A top-performing agent on SWE-bench can write code that fixes real GitHub issues. But it might fail catastrophically at drafting a customer service response for a product it has no knowledge of. A GAIA-benchmark superstar might struggle with a multi-step data analysis task that involves domain-specific terminology.
This is the fundamental gap between benchmark performance and real-world effectiveness. And it's why teams that rely on leaderboard scores to select agents often deploy systems that underperform in production.
The Benchmark Landscape
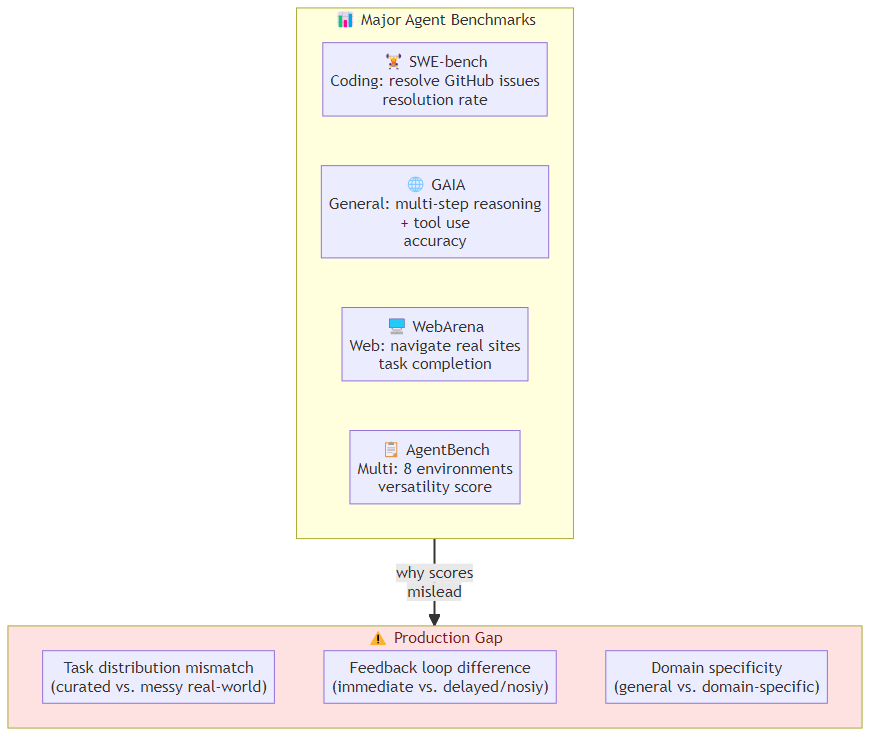
The major agent benchmarks each measure something different:
SWE-bench: agents write code to resolve GitHub issues. Tests coding ability, tool use, debugging. Dominated by models that can reason about code. Score: resolution rate.
GAIA: general AI assistant tasks — multi-step reasoning, tool use, and real-world problem solving across domains. Tests breadth. Score: accuracy.
WebArena: agents navigate and interact with real websites (Reddit, GitLab, etc.). Tests grounded web interaction. Score: task completion rate.
AgentBench: multi-dimensional evaluation across 8 environments (operating systems, databases, knowledge graphs, etc.). Tests versatility. Score: normalized score across environments.
WebShop: agents shop on a simulated e-commerce site. Tests instruction following and multi-step reasoning in a constrained environment. Score: match rate.
What these benchmarks share: they measure agents in controlled, reproducible environments with clear success criteria. What they don't measure: how the agent behaves when the domain shifts, the success criteria are ambiguous, or the environment is partially unknown.
The Gap Between Benchmark and Production
Three structural differences make benchmark performance a poor predictor of production performance:
1. Task Distribution Mismatch
Benchmarks use curated task distributions. SWE-bench has 12,000 carefully selected issues with ground-truth solutions. GAIA has hand-crafted tasks with known answers.
Production task distributions are messy. Customers ask things the benchmark authors never imagined. Edge cases cluster in ways that aren't representative of the training set.
A model that scores 60% on SWE-bench might outperform a 53% model in production if the 53% model was optimized specifically for SWE-bench task patterns while the 60% model generalizes better.
2. Feedback Loop Differences
Benchmarks provide immediate, deterministic feedback. The correct answer is known. The agent tries, succeeds or fails, and gets clear signal.
