The appeal of multi-agent systems is obvious: divide a complex task among specialized agents, run them in parallel where possible, and aggregate their outputs into something better than any single agent could produce. The reality is more nuanced. Multi-agent systems introduce coordination overhead, failure propagation risks, and debugging complexity that can easily outweigh the benefits — unless you choose the right orchestration pattern for your specific workload.
I want to walk through the patterns I have seen work in practice, the tradeoffs each carries, and the conditions under which each one earns its complexity.
Why Single Agents Break Down
Before justifying the multi-agent overhead, it is worth being precise about where single agents fail.
Context window limits: Even with 200K token context windows, long-horizon tasks — code refactors spanning a large codebase, multi-document research synthesis, extended agentic workflows — will exceed what fits in a single context. You either truncate (losing information) or externalize (requiring architecture).
Skill specialization: A generalist agent prompted to do everything does nothing particularly well. A coding agent fine-tuned on code reviews outperforms a general-purpose model on that specific task. Specialization is real, and it requires routing.
Parallelism: Sequential reasoning is a bottleneck. If three subtasks are independent, running them in parallel with separate agents reduces end-to-end latency by a factor of three.
Reliability through redundancy: For high-stakes decisions, running multiple agents and aggregating their outputs (ensembling, debate, majority vote) produces more reliable results than a single pass.
Pattern 1: The Supervisor-Worker Hierarchy
The most intuitive multi-agent pattern is hierarchical: an orchestrator agent receives the high-level task, decomposes it, delegates subtasks to specialized worker agents, and synthesizes the results.
Frameworks like LangGraph make this pattern straightforward to implement. A supervisor is constructed by supplying it with a list of worker agents — a research agent, a code agent, a writer agent — and instructing it to delegate tasks to whichever specialist is best positioned to handle them. The supervisor's decisions are explicit; every delegation is a loggable, traceable event.
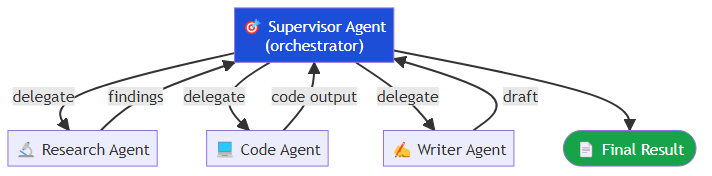
When it works: tasks with clear subtask decomposition, where the supervisor can reliably identify which agent to call.
When it fails: when the supervisor model is not strong enough to make good decomposition decisions, or when the subtasks are so interdependent that the supervisor becomes a bottleneck re-routing information back and forth.
Key insight: the supervisor's prompt is as important as the worker agents' capabilities. A poorly prompted supervisor will route tasks incorrectly and cascade errors through the entire pipeline. I have seen production systems fail not because the worker agents were weak but because the supervisor prompt was underspecified.
Pattern 2: Peer-to-Peer Agent Conversation (the AutoGen Model)
Microsoft's AutoGen framework popularized a different topology: agents as conversational peers that talk to each other directly, without a central orchestrator. A UserProxyAgent represents the human or the automated test harness; an AssistantAgent does the reasoning; additional specialized agents join the conversation as needed.
In AutoGen, you define each agent's role and configure it independently — an assistant, a code executor that can actually run code in a sandboxed directory, and a critic whose sole brief is to identify flaws in the assistant's output. The agents then converse with one another, with the conversation bounded by a maximum number of turns to prevent runaway loops.
The conversational model is powerful for iterative refinement — one agent proposes, another critiques, the first revises. This maps naturally onto human workflows like code review, academic peer review, and editorial cycles.
When it works: open-ended tasks where the right decomposition is not known upfront, creative tasks benefiting from critique-and-revise cycles, debugging scenarios.
When it fails: when conversations diverge and agents talk past each other (verbose, expensive, and circular), or when there is no termination condition and the system runs indefinitely. Always set max_turns and implement an explicit completion signal.
Pattern 3: Parallelism via Map-Reduce
For tasks that are naturally parallelizable — processing a list of documents, running multiple research queries, evaluating a dataset — the map-reduce pattern is both simple and effective.
LangGraph's Send primitive makes this clean. A map step fans out by dispatching each document in a batch to an independent worker agent, each carrying the document and the task specification. Once all workers complete, a reduce step collects their results and passes them to a synthesis function that aggregates the individual outputs into a coherent whole.
