SWE-bench became the de facto benchmark for AI coding agents. It gave the community something concrete: here's a set of real GitHub issues, here's the fix, can your agent generate it? The approach was elegant in its simplicity — use the world's largest collection of already-solved software engineering problems as a test suite.
But SWE-bench only tells you one thing: can an agent solve a coding problem that has a known correct answer?
Production AI agents need to be evaluated on a dozen axes that SWE-bench doesn't touch: cost efficiency, latency, safety, robustness to adversarial inputs, graceful degradation, consistency across runs, and alignment with human preferences.
This is the hard problem that harness engineers are solving in 2026.
Why Agent Evaluation Is Fundamentally Different from Model Evaluation
Evaluating a language model is straightforward in principle: give it an input, compare output to ground truth, compute a metric. The evaluation is self-contained — it happens in isolation.
Evaluating an agent is evaluating a system, not a model. The agent's quality depends on:
- The tools available to it
- The order and way it uses those tools
- How it handles errors and recovers
- How it manages state across a multi-step task
- Whether it knows when to ask for human help
A single metric can never capture all of this. You need a multi-dimensional evaluation framework.
The Five Dimensions of Agent Evaluation
Dimension 1: Task Completion Rate
The most basic question: did the agent complete the task successfully?
This seems simple but gets complicated fast. "Success" isn't binary for most real-world tasks:
- Did it complete the task correctly? (quality)
- Did it complete it within budget? (efficiency)
- Did it complete it without causing harm? (safety)
- Did it complete it the way a human would have? (human alignment)
A task might be "mostly complete" — the agent did 90% of the work correctly but missed an edge case. Is that a pass or a fail?
Practical approach: Define success criteria for each task type as a composite of multiple sub-criteria. A customer support ticket might require: (1) correct intent classification, (2) accurate information provided, (3) no hallucinated policies, (4) appropriate escalation. All four must pass.
Dimension 2: Cost Efficiency
Every LLM call costs money. Every token has a price. For agents that make dozens or hundreds of tool calls per task, cost becomes a primary engineering concern.
Evaluate cost along multiple vectors:
- Cost per task: total spend divided by number of tasks
- Cost per success: total spend divided by number of successful completions
- Token efficiency: tokens used per task, segmented by input/output
- Model routing efficiency: are cheap models being used where appropriate?
The best agentic systems have intelligent model routing — using small, fast, cheap models for simple tasks and reserving large, capable, expensive models for complex tasks. Evaluating this routing strategy is part of the harness evaluation layer.
Dimension 3: Latency and Responsiveness
For interactive agents, latency is a UX concern. For autonomous agents, latency affects throughput. Either way, it matters.
Key latency metrics:
- P50/P95/P99 response time: end-to-end task completion time
- Time to first token: how quickly does the agent start responding?
- Tool call overhead: how much latency does each tool add?
- Context window pressure: does latency increase as sessions get longer?
Agents that work great in 5-turn conversations can degrade significantly at 50 turns due to context window pressure. Latency evaluation needs to cover the full task lifecycle.
Dimension 4: Robustness and Safety
This is where SWE-bench is weakest and production teams suffer most. Agents encounter:
- Malformed inputs: users who type nonsense, use wrong formats, provide contradictory requirements
- Adversarial inputs: users (or third parties) attempting to manipulate agent behavior
- Tool failures: external APIs going down, rate limits, malformed responses
- Context overflow: extremely long inputs, large file uploads, repeated content
An evaluation framework needs a comprehensive set of adversarial and edge-case scenarios. Leading teams maintain:
- Chaos test suites: randomly injected failures (network latency, API errors, rate limits)
- Adversarial input libraries: prompt injection attempts, jailbreak attempts, confusing inputs
- Boundary condition tests: maximum context length, maximum tool call count, maximum session duration
Dimension 5: Human Alignment and Preference
The hardest dimension to evaluate — does the agent do what a human would want it to do?
This isn't about correctness. A customer service agent might technically answer all questions correctly but in a way that feels cold and unhelpful. A code review agent might flag every style violation but miss the actual bugs.