Production feedback is delayed, noisy, and sometimes absent. A customer service agent might never learn that its response was unhelpful. A code agent might not know that its solution introduced a subtle bug that won't surface for weeks.
This means: benchmark performance measures ceiling capability, not steady-state production quality.
3. Domain Specificity
Benchmarks test general capability. Production systems are domain-specific.
A customer service agent needs to:
- Handle ambiguous requests gracefully
- Know when to escalate vs. attempt an answer
- Maintain persona and tone consistency
- Correctly interpret product-specific terminology
- Know when it's making an assumption and flag it
None of these capabilities are tested by SWE-bench or GAIA. They require domain-specific evaluation.
The Domain-Specific Benchmark Framework
The solution: build benchmarks that reflect your production task distribution. Here's the framework:
Step 1: Task Inventory
Collect the full distribution of tasks your agent handles (or will handle). Don't sample — inventory. Every task type, even rare ones.
For each task type, document:
- What the agent is asked to do
- What a good answer looks like
- What the failure modes are
- What context is typically available vs. needs to be retrieved
Step 2: Success Criteria Definition
Define success criteria that are:
- Measurable: you can determine whether a given output meets the criteria
- Actionable: the criteria can drive automated evaluation
- Aligned: the criteria reflect actual user value, not proxy metrics
Common success criteria patterns:
- Task completion: did the agent achieve the stated goal?
- Output quality: does the output meet quality thresholds (accuracy, completeness, style)?
- Efficiency: did the agent achieve the goal within budget constraints?
- Safety: did the agent avoid producing harmful outputs?
Step 3: Evaluation Dataset Construction
For each task type, build a dataset of evaluation examples. Each example should have:
- Input (the task as the agent will receive it)
- Reference output (a correct or high-quality response)
- Constraints (what the agent should/shouldn't do)
- Success criteria (how to score the output)
Target: 20-50 examples per task type for reliable measurement. More for rare task types.
Step 4: Automated vs. Human Evaluation
Automated evaluation scales but misses nuance. Human evaluation catches quality issues but doesn't scale.
Automated evaluation works well for:
- Exact match tasks (did it produce the right answer?)
- Structural tasks (did it produce the right output format?)
- Metric tasks (how long, how many tokens, how many tool calls?)
Human evaluation is necessary for:
- Quality of prose and communication
- Appropriateness of tone and persona
- Handling of edge cases and ambiguity
- Trust and confidence calibration
A practical approach: use automated evaluation for fast iteration (can run 1000 tasks in an hour), use human evaluation for release gates (a sample of 20-50 tasks evaluated manually before production deployment).
Step 5: Composite Scoring
No single metric captures agent quality. Build a composite score that reflects what's actually important in your domain:
Production Score = w1 × Task Completion Rate
+ w2 × Quality Score (human eval)
+ w3 × Cost Efficiency (cost per task)
+ w4 × Safety Score (harmful output rate)
+ w5 × Escalation Rate (human handoff %)
Weights (w1-w5) should reflect your production priorities. A customer service agent might weight quality and safety high. A code generation agent might weight task completion and cost efficiency high.
Benchmarking Over Time
Agent performance isn't static — it changes as you update prompts, add tools, change models, or update the knowledge base.
Build a continuous benchmarking pipeline:
- Daily smoke tests: run a small set of critical tasks to catch regressions
- Weekly evaluation: run the full benchmark suite (automated) to track trends
- Monthly deep evaluation: human-evaluated sample of production tasks to check for quality drift
The key signals to track:
- Score trend over time (is the agent improving or degrading?)
- Failure mode distribution (are new failure types emerging?)
- Cost trend (is the agent getting more or less expensive per task?)
- Quality drift (do human evaluators notice declining quality?)
The Bottom Line
SWE-bench tells you how an agent performs on a specific type of coding task. It doesn't tell you how it will handle your customer complaints, your product returns, or your data analysis requests.
The teams that deploy reliable agents build domain-specific benchmarks that reflect their actual task distribution, success criteria, and failure modes. They use composite scores that capture what's actually important in production. And they run continuous evaluation pipelines to catch drift before users do.
Benchmark performance is a starting point, not a destination. Use it to narrow your options, then use domain-specific evaluation to make the final call.
Related posts: AI Agent Evaluation Framework — measuring agent quality and reliability. Multi-Agent Coordination Protocols — evaluating multi-agent system quality. AI Agent Harness Engineering — building the evaluation harness.