in a reasonable number of steps, or did it take a circuitous path?
- Tool selection accuracy: did the agent call the right tools, with the right arguments?
- Unnecessary actions: did the agent take steps that did not contribute to the goal?
- Error recovery rate: when a tool call failed, did the agent handle it correctly?
Trajectory evaluation requires reference trajectories — human-generated or expert-generated sequences that represent correct solutions. These are expensive to create but invaluable for diagnosis.
Implementing trajectory comparison involves extracting the sequence of tool calls from both the agent's actual run and the reference solution, then computing several metrics against that pair. Step efficiency compares the total number of steps taken to the reference length — a ratio significantly above one indicates the agent took a roundabout path. Tool selection accuracy measures what fraction of the tools used in the reference solution were also called by the agent, capturing whether the agent reached for the right instruments. A sequence-aware F1 score goes further by penalizing cases where the right tools were called but in the wrong order, which matters for tasks where tool calls have dependencies.
Level 3: Outcome Evaluation
Outcome evaluation asks: did the agent accomplish the task? This is the most intuitive metric but the hardest to measure automatically.
For tasks with verifiable outcomes, automated evaluation is possible:
- Code generation: does the generated code pass a test suite? (SWE-bench uses this approach)
- Information retrieval: does the agent's answer contain the correct facts?
- Web navigation: did the agent successfully complete the specified web action? (WebArena, WorkArena)
For tasks with subjective outcomes — report writing, creative tasks, complex analysis — you need either human evaluation (expensive, slow, inconsistent) or LLM-as-judge evaluation (fast, scalable, but with known biases).
LLM-as-judge has become a practical standard for qualitative evaluation. The approach wraps the evaluation itself as a language model call: a judge model receives the original task description, the agent's output, and a scoring rubric that breaks quality into discrete, independently assessed criteria. For each criterion the judge produces a score on a one-to-five scale and a written rationale explaining the score. Structuring the prompt this way — separating the criteria, requiring explicit reasoning per dimension, and specifying the scale — produces substantially more reliable scores than asking for a single holistic rating. The key insight from LMSYS's research on LLM judges: the judge model should be at least as capable as the agent model being evaluated. Using a weaker judge to evaluate a stronger agent produces unreliable scores.
Level 4: End-to-End Benchmark Performance
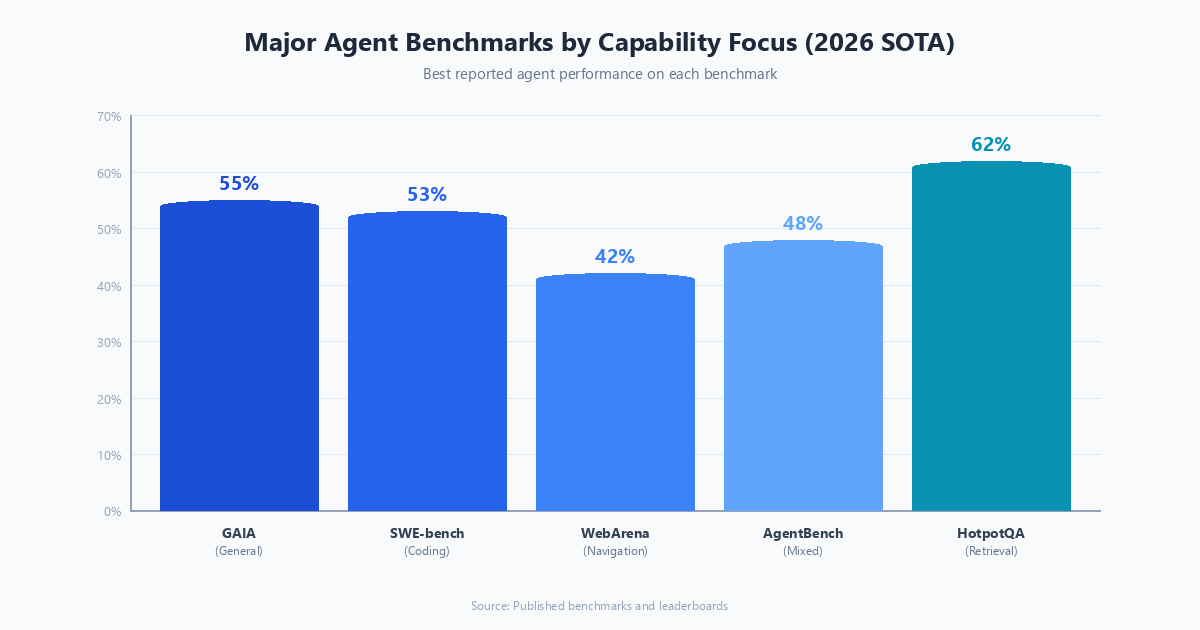
Standardized benchmarks provide a common language for comparing agent systems across the field. The major benchmarks as of 2026:
GAIA (General AI Assistants): real-world tasks requiring web search, file manipulation, and reasoning. Stratified by difficulty. A strong signal of general-purpose agent capability.