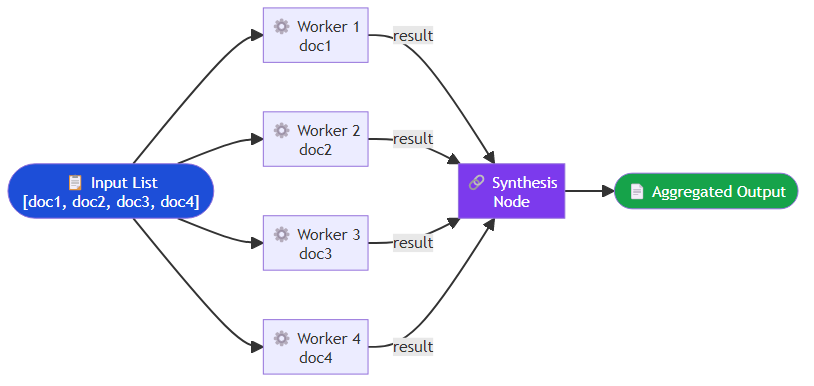
The critical design decision is the reduce step. Simple concatenation rarely produces a good final output. You need an aggregation strategy: a synthesis agent that reads all worker outputs, a voting mechanism for classification tasks, or a structured merge for data extraction tasks.
Pattern 4: Debate and Ensemble
For high-stakes decisions — medical triage, legal analysis, financial recommendations — running multiple agents independently and then having them debate or vote produces more reliable outputs than any single agent.
The LLM debate pattern (Du et al., 2023) shows that agents updating their responses in light of other agents' reasoning outperforms single-agent answers on reasoning benchmarks. The implementation is simple: run N agents independently on the same prompt, then run a final round where each agent sees the others' outputs and is asked to revise.
When it works: factual questions with verifiable answers, high-stakes classification decisions, any task where overconfidence in a single model output is a risk.
When it fails: when all agents share the same blind spots (same base model, same training data). Ensemble benefits require genuine diversity — different models, different prompting strategies, or different information sources.
Pattern 5: Specialized Pipeline (DAG-Based)
Some tasks are best modeled as a directed acyclic graph of specialized agents, each transforming the state and passing it to the next. This is less dynamic than a supervisor-worker system but more reliable and easier to test.
A research pipeline might follow this sequence: a Query Expander agent reformulates and broadens the input query, a Web Retriever fetches relevant documents, a Fact Checker validates claims against sources, a Summarizer condenses the verified content, and a Formatter presents the output in the required structure.
Each node is a specialized agent (or a simple function). The state flows through deterministically. You can unit-test each node in isolation and integration-test the full pipeline.
When it works: well-understood, repeatable workflows. Document processing, data extraction, report generation.
When it fails: tasks requiring dynamic task decomposition, where the pipeline structure itself depends on the input.
Operational Considerations
Multi-agent systems are not just an inference problem — they are a systems engineering problem.
Observability: Every agent call needs to be traced, with inputs, outputs, latency, and cost logged. LangSmith, Arize Phoenix, and custom OpenTelemetry instrumentation all work. Without this, debugging a failure in a five-agent pipeline is a nightmare.
Cost accounting: In a hierarchical system, the supervisor calls consume tokens, the worker calls consume tokens, and the final synthesis call consumes tokens. Model the total cost before building. A system that routes everything through GPT-4o at every level is 5-10x more expensive than a system that uses a smaller model for routing and simple tasks.
Failure propagation: Decide upfront what happens when a worker agent fails. Does the supervisor retry? Skip that subtask? Fall back to a simpler strategy? These decisions need to be encoded in the orchestration logic, not discovered at 2 AM during an incident.
State management: As agent count grows, shared state becomes a liability. Prefer immutable state with explicit versioning. Each agent receives a snapshot of the state and returns a delta; the orchestrator merges deltas. This makes rollback and replay possible.
Choosing the Right Pattern
Here is my decision heuristic:
- Known, stable decomposition → DAG pipeline
- Dynamic decomposition → Supervisor-worker
- Iterative refinement → Peer-to-peer conversation
- Parallelizable subtasks → Map-reduce
- High-stakes decisions → Ensemble/debate
Most real systems combine multiple patterns. A document processing pipeline might use a DAG for the main flow but invoke a peer-to-peer debate pattern for ambiguous classification decisions within one of its nodes.
The teams that succeed with multi-agent systems are not the ones with the most sophisticated architectures. They are the ones who instrument everything, start simple, and add complexity only where benchmarks show it is necessary. Multi-agent orchestration is a powerful tool. It is also a very effective way to multiply your debugging surface area.
Start with one agent. Add a second when you can prove you need it.
Related posts: Multi-Agent Coordination Protocols — communication protocols, handoff contracts, and failure recovery. Multi-Agent Systems in the Enterprise — enterprise deployment considerations. Agent Communication Protocols — technical communication mechanisms.