Approaches to human alignment evaluation:
- LLM-as-judge: use a separate LLM to evaluate agent outputs against reference answers or human-written rubrics
- Human preference surveys: A/B test different agent versions and collect human feedback
- Proxy metrics: measure things that correlate with human preference (empathy indicators, clarity scores, conciseness)
The Evaluation Framework Stack
Production teams are building multi-layered evaluation stacks:
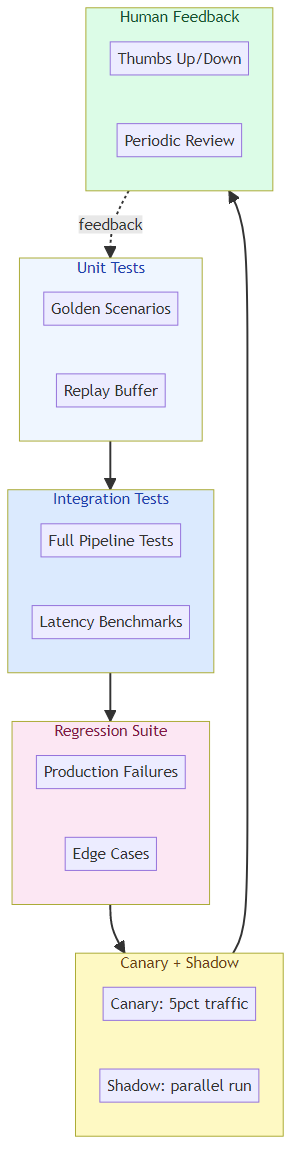
Layer 1: Unit Tests for Agents
The equivalent of traditional software unit tests — small, focused scenarios with known correct outputs.
Example: A data extraction agent should:
- Extract all fields from a well-formed invoice → expect exact field values
- Handle missing fields gracefully → expect partial extraction with nulls
- Reject clearly non-invoice documents → expect error, not hallucination
These tests run in CI/CD and block deployment on failure.
Layer 2: Integration Test Suites
Multi-step scenarios that exercise the full agent pipeline — from input through tool calls through state management to output.
Example: A research agent should:
- Search for relevant papers (web search tool)
- Download and parse PDFs (file tool)
- Extract key claims (code execution tool)
- Synthesize findings (LLM)
- Generate a report (output formatting)
Integration tests verify the full flow works, not just individual components.
Layer 3: Regression Suites
Every production failure becomes a regression test. When an agent fails in production, the first step (after recovery) is to add that failure scenario to the regression suite.
Over time, the regression suite becomes the most valuable part of the evaluation infrastructure — it encodes all the hard-won knowledge about failure modes.
Layer 4: Canary and Shadow Evaluations
Before deploying a new agent version to all users:
- Canary evaluation: serve 5% of traffic to the new version, compare metrics to baseline
- Shadow evaluation: run new version in parallel without acting on its output, compare outputs to baseline
This catches degradation before it affects all users.
Layer 5: Continuous Human Feedback
Automated evaluation can't catch everything. Build mechanisms for:
- User feedback buttons: thumbs up/down, "this was helpful / not helpful"
- Escalation flows: easy way for users to flag problematic outputs
- Periodic human review: randomly sample agent outputs for human review
- Preference A/B tests: run competing versions and measure user satisfaction
Evaluating Multi-Agent Systems
Multi-agent systems add another dimension of complexity. How do you evaluate:
- Coordination quality: are agents communicating effectively?
- Handoff correctness: are tasks being passed between agents correctly?
- Emergent behavior: are there unexpected interactions between agents?
- Cascading failures: does a failure in one agent propagate to others?
Evaluation approaches for multi-agent systems:
- End-to-end scenario tests: run complete multi-agent workflows with known correct outcomes
- Agent-level tracing: trace each agent's decisions independently, then analyze the interaction
- Synthetic scenario generation: programmatically generate multi-agent scenarios to test specific coordination patterns
- Chaos testing: inject failures in one agent and verify the system handles it gracefully
What Good Looks Like
The teams with the best agent evaluation infrastructure share common characteristics:
- Evaluation first: they define what "good" looks like before building capability
- Continuous evaluation: evaluation runs on every code change, not just before release
- Multi-dimensional metrics: they measure quality, cost, latency, and safety separately
- Human feedback integration: automated evaluation is supplemented with regular human review
- Regression discipline: every production failure becomes a test case
- Progressive deployment: new versions are validated before full rollout
The Uncomfortable Truth
SWE-bench is a useful benchmark. But benchmarks are not evaluation frameworks. A benchmark tells you whether you're improving on one axis. An evaluation framework tells you whether your system is production-ready.
Most AI agent teams are still operating on benchmark thinking: find a metric, improve the metric. Production reliability requires a fundamentally different approach: build systems that you can measure, understand, improve, and trust.
That's harness evaluation engineering. And it's one of the most valuable and undervalued skills in AI engineering today.
Related posts: Agent Benchmarking Beyond the Classics — building domain-specific evaluation frameworks. Agent Evaluation Metrics — metrics framework for AI agent performance. Agent Benchmarks: SWE-bench — the SWE-bench landscape.