SWE-bench: software engineering tasks drawn from real GitHub issues. The agent must analyze a bug report, navigate a codebase, and produce a fix that passes existing tests. SWE-bench Verified is a cleaner version with human-verified task specifications.
WebArena / WorkArena: web-based task completion across realistic web applications (shopping sites, email, project management tools). Tests long-horizon navigation and form-filling.
HotpotQA / MuSiQue: multi-hop question answering requiring chained retrieval and reasoning. Good for evaluating RAG agent quality.
AgentBench: a diverse collection of agent tasks including household tasks, digital card games, database querying, and operating system interaction.
Benchmark performance is informative but not sufficient. Production systems operate on distributions that may differ substantially from benchmark distributions. Use benchmarks to establish baseline capability; use domain-specific evaluation to validate production readiness.
The Evaluation Infrastructure Problem
Even with the right metrics, evaluation at scale requires infrastructure. A thorough agent evaluation run — covering edge cases, failure modes, and regression testing — might require thousands of agent trajectories. At multi-minute runtimes each, this is computationally expensive and slow.
Practical solutions:
Caching and replay: cache tool call responses so that evaluation runs can replay recorded trajectories quickly, without live API calls. This makes evaluation fast and deterministic, at the cost of not detecting regressions caused by external system changes.
Tiered evaluation: fast, automated checks for CI/CD (unit tests, lightweight outcome checks) and slower, comprehensive evaluation for weekly or release-level assessment.
Statistical efficiency: you do not need to evaluate on 10,000 examples to detect a 5% performance change. Power analysis can tell you the minimum sample size needed to detect a meaningful effect. Use it.
Evaluation datasets with long shelf lives: avoid evaluation examples that depend on current web content or rapidly changing facts. Focus on tasks that are stable: code that must pass tests, mathematical reasoning, structured data extraction.
What Good Evaluation Practice Looks Like
A production agent team I respect has this evaluation discipline:
- Every prompt or logic change triggers a CI run with 200 curated examples across task difficulty tiers.
- Weekly runs on the full 2,000-example evaluation set with human review of failure clusters.
- A dedicated "hard cases" set of 100 examples that the previous system generation could not solve — this tracks frontier progress.
- Monthly blind A/B evaluation where two annotators independently assess agent output quality on 50 live production examples.
- Automatic alerting when any metric drops more than 2% from the rolling 4-week average.
This is not glamorous. It is also what separates teams that are confidently improving their agents from teams that are optimistically guessing.
For a comprehensive breakdown of the five-dimensional evaluation framework used by leading production teams — covering task completion, cost efficiency, latency, robustness, and human alignment — see Beyond SWE-bench: The Emerging Landscape of AI Agent Evaluation Frameworks.
Agent evaluation is a first-class engineering discipline. Treat it that way.


