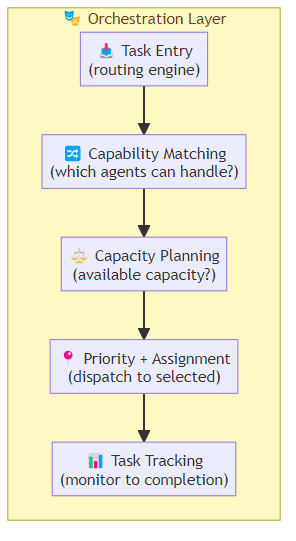
A research agent needs to analyze data, write code, and produce a report. You could build one super-agent that does all three — or you could build three specialized agents that work together. The multi-agent approach is more robust, more scalable, and more aligned with how real organizations work.
But it introduces coordination challenges that don't exist in single-agent systems: how do agents know when to hand off? How do they avoid duplicating work? How do they resolve conflicts? How do they recover when one agent fails?
This is the multi-agent coordination problem. And it's where agentic engineering gets interesting.
Why Multi-Agent Systems?
Before diving into coordination, it's worth being clear about why multi-agent systems make sense:
Specialization: a research agent that excels at finding information isn't necessarily the best at writing clear prose. Specialized agents can be optimized independently for their specific task.
Scalability: a research task that would take one agent 30 minutes can often be split across 5 agents working in parallel, completing in 6 minutes.
Robustness: if one agent fails, the others can continue. A single-agent system fails completely when it fails.
Natural domain mapping: real-world workflows involve different expertise areas. Multi-agent systems map naturally to these workflows — a research workflow has a data analyst, a writer, and a reviewer, each a distinct agent.
The Coordination Patterns
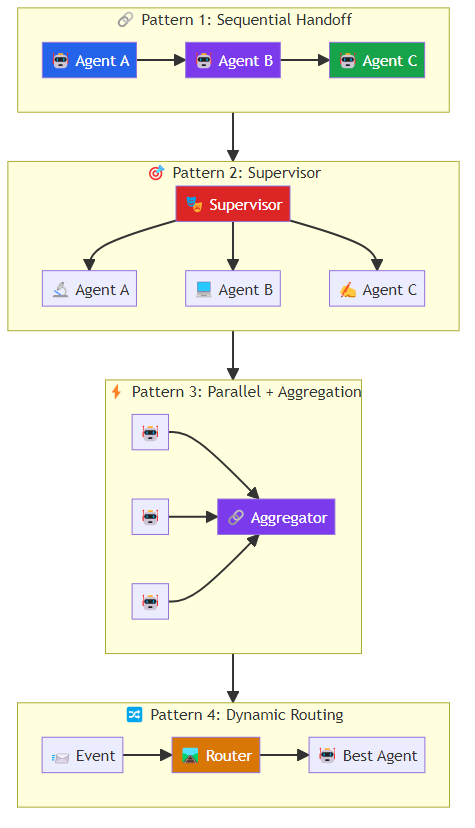
Pattern 1: Sequential Handoff (Pipeline)
The simplest pattern: Agent A does its task, hands the output to Agent B, which hands to Agent C, and so on.
Use case: Linear workflows where each step depends on the previous step's output. Example: research → analysis → report writing → review.
Pros: Simple to implement, clear dependencies, easy to debug.
Cons: Slow (can't parallelize), failure of any agent stops the pipeline.
Agent A → Agent B → Agent C → Agent D
Pattern 2: Supervisor Pattern (Centralized Orchestration)
A central supervisor agent receives the task, decomposes it, assigns subtasks to specialized agents, collects results, and synthesizes the final output.
Use case: Complex tasks with multiple subtasks that need to be coordinated by a central authority. Example: a supervisor that assigns coding, testing, and documentation to specialized agents.
Pros: Centralized control, clear authority, handles complex task decomposition.
Cons: Supervisor becomes a bottleneck, single point of failure, requires sophisticated supervisor logic.
┌──→ Agent B
│
Supervisor ──→ Agent C
│
└──→ Agent D
Pattern 3: Parallel Execution with Aggregation
Multiple agents work on independent subtasks simultaneously, then their results are aggregated into a final output.
Use case: Tasks that can be decomposed into independent parallel work. Example: analyze 10 documents simultaneously, then synthesize findings.
Pros: Maximum parallelism, fast completion, scales well.
Cons: Result aggregation is non-trivial, agents may produce redundant or conflicting outputs.
Agent A ─┐
Agent B ─┼──→ Aggregator ─→ Output
Agent C ─┘
Pattern 4: Dynamic Routing (Event-Driven)
Agents don't have fixed roles — they respond to events and messages, routing work to whoever is best suited to handle it.
Use case: Open-ended tasks where the right agent for the job isn't known in advance. Example: a customer service system that routes to specialized agents based on issue type.
Pros: Highly flexible, adapts to task requirements dynamically.
Cons: Complex to implement, hard to predict behavior, requires sophisticated routing logic.
Event → Router → Best Agent → Response
The Communication Protocols
Agents need to communicate. The protocol they use determines how information flows, how conflicts are resolved, and how the system handles failures.
Shared State Communication
Agents communicate through a shared state store — a database, a message queue, a shared knowledge graph. Agent A writes to the store, Agent B reads from it.
Best for: Asynchronous coordination, persistent state, audit trails.
Challenges: Consistency (can agents read stale state?), contention (multiple agents writing simultaneously), and serialization (how to combine concurrent writes).
Direct Messaging
Agents send messages directly to other agents via a message bus. The sender knows the recipient — the message is delivered directly.
Best for: Synchronous communication, tight coupling, real-time coordination.
Challenges: Tight coupling makes agents fragile to changes, message routing complexity, no central record of communication.
Broadcast/Publish-Subscribe
Agents publish messages to topics. Other agents subscribe to topics of interest and receive relevant messages.
Best for: Decoupled systems, event-driven coordination, fan-out patterns.
Challenges: Message routing can be complex, agents may receive irrelevant messages, subscription management overhead.
The Handoff Problem
When one agent hands off work to another, critical information must be transferred:
- Context: what does the receiving agent need to understand what happened so far?
- State: what is the current state of the task?
- Intent: what was the original goal and what remains?
- Constraints: what boundaries should the receiving agent respect?
Poor handoffs are the most common source of multi-agent failures. An agent that summarizes its work too aggressively loses critical context. One that summarizes too little overwhelms the receiving agent with noise.
Effective handoff protocols include:
- Structured handoff documents: templates that ensure all critical information is included
- Bidirectional verification: the receiving agent confirms understanding before the sending agent releases the task
- Progressive detail: handoff starts with a summary, with details available on demand
Conflict Resolution
When multiple agents have conflicting information or priorities, the system needs a conflict resolution mechanism:
Authority-based: a designated agent (usually the supervisor) has final say in conflicts. Simple but can be a bottleneck.
Consensus-based: agents negotiate and agree on a resolution. Slow but produces buy-in.
Priority-based: pre-defined priorities determine which agent's view prevails. Fast but requires careful priority design.
Evidence-based: conflicts are resolved by examining evidence — the agent with stronger evidence (more citations, more recent data, higher confidence) wins. Requires a shared evidence evaluation framework.
Failure Modes and Recovery
Multi-agent systems have failure modes that don't exist in single-agent systems:
Failure Mode 1: Cascade Failure
One agent's failure causes another to fail, which causes another to fail. Example: a writer agent fails because the research agent didn't deliver results, which causes the reviewer to have nothing to review.
Mitigation: Implement timeout and fallback strategies. If the research agent doesn't respond within 60 seconds, use cached research or proceed with partial information.
Failure Mode 2: Deadlock
Agents wait for each other in a circular dependency. Agent A is waiting for Agent B's output, Agent B is waiting for Agent C, and Agent C is waiting for Agent A.
Mitigation: Implement timeout on all waits. If an agent has been waiting for more than N seconds, escalate to a supervisor or terminate the dependent task.
Failure Mode 3: Infinite Loop
Agents keep cycling through the same interactions without making progress. Example: a writer agent keeps revising based on analyst feedback, analyst keeps providing new feedback on the revisions.
Mitigation: Track iteration counts and convergence metrics. If iterations exceed a threshold or progress metrics plateau, terminate and return a partial result.
Failure Mode 4: Propagation of Errors
An incorrect output from one agent propagates through the system and contaminates downstream results.
Mitigation: Validation checkpoints between agents. Before Agent B starts work based on Agent A's output, validate that output meets quality thresholds.
Designing for Coordination
The key insight in multi-agent system design: the coordination layer is as important as the agents themselves.
Before building a multi-agent system, define:
- Communication protocol: how agents exchange information
- Handoff contracts: what information must be transferred at each handoff
- Conflict resolution strategy: how disagreements are settled
- Failure recovery plan: what happens when an agent or link fails
- Observability requirements: how to trace what each agent did and why
The coordination layer is where multi-agent systems succeed or fail. A system with sophisticated agents but poor coordination will produce unreliable, unpredictable results.
The Bottom Line
Multi-agent coordination is the problem that separates working multi-agent systems from broken ones. The patterns — pipeline, supervisor, parallel, dynamic — each have their place. The protocols — shared state, direct messaging, pub-sub — each have tradeoffs.
The key is to design the coordination layer with the same rigor you apply to the agents themselves. Define the protocols before you build the agents. Implement handoff contracts. Build in failure recovery. Make the coordination observable.
Because ultimately, a multi-agent system is only as good as the coordination that binds it together.
Related posts: Multi-Agent Orchestration Patterns — orchestration strategies for multi-agent systems. Multi-Agent Systems in the Enterprise — enterprise deployment considerations. Agent Communication Protocols — technical communication mechanisms